
Research
The members of WDSI are active researchers in a wide variety of fields relating to data. Here are just a few examples.
Discovering and explaining problems in brain imaging inference
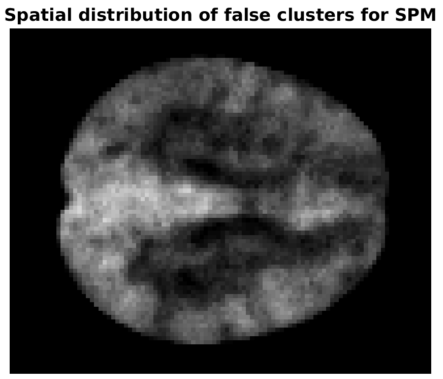
Techniques like Magnetic Resonance Imaging (MRI) have revolutionised our understanding of the brain but depend critically on statistical methods to control false positives. With 50,000+ tests conducted in each experiment, there is massive multiple testing problem that needs to be addressed. Prof. Nichols has worked his entire career evaluating existing and building new methods that are sensitive yet offer precise control of the risk of false alarms. In his most recent work with colleagues from Sweden, they used a large scale evaluation using real functional MRI (fMRI) data collected while subjects are resting, performing no task. Submitting this resting fMRI data to analysis software intended for task fMRI, where different behavioral or cognitive conditions are usually compared, they were able to measure the actual false positive rate without making restrictive assumptions on the spatial or temporal noise structure. While some standard inference tools worked fine, one common variant had extremely inflated familywise false positive rates, as high as 70% when 5% was expected. Crucially, they tracked down the problem to violations of the assumed spatial covariance function and an assumption of stationarity. These results created a stir in the neuroimaging community and brought renewed attention to empirical validation of analysis tools.
Eklund, A., Nichols, T. E., & Knutsson, H. (2016). Cluster failure: Why fMRI inferences for spatial extent have inflated false-positive rates. Proceedings of the National Academy of Sciences of the United States of America, 113(28), 7900–5. http://doi.org/10.1073/pnas.
Private data release via Bayesian networks

Privacy-preserving data publishing is an important problem that has been the focus of extensive study. Existing techniques using differential privacy, however, cannot effectively handle the publication of high-dimensional data. In particular, when the input dataset contains a large number of attributes, existing methods require injecting a prohibitive amount of noise compared to the signal in the data, which renders the published data next to useless. To address the deficiency of the existing methods, we develop PrivBayes, a differentially private method for releasing high-dimensional data. Given a dataset D, PrivBayes first constructs a Bayesian network N, which (i) provides a succinct model of the correlations among the attributes in D and (ii) allows us to approximate the distribution of data in D using a set P of low-dimensional marginals of D. After that, PrivBayes injects noise into each marginal in P to ensure differential privacy, and then uses the noisy marginals and the Bayesian network to construct an approximation of the data distribution in D. Finally, PrivBayes samples tuples from the approximate distribution to construct a synthetic dataset, and then releases the synthetic data. Intuitively, PrivBayes circumvents the curse of dimensionality, as it injects noise into the low-dimensional marginals in P instead of the high-dimensional dataset D. Private construction of Bayesian networks turns out to be significantly challenging, and we introduce a novel approach that uses a surrogate function for mutual information to build the model more accurately.
G. Cormode, M. Procopiuc, D. Srivastava, X. Xiao, and J. Zhang. Privbayes: Private data release via bayesian networks. In ACM SIGMOD International Conference on Management of Data (SIGMOD), 2014.
The controlled thermodynamic integral
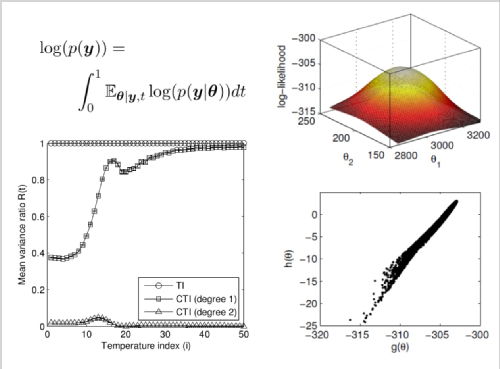
Bayesian model comparison relies upon the model evidence, yet for many models of interest the model evidence is unavailable in closed form and must be approximated. Many of the estimators for evidence that have been proposed in the Monte Carlo literature suffer from high variability. Oates, Papamarkou and Girolami recently proposed the “controlled thermodynamic integral” approach to estimate the model evidence. In many applications the controlled thermodynamic integral offers a significant and sometimes dramatic reduction in estimator variance.
Oates CJ, Papamarkou T, Girolami M. The Controlled Thermodynamic Integral for Bayesian Model Comparison, to appear in J. Am. Stat. Assoc.
On the exact and epsilon-strong simulation of (jump) diffusions
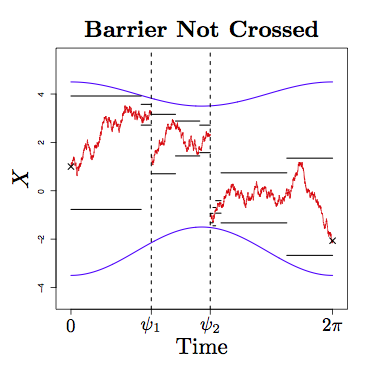
Retrospective Monte Carlo is a method in which the complexity of an algorithm can be reduced by simple algorithmic step re-ordering. For instance, and as shown in the accompanying picture, it is possible to apply Retrospective Monte Carlo to ascertain with certainty whether an infinite dimensional random variable (in this case a jump diffusion sample path coloured red), crosses some two sided non-linear barrier (in blue), using only a finite dimensional representation of the sample path (upper and lower bounds in black). Applications for this work can be found in finance and biology among many other fields.
M. Pollock, A. M. Johansen and G. O. Roberts. On the Exact and epsilon-Strong Simulation of (Jump) Diffusions. Bernoulli (Forthcoming).
Riemann manifold Langevin and Hamiltonian Monte Carlo
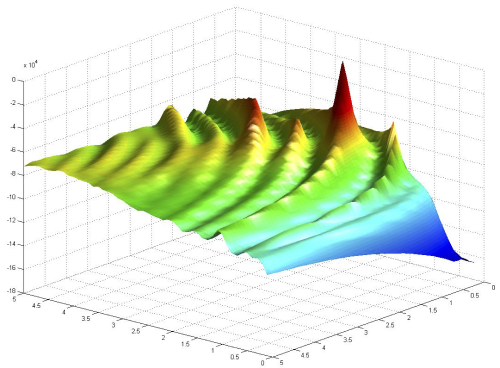
The induced posterior distribution from a two-parameter model of a kinetic ordinary differential equation (ODE) model of a Circadian Clock gene regulation. The ridges indicate posterior mass associated with solutions of the ODE that induce limit-cycles of similar phase and amplitude to that of the measured data. This presents a major challenge to existing simulation-based posterior inference methods and motivates much of our work in differential geometric Markov chain methods
Girolami, M., Calderhead, B., Riemann Manifold Langevin and Hamiltonian Monte Carlo Methods (with discussion), Journal of the Royal Statistical Society – Series B, 73(2), 123 - 214, 2011.
Hemisphere-wide species distributions from massively crowdsourced eBird data
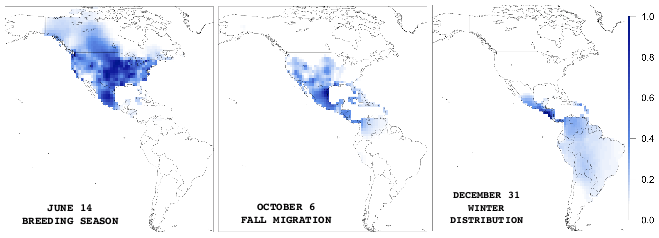
Broad-scale spatiotemporal processes in conservation and sustainability science, such as continent-wide animal movement, occur across a range of spatial and temporal scales. Understanding these processes at multiple scales is crucial for developing and coordinating conservation strategies across national boundaries. In this project, in collaboration with the Cornell Lab of Ornithology, we develop a general class of supervised learning models we call AdaSTEM, for Adaptive Spatio-TemporalExploratory Models, that are able to exploit variation in the density of observations while adapting to multiple scales in space and time. We show that this framework is able to efficiently discover multiscale structure when it is present, while retaining predictive performance when absent. We deploy AdaSTEM to estimate the spatiotemporal distribution of Barn Swallow (Hirundo rustica) across the Western Hemisphere using massively crowdsourced eBird data that has been collected by citizen scientists.
D Fink, T Damoulas, J Dave, Adaptive Spatio-Temporal Exploratory Models: Hemisphere-wide species distributions from massively crowdsourced eBird data, 27th AAAI Conference on Artificial Intelligence (AAAI 2013)
Quantifying alternative splicing from paired-end RNA-seq data
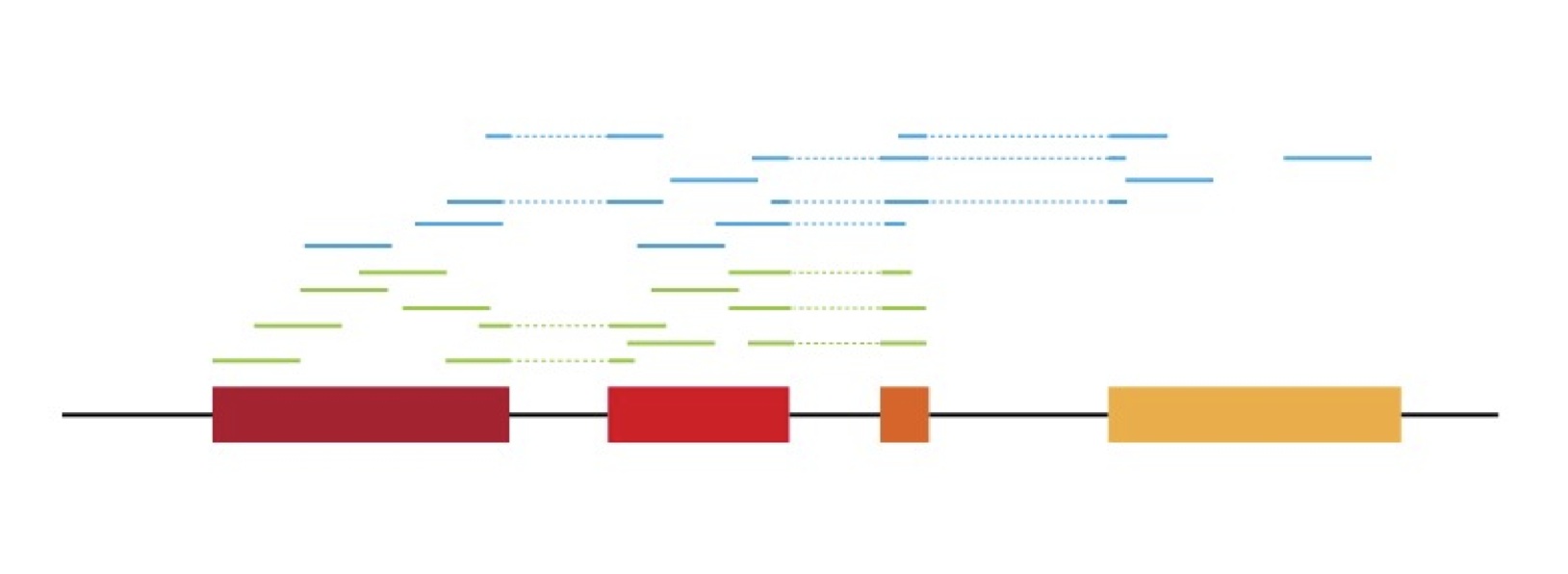
The casper software package infers alternative splicing patterns from paired-end RNA-seq data.
Rossell D., Stephan-Otto Attolini C., Kroiss M., Stöcker A. (2014) Quantifying alternative splicing from paired-end RNA-seq data. Annals of Applied Statistics, 8:1, 309-330.
See Bioconductor package casper.
Divide and conquer with sequential Monte Carlo
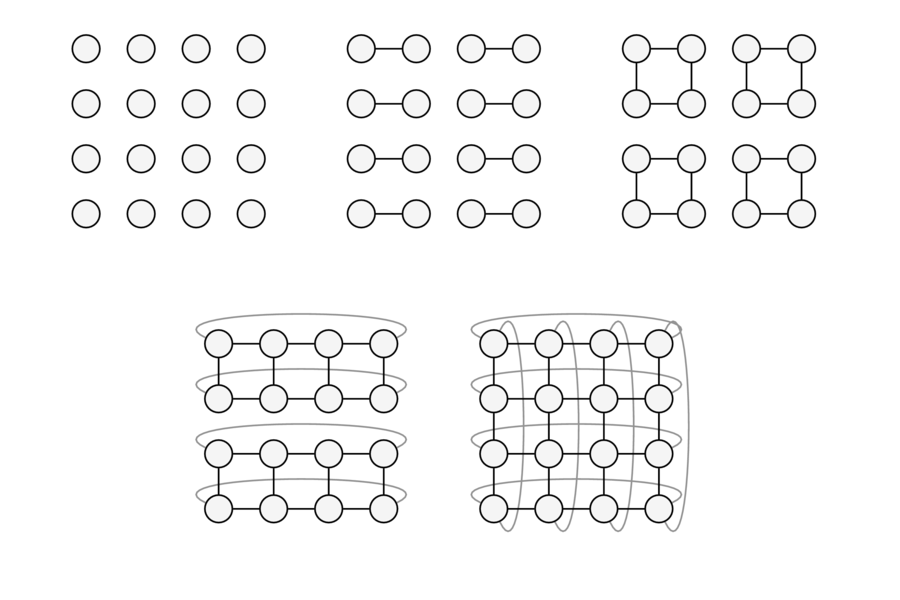
Many problems involving large quantities of data also involve large models. One challenge is developing computational algorithms which scale in this paradigm, particularly in settings in which the number of unknowns is comparable to the number of observations. The approach described in:
F. Lindsten, A. M. Johansen, C. Naesseth, B. Kirkpatrick, T. Schön, J. A. D. Aston, and A. Bouchard-Côté. Divide and conquer with sequential Monte Carlo. ArXiv mathematics preprint 1406.499, 2014.
Works by a recursive decomposition technique which turns one very difficult inferential problem in to a series of more tractable ones, addressing each with well-established Monte Carlo techniques.
Dynamic filtering of Static Dipoles in MagnetoEncephaloGraphy
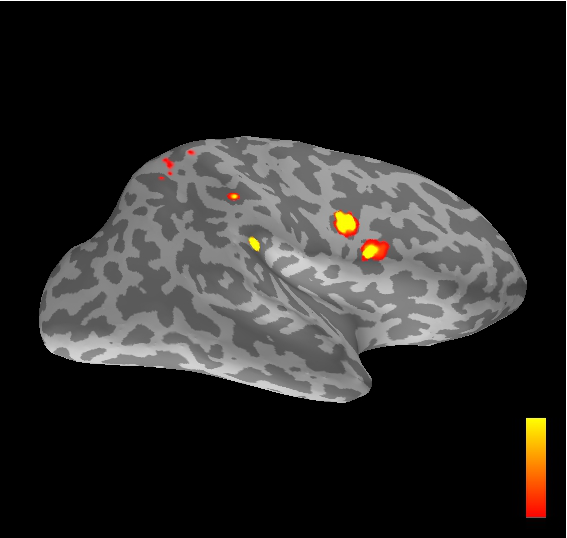
Converting noisy brain-imaging signals into meaningful estimates of activity within the brain throughout the course of the measurement period is a major big-data challenge and one which has attracted a great deal of attention. This image shows an estimate of activity at a single time instant obtained from real magnetoencephalography data using the technique developed in:
A. Sorrentino, A. M. Johansen, J. A. D. Aston, T. E. Nichols and W. S. Kendall. Dynamic filtering of Static Dipoles in MagnetoEncephaloGraphy. Annals of Applied Statistics, 7(2):955-988, 2013.
Accurate identification of digital genomic footprints from DNase-seq data
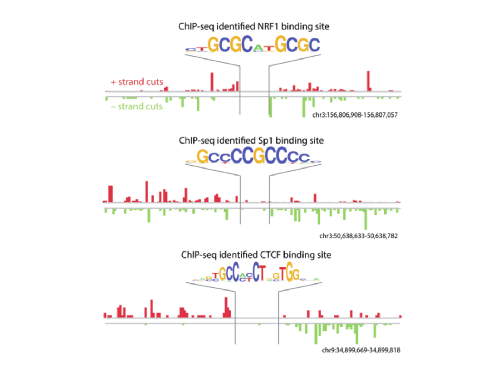
Example DNase-seq data at three loci in the human genome showing that protein binding sites for a variety of different proteins can be discovered by this single assay. The pattern seen – including an interval with very few reads – is termed ‘footprint’. We developed a method to detect these and published it here:
Jason Piper, Markus Elze, Pierre Cauchy, Peter Cockerill, Constanze Bonifer, Sascha Ott. Wellington: a novel method for the accurate identification of digital genomic footprints from DNase-seq data. Nucleic Acids Research, 2013
The following paper shows an example of using footprinting to study aberrant gene regulation in cancer:
Anetta Ptasinska, Salam A Assi, Natalia Martinez-Soria, Maria Rosaria Imperato, Jason Piper, Pierre Cauchy, Anna Pickin, Sally R James, Maarten Hoogenkamp, Dan Williamson, Mengchu Wu, Daniel G Tenen, Sascha Ott, David R Westhead, Peter N Cockerill, Olaf Heidenreich, Constanze Bonifer. Identification of a dynamic core transcriptional network in t(8;21) AML regulating differentiation block and self-renewal. Cell Reports, in press.
Playing Russian roulette with intractable likelihoods
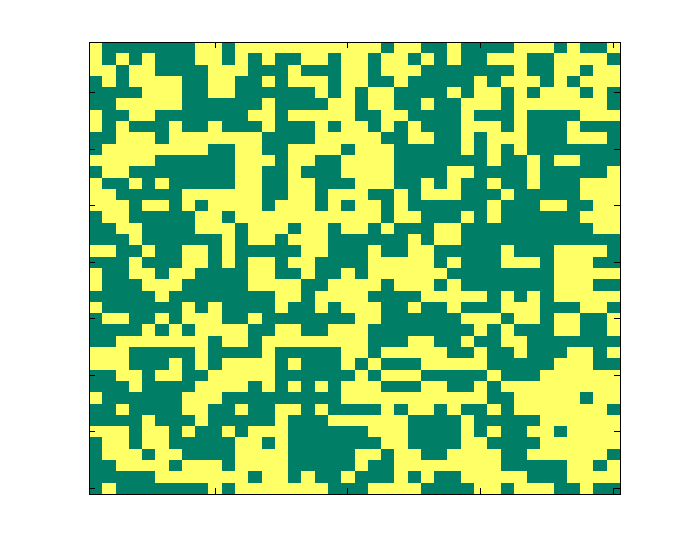
Many distributions modelling spatial dependencies have an intractable normalising term which is a function of the parameters. This means that samples cannot be drawn from the posterior distribution of the parameters using standard MCMC techniques such as Metropolis-Hastings. Our approach makes use of pseudo-marginal MCMC (Andrieu and Roberts, 2009) in which an unbiased estimate of the target distribution is used in the acceptance ratio and the chain still targets the desired posterior distribution. To achieve the unbiased estimate, we suggest expanding the likelihood as an infinite series in which each term can be estimated unbiasedly, and then truncating the infinite series unbiasedly so that only a finite number of estimates need be obtained. Results for the posterior distribution of an Ising model parameter are shown.
Girolami, Mark, Anne-Marie Lyne, Heiko Strathmann, Daniel Simpson, and Yves Atchade. Playing Russian roulette with intractable likelihoods.
Exploiting Molecular Dynamics in Nested Sampling Simulations of Small Peptides
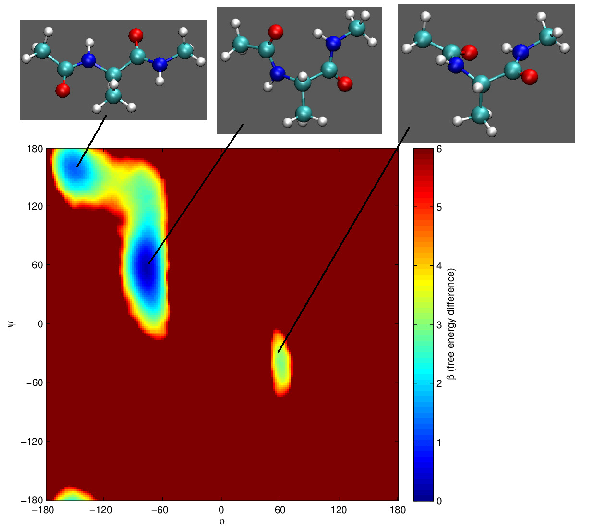
Nested Sampling (NS) is a parameter space sampling algorithm which can be used for sampling the equilibrium thermodynamics of atomistic systems. NS has previously been used to explore the potential energy surface of a coarse-grained protein model and has significantly outperformed parallel tempering when calculating heat capacity curves of Lennard-Jones clusters. The original NS algorithm uses Monte Carlo (MC) moves; however, a variant, Galilean NS, has recently been introduced which allows NS to be incorporated into a molecular dynamics framework, so NS can be used for systems which lack efficient prescribed MC moves. We have demonstrated the applicability of Galilean NS to atomistic systems and developed an implementation of Galilean NS using the Amber molecular dynamics package.
Burkoff, N. S., Baldock, R. J., Várnai, C., Wild, D. L., & Csányi, G. (2016). Exploiting molecular dynamics in Nested Sampling simulations of small peptides. Computer Physics Communications, 201, 8-18.
Predicting the future Arctic vegetation distribution under different Climate Change scenarios
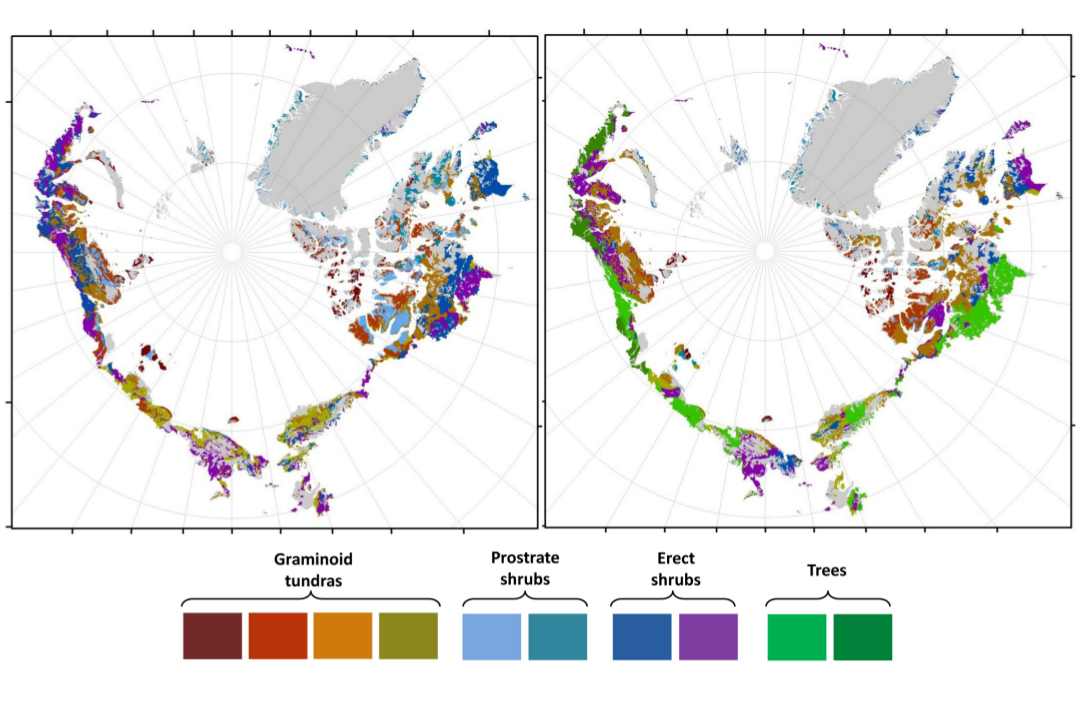
Climate warming has led to changes in the composition, density and distribution of Arctic vegetation in recent decades. These changes cause multiple opposing feedbacks between the biosphere and atmosphere, the relative magnitudes of which will have globally significant consequences but are unknown at a pan-Arctic scale. The precise nature of Arctic vegetation change under future warming will strongly influence climate feedbacks, yet Earth system modelling studies have so far assumed arbitrary increases in shrubs (for example, +20%), highlighting the need for predictions of future vegetation distribution shifts. In this project we show, using climate scenarios for the 2050s and models that utilize statistical associations between vegetation and climate, the potential for extremely widespread redistribution of vegetation across the Arctic. We predict that at least half of vegetated areas will shift to a different physiognomic class, and woody cover will increase by as much as 52%. By incorporating observed relationships between vegetation and albedo, evapotranspiration and biomass, we show that vegetation distribution shifts will result in an overall positive feedback to climate that is likely to cause greater warming than has previously been predicted. Such extensive changes to Arctic vegetation will have implications for climate, wildlife and ecosystem services.
RG Pearson, SJ Phillips, MM Loranty, PSA Beck, T Damoulas, SJ Knight, Scott J Goetz, Shifts in Arctic vegetation and associated feedbacks under climate change, Nature Climate Change, 3:7, 673-677, 2013. Front Cover.
L-Functions and Modular Forms Database
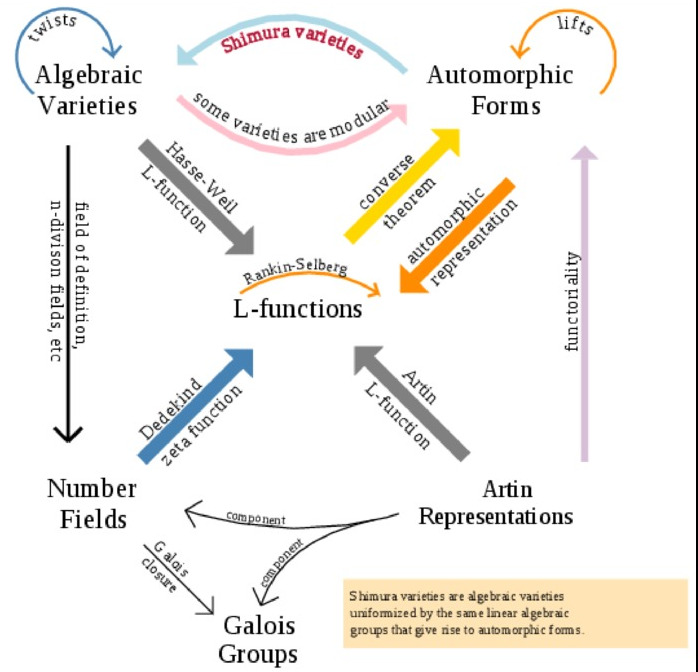
Over the last five years the elliptic curve database project has become part of a much large world-wide research project called the L-Functions and Modular Forms Database (LMFDB) which was originally funded by a $1.2M US NSF FRG grant, and since 2013 is funded by an EPSRC Programme Grant worth £2.2M, shared between Bristol and Warwick, of which John Cremona is the PI. As well as Bristol and Warwick, the project has a large international team of collaborators.
The project consists of a large database, hosted at Warwick, containing a substantial amount of number-theoretical data (for example including over 100 billion zeros of the Riemann Zeta Function, each to 100-bit precision), allowing different views of the data and showing clearly the links between different mathematical objects, some of which are still only conjectural and all of which are the subject of a large amount of research worldwide. As well as new mathematical theory, the project involves much algorithmic development, realised and implemented entirely as open source software, so that both the data and the code used to create it and display it is all fully open.
Parallel and distributed sequential Monte Carlo
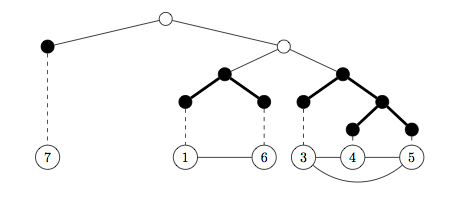
Particle filters are commonly used interacting particle algorithms for facilitating statistical inference for time series data, and are particularly suited to parallel computation on many-core devices. As the length or complexity of the time series grows, however, the number of particles required to maintain a given level of accuracy also grows and so one may not be able to perform the computation for all the particles on a single device. This naturally invites distributed implementations of the methodology, in which the cost of interaction between particles on different devices is magnified. We have devised an efficient distributed "forest resampling" particle filter by taking advantage of a logical tree topology for the distributed computing environment.
A. Lee, N. Whiteley. Forest resampling for distributed sequential Monte Carlo.
N. Whiteley, A. Lee & K. Heine. On the role of interaction in sequential Monte Carlo algorithms. Bernoulli, to appear.
A. Lee, C. Yau, M. Giles, A. Doucet & C. Holmes. On the utility of graphics cards to perform massively parallel simulation of advanced Monte Carlo methods. JCGS 19(4), 2010.
A General Metric for Riemannian Manifold Hamiltonian Monte Carlo
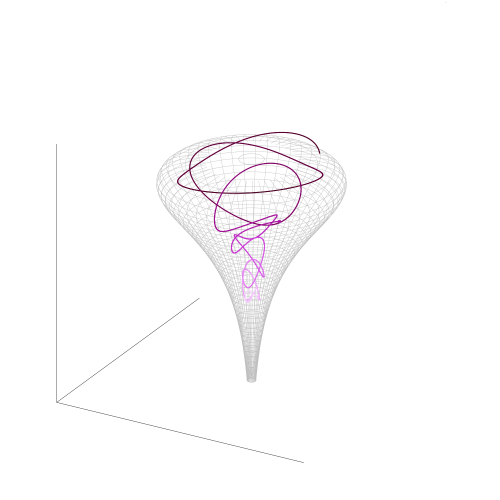
Riemannian Hamiltonian Monte Carlo with the SoftAbs metric admits the efficient exploration of complex hierarchical models in high dimensions.
Betancourt, M. A General Metric for Riemannian Manifold Hamiltonian Monte Carlo. In Geometric Science of Information, pp. 327-334. Springer Berlin Heidelberg, 2013.
Detecting and Preventing Tiger Poaching in the Panna Forest in India



This computational sustainability project, in collaboration with partners in Cornell, India, and Ohio State University, has been developing computational and statistical techniques to protect wildlife from illegal human activity via the deployment and use of wireless sensor networks and machine learning algorithms. In this work a radar sensor has been employed to count human and animal targets within the Panna national park in India. This is part of a larger integrated wireless sensor network that will be in place for the protection of the tiger population and monitoring of illegal human activities like poaching.
T Damoulas, J He, R Bernstein, C Gomes, A Arora, String Kernels for Complex Time-Series: Counting Targets from Sensed Movement, 22nd International Conference on Pattern Recognition (ICPR 2014)
Bayesian methods to detect dye-labelled DNA oligonucleotides in multiplexed Raman spectra
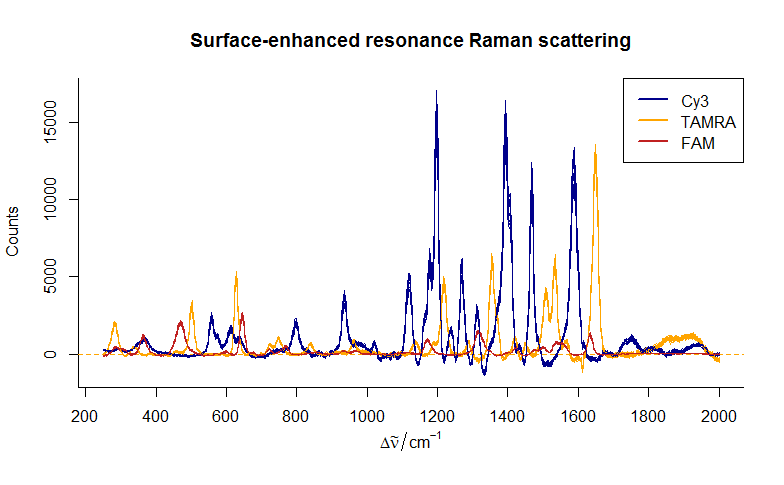
Surface-enhanced resonance Raman scattering (SERRS) is a spectrographic technique for identifying labelled molecules. It provides an alternative to fluorescence PCR, with detection limits in the picomolar range and superior ability to simultaneously detect multiple labels. This figure shows the SERRS spectra of three Raman-active dyes: Cy3, TAMRA and FAM. The goal of our Bayesian source separation model is to identify the component spectra in a mixed signal and estimate the concentrations of each of these labels. This statistical method will be used to identify DNA sequences, such as single-nucleotide polymorphisms (SNPs).
Zhong, M.; Girolami, M.; Faulds, K. & Graham, D. (2011) Bayesian methods to detect dye-labelled DNA oligonucleotides in multiplexed Raman spectra. J. R. Stat. Soc. Ser. C 60(2): 187-206.
Counterfeit currency detection
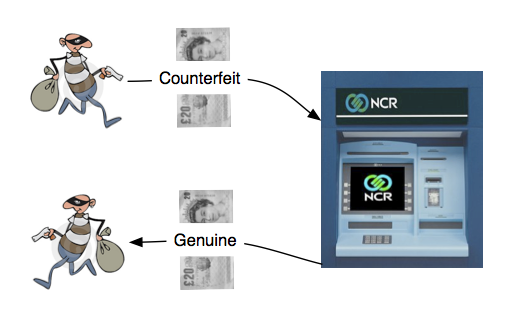
Results from our research work on nonparametric predictive modelling formed the basis of joint research work with the international company National Cash Registers (NCR) to investigate how counterfeit currency could be automatically identified when deposited into an Automated Teller Machine (ATM).
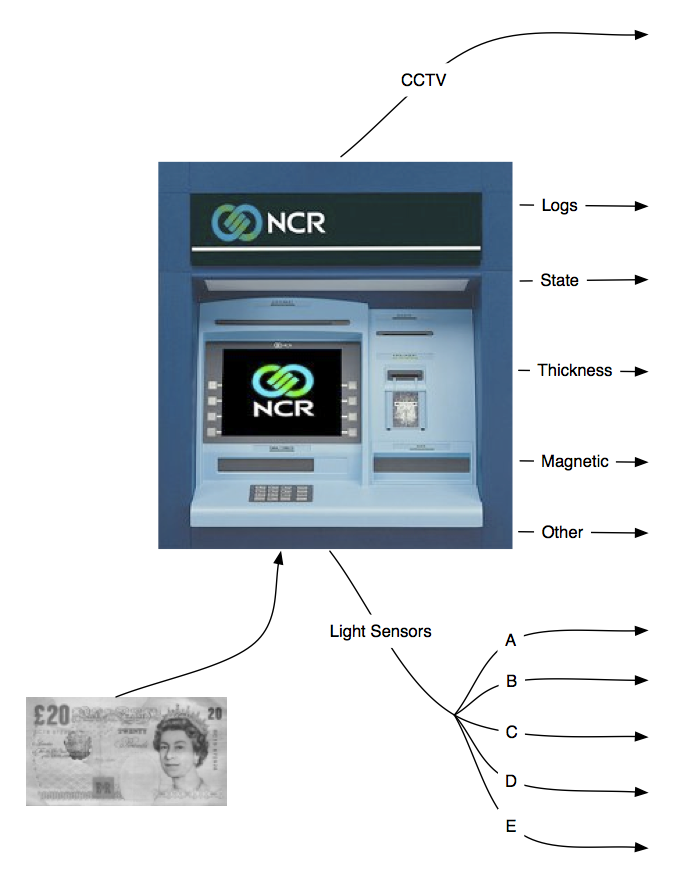
Multiple sources of high volume data from machine sensors in an ATM provide evidence that can be synthesised in assessing the probability of mafeasance. Bayesian statistical methodology was developed to formally integrate these heterogeneous sources of data in a coherent manner.
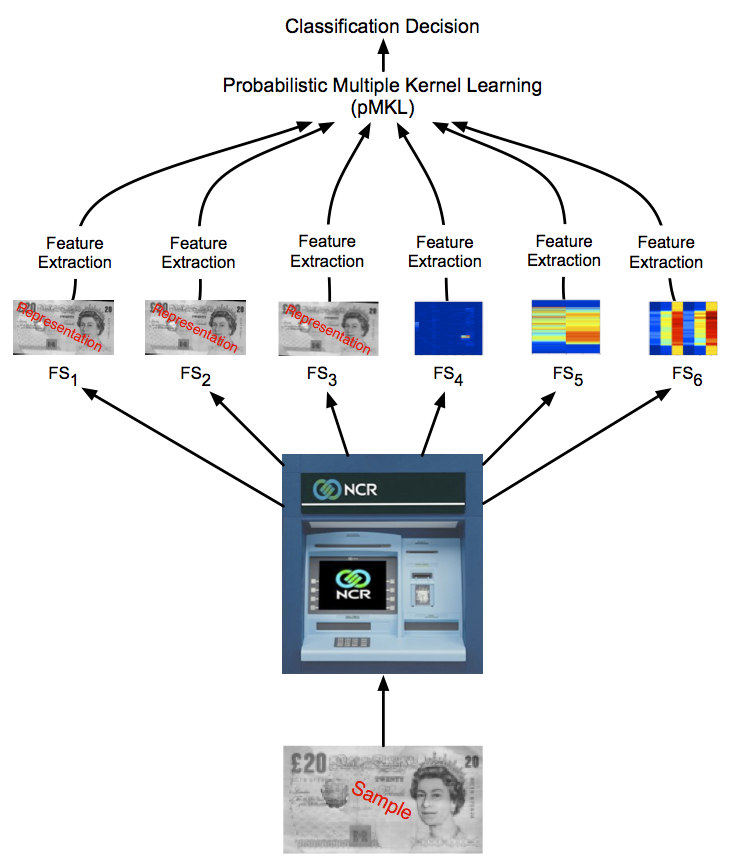
Various measured features from light and mechanical sensors were integrated to provide a posterior probability of counterfeit currency which were then used in a decision theoretic scheme for the machine to come to an optimal decision about the validity of the currency presented. This work received an international patent and over the period of four years NCR developed a robust technology from our research results which is now deployed in the latest generation ATMs.
Filippone, M.; Marquand, Andre; Blain, C. R. V.; Williams, S. C. R.; Mourao-Miranda, J.; Girolami, M. Probabilistic Prediction of Neurological Disorders with a Statistical Assessment of Neuroimaging Data Modalities. Annals of Applied Statistics, Vol. 6, No. 4, 12.2012, p. 1883-1905, 2012.
Girolami,M. and Zhong,M. Data Integration for Classification Problems Employing Gaussian Process Priors. Twentieth Annual Conference on Neural Information Processing Systems, NIPS 19, (MIT Press), 465 – 472, 2007.
He, C., Girolami, M., and Ross G. Employing Optimised Combinations of One-Class Classifiers for Automated Currency Validation. Pattern Recognition, 37(6), pp 1085-1096, 2004.