
WDSI News
Please send text and images for new WDSI news items to <wdsi dot enquiries at warwick dot ac dot uk>.
Warwick researcher develops effective method for diagnosing diabetic retinopathy
The ground-breaking work of Dr Ben Graham![]() , a WDSI member who works in Statistics and Complexity, is featured in a recent Economist article (Now There's an App for That
, a WDSI member who works in Statistics and Complexity, is featured in a recent Economist article (Now There's an App for That![]() , 19 September 2015) about the success of machine-learning approaches to rapid diagnosis of a common disease from retinal images.
, 19 September 2015) about the success of machine-learning approaches to rapid diagnosis of a common disease from retinal images.
Ben's work made him the global winner of a recent Kaggle competition![]() on this machine-diagnosis problem. (This was not Ben's first such success: In 2013 he was the winner of a similar competition organised by ICDAR, with a novel method for recognition of online Chinese handwriting.)
on this machine-diagnosis problem. (This was not Ben's first such success: In 2013 he was the winner of a similar competition organised by ICDAR, with a novel method for recognition of online Chinese handwriting.)
To explain in a bit more detail what he did, Ben writes:
Kaggle obtained pairs of retinal images from Eyepacs/the California Healthcare Foundation from about 44,000 people at risk of diabetic retinopathy. Each of the 88,000 images was graded by a human expert on a scale from 0 to 4; most of the images were healthy zeros. Elevated scores indicate a risk of vision loss. The scores were made available for about 18,000 people to form a training set, with the rest of the scores kept secret to form a test set. The images varied substantially in quality, from in-focus 3000x3000 pixel images to images that were completely blank. Most of the images were of fairly high quality.
I trained a convolutional neural network (or three) to classify the images. To try and boost accuracy, I used the classification for each left-right pair of images to produce the final per-eye classifications, combining scores with a random forest.
The quadratically weighted kappa agreement between my program and the human graders was 0.850. The quadratically weighted kappa agreement between the first and second place computer programs was 0.933; substantially higher. There are two possible explanations:
The truth is likely to be a mix of the two.
- The computers are making systematic errors, and totally missing information available to the human graders. This would be the case if the training set is too small to contain a full range of relevant symptoms.
- The human graders make mistakes, and the computers have learnt to classify the images more accurately that humans.
The example images below are of a healthy retina (first image) and a high-risk case.
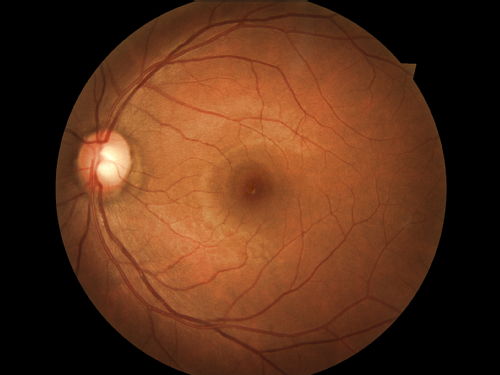
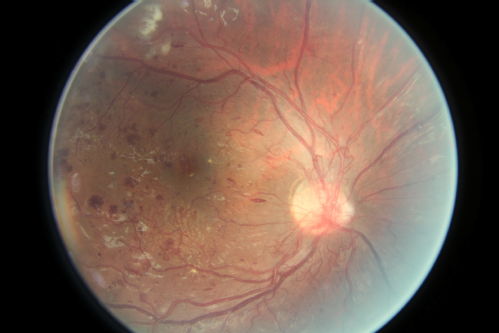
Older WDSI news items:
- Professor Andrew Blake to be the first Institute Director of The Alan Turing Institute (August 2015)
- BSc in Data Science featured by Bloomberg (June 2015)
- Election exit poll: Not quite 'spot on' this time, but another triumph for statistical methods! (May 2015)
- Warwick selected as one of the founding members of the Alan Turing Institute for Data Science (January 2015)
Quick links:
Contact Us
wdsi dot enquiries at warwick dot ac dot uk