JILT 1999 (1) - Erich Schweighofer
The Revolution in Legal Information Retrieval or: The Empire Strikes BackErich Schweighofer For some time, legal information retrieval was a 'forgotten' research subject in legal informatics. The current existence of huge legal text collections and the possibilities of the Web (efficient communications with a nice user interface) returns such research to the fore. The issue is how to deal with the Artificial Intelligence (AI)-hard problem of making sense of the mass of legal information. Legal informatics research for about 40 years can be applied and reused. We describe the various approaches: Boolean logic and knowledge representation in Information Retrieval (IR), vector space model, the tools of AI for IR based on legal language (conceptor based retrieval, inference network, connectionist IR), the automatic acquisition of legal knowledge (machine learning) and summarising techniques of documents and hypertext structures. We conclude that the research is quite promising but much work has to be done. Keywords: legal information retrieval, legal knowledge representation, neural networks, automatic generation of hypertext links This is a Refereed Article published on 26 February 1999. Citation: Schweighofer E, 'The Revolution in Legal Information Retrieval or: The Empire Strikes Back', 1999 (1)The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/99-1/schweigh.html>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1999_1/schweighofer/> Informatics and the problems of its applications have to be taken seriously. After some years of traditional resistance the electronic approaches have prevailed. The logical consequence is that applications have to work without errors and failures. The Year 2000 problem focuses this situation. After years of computer phobic of the general population, everybody surfs the Net or publishes original material electronically. At least in the developed world, the life of human beings is quite dependent on the smooth functioning of computers. The culture of this evolution (or better: revolution) appears simple but is difficult to achieve: Applications, including those in legal informatics, have to be very user-friendly, reliable and sufficiently intelligent to meet the aims of the users. The years of trial and error applications are over. This article addresses the problems arising from these qualitative requirements in legal information retrieval (IR). The quite pressing interface issues of the beginning of the nineties have been solved by others (the Web community) in a much better way. However, the main topic of research we will share with the Web community is: 'What will continue to be AI-hard is the problem of making sense of the mass of data and misinformation that fills the Web'. (Filman, Pant 1998). Law has an advantage in that research has been done for about 40 years and the integration of IR with methods of AI has already begun. As we will show, legal IR has much to offer for related research topics in informatics. In this paper, we address the huge text collections as an empire of information. Their suitability for AI-hard research is still discussed in the AI & law community but we are convinced that the integration of AI and IR in law is inevitable. The small-scale high level applications of AI have to prove their suitability for IR. The empire of legal information strikes back and moves again to the centre of research in legal informatics. 2. Legal Information Retrieval: A 'Forgotten' Research Topic in Legal Informatics for some time Legal IR was the first - and for some time only - research topic of legal informatics. In the late eighties and early nineties, research on logic-based knowledge systems - so-called expert systems - prevailed. Legal information retrieval was regarded as an outdated research topic in comparison to the flavour of the highly sophisticated topics of artificial intelligence and law. Unfortunately, lack of practical success in the aim of replacing lawyers left the community with a lack of orientation. At the end of this millennium, things are seen differently and to some extent, legal information retrieval has returned to the centre of research in legal informatics. In his contribution to the NRCCL Anthology, Bing emphasised the important role of lawyers in the development of information retrieval (Bing 1995). Time seems to repeat itself. Digital libraries and search engines with nice interfaces are common now. Legal IR with its long experience in the organisation and retrieval of information may again offer some solutions for informatics in general, especially the Web community. The main research topics of legal IR are the user interface, Boolean logic, vector space model, the tools of AI for IR based on legal language (conceptor based retrieval, inference network, connectionist IR), the automatic acquisition of legal knowledge (machine learning), summarising techniques of documents and hypertext structures. In the following, we deal with these approaches in detail. The goal is always a dynamic electronic commentary of the legal order. At the begin of legal IR, the user interface was regarded as quite advanced and user-friendly. Dedicated terminals like the very famous LEXIS terminal allowed easy access to the new databases. Some training was still required but not seen as a disadvantage at this time. As time passed by, the interface of legal IR applications began to look very old-fashioned. We will give you the example of a difficult search strategy in the European Community law database CELEX with the search language MISTRAL: [M:QU] :OJ ((austria OR Sweden) AND accession ) :TITLE The syntactical signs in square brackets could be left out as an implicit part of a search statement. CELEX also gives a good example of the next development. In order to overcome these deficiencies database owners developed their own user-friendly interfaces at high cost. Many databases had more success than the quite late MISTRAL forms:
Figure 1: MISTRAL Search Form
Figure 2: CELEX Internet Search Form
This example also shows the trend in interfaces: The Web offers a highly accepted and reliable user interface. Most databases changed their own interfaces to the cheaper Web. The result is that the user interface disappeared from the list of hot research topics. It is obvious to mention that a comprehensive documentation of a legal order comprises gigabytes of data. Following an information model of law, the aim of a legal IR system is a model of the legal order in the form of a database (Schweighofer 1998). The starting point is a legal concept of information (Schweighofer 1995) as an integrated consideration of computer science as well as jurisprudence. The crucial question of evaluation of knowledge representation in IR systems is how expediently legal knowledge is represented in legal databases. Two possibilities exist for structuring the database: documentation of the sources of law (objective legal information, e.g. official gazettes and law reports) or of information sources (e.g. law journals). The approach of objective legal information allows the dynamic and precise documentation of the related materials. Real time information and extensive coverage of all sources are most important goals. The documentation of information sources focuses more on the selection, compression and analysis of information. The acceptance of this database rises and falls with the quality of its law journals or case reports. Completeness of the database was an issue 10 years ago (Bing 1986) and, it's the sad truth, it remains an issue now. The quantitative method of evaluation is popular neither in legal IR nor in the IR community. Only one big study exists (Blair, Maron 1985) with disappointing results. The users by far overestimated the amount of relevant information retrieved by electronic means. Only about 20% was retrieved when the users believed they had retrieved at least 75%. On the other hand, with more precise searching it is possible to retrieve 79%. A possible solution of this severe and underestimated problem can be seen in contents-related and linguistic indexation (Dabney 1986, Berring 1987, Bing 1987b). The retrieval algorithm (or to use a more fashionable term: search engine) has not changed very much since the start of the first system of Horthy in Pittsburgh. The standard model of Boolean search in inverted lists with distance operators remains the most used system in legal IR despite its apparent deficiencies. So far, the main improvements have been in the increase of computing power and more sophisticated structures of inverted files. The user interface has already been mentioned. New retrieval techniques come from three different areas: integration of AI and IR (we come to that later), improvement of commercial applications and large scale applications of IR on the Web. New retrieval techniques developed by computer science finds increasing entry into commercial applications. IR programmes integrate many helpful techniques like weakening of Boolean search logic, search for similarly written words or search for similar documents (cf. for PC software(Heesterman 1996, Lauritsen 1996)). The search engines on the Web is also a good area for development. With the necessity of expedient indexation of the Internet for the purpose of structuring, the IR community has got an almost unsolvable task. The previous search techniques employ in addition to Boolean search in particular the statistical means of the term frequency and of the inverse document frequency for ranking of documents. Terms in specific document parts like title, beginning of the document as well as the META tag (HTML version 3 or higher) receive higher weights during indexation. Retrieval quality is modest and requires better techniques of the automatic and semi-automatic document description (Gudivada et al. 1997). 4. Boolean Logic and Knowledge Representation in IR The pioneers of legal IR were quite aware of the limitations of Boolean search in inverted files with distance operators. The syntactical representation of materials with disregard of semantic or pragmatic meanings were regarded as inappropriate. Some research was done to improve this situation (for an overview see (Bing 1984, Schweighofer 1998) or the journal Datenverarbeitung im Recht). Only one approach of document structuring was implemented in practice and yielded some results. The main idea of this approach consists in structuring of the documents into document types and fields. This allows also a linguistic approximation dealing with the problems of homonyms and of synonyms ( Schweighofer 1995). It is well known that legal documents in print contain a highly sophisticated structure. The representation of these different types requires special document types relating to advanced field structures within the database. The goal of structuring of documents into several fields requires excluding the ambiguities of syntactic representation and the adding of semantic meanings to specific fields. This method can be quite successful but has disadvantages. Using traditional user interfaces, the appropriate search techniques are very difficult to learn. Many commands and fields had to be memorised. Therefore, the practical success was limited. A nicer representation with a hypertext structure would have helped much in practice but came a bit too late for large scale application. Time will show how much of this document structuring will be moved into the hypertext environment. The best example of this approach is the European Community law database CELEX with 10 main indices and 80 fields (see for details (Schweighofer 1995)). In the very nice Internet user interface, only very few fields can be specially searched (e.g. title, classification or document type). The implementation of citation search is user-friendly but time-consuming. Firstly, the relevant document has to be found. Secondly, hypertext links can be used to search for related documents. The important information in documents was not appropriately used in these techniques. In the age of mark-up with SGML or its sub-definitions HTML and XML (Khare, Rifkin 1997), new possibilities emerge. I see great chances of mark-up with XML if the research results of document structuring could be reused. Recall and precision will be greatly improved. XML may solve - in close co-operation with hypertext - the problem of user-unfriendliness of the former applications. In the Vector space model, documents are represented as vectors of the descriptors that are employed for IR (Salton 1971, Salton, McGill 1983, Bing 1984, 165 et seq.). A vector consists of so many qualities as the different words available in the body of text. Therefore, the vector length corresponds to the number of the words in the body of text. Every attribute can be weighted concerning its importance. In the simplest case, the attribute receives value 1 if the descriptor occurs and 0, if this is not the case. In contrast to this binary indexation, the number of the occurrences of the descriptor in the document and of its distribution in the text corpus is also considered during weighted indexation. The similarity between two vectors is usually computed as a function of the number of qualities which are common to both objects. Salton (1983, 201 et seq.) gives five means for the calculation of the similarity between the vectors: Coefficients of Dice and Jaccard, cosine or Salton-coefficient, overlap measure and asymmetric measure. The Dice- and Salton-coefficient have attained greater importance. The result of the similarity calculation is always a value in the range [0, 1], independent of the number of the terms, its weighting or the length of the vectors. In order to find relevant documents the most similar document vector is searched for the search vector. The advantages consist in the fact that the severe binary relevancy of the Boolean search is avoided. A ranking of documents is inherent to the vector space model. Information representation is done according to similarity to the search vector. Document vectors can also be employed as search vectors (another document like this). Moreover, similar documents can be combined into clusters through matching the search vectors with the centroid vector. The most important disadvantage of the vector space model consists in the high requirements of computer power compared to Boolean search in inverted lists. In the legal field, only small importance was attributed to the vector space model until recently because of the insufficient regard to the particularities of legal language (professional jargon, legal phrases, outstanding search words or citations) (Smith et al 1995, 83). The following experiments and applications were carried out:
The vector space model had its importance as an early tool for experiments with alternative representation of documents and descriptors allowing clustering techniques or the computation of co-occurrences between documents. Although they have not been commercially successful, vector space models remain an important tool for research. 6. Value-Added: Tools of AI for IR The impact of improved access to legal materials by contemporary legal information systems is weakened by the exponential growth in the quantity of materials. Currently, information retrieval systems constitute little more than electronic text collections with (federated) storage, standard retrieval and nice user interfaces. Improvements in these aspects have to be left to the IR and Web community. The legal IR research and Web data mining have the task of making sense of the mass of legal information available on the Web. This research goal is quite old. In 1970, Simitis (1970) coined the phrase information crisis of law for the emerging problems of the quantitative explosion of legal materials. We have to stress again that storage and access to even bigger collections of legal materials is not the problem any more. Now we face the problem of helping the lawyer in mastering this quantity. The old method of reading and memorising the materials does not work any more. The AI-hard problem is the development of tools of sophisticated representation of knowledge, intelligent retrieval, linguistic research and summarising techniques. The goal of this research can be seen in a dynamic electronic commentary of a legal order. The decisive test of this form of legal knowledge representation is the practical utility. The techniques of AI have an essential advantage compared to information retrieval systems. The formalisation occurs on a considerably higher level. The benefit lies in the considerably simpler access to legal knowledge. This evidently useful intelligence of the knowledge-based systems faces the high expenditure and effort in knowledge acquisition which constitutes the main obstacle to practical application. Information retrieval systems are good for text representation, artificial intelligence systems for the knowledge representation. A major chance of improvement lies in the improved handling of legal language. Information retrieval systems use language as the main form of knowledge representation but only in syntactical form. The building of bridges between the AI and IR can make IR systems more intelligent. Users would receive some help concerning the semantic and pragmatic meanings. Therefore, an analysis of the language and to provide the linguistic structure must occur as a first step. This research aim will be an experimental solution for the essential obstacle of every intelligent structuring of legal knowledge: the high resource expenditure involved in the knowledge acquisition. Yet, comprehensive analysis of legal language is out of question at present. Therefore available options are improvement in language representation in legal IR and Exploratory Data Analysis (EDA). These semi-automatic methods of analysis only function if the respective means were adjusted and proved in a text corpus. Only the precise knowledge and modelling of document and linguistic structures allow good results (Church, Mercer 1993). Through this modelling the respective text corpus is tested for the applicability of this approach. The work with IR systems teaches amazing things about language (Bing 1995, 556). Although language is considered in IR only in a very simplified manner, it is always present in case of queries and the representation of the documents by its descriptors. The quality of research is highly dependent on the knowledge of the language and terminology. A minimum requirement is the information on the morphology of language and problems of homonyms and of synonyms. 6.2 Synonym Problem and Conceptor Based Search Synonyms are different linguistic expressions with the same meanings (Bing 1983, Bing 1987a, Bing 1995). In a narrow sense, only words with the same meaning are regarded as synonyms. Broadly speaking also words with related meanings (e.g. rapidly, urgently, fast, swiftly etc.) are regarded as synonyms. Synonyms can be context-dependent or non-context-dependent. The same things are designated by an abundance of different words. In IR some special features complicate the problem. Different spellings of the same word (American and British English), the different grammatical extensions of words (morphology), outdated terms, different legal terminology in the case of the same language (German and Austrian legal terms) are to be added to the synonyms. In the Finnish language, a word can have more than 2,000 different forms. Special problems of synonymy show itself in multilingual jurisdictions (European Union, Belgium, Canada, Finland, Ireland and Switzerland) or in the use of different 'generations' of the same language (Greece, Norway). Three solutions exist for dealing with the synonym problem: synonym list, conceptor-based retrieval and inference network. The synonym list can be easily implemented. The problem lies in the maintenance of the list and some misunderstandings of the user. In conceptor based retrieval, queries are structured according to the inherent ideas in the search problem. Documents are relevant if these ideas are (in part) contained in the document. During the search formulation, every idea is described by a term class (conceptor) as a class of words that represent the same idea (Bing 1984, 169 et seq.). A ranking occurs according to the number of ideas which are contained in the document. As a second criterion for ranking, the number of the words of the term classes which are contained in the document is used. The basis of conceptor based retrieval consists in a good knowledge of the concept structure. Although the Norwegian SIFT system was superior during controlled experiments of the NRCCL to the standard model and the vector space model, its distribution is quite modest. 6.3 Homonym Problem and Word Sense Disambiguation, KONTERM Project Homonyms are words that match in spelling but have different meanings (Burkart 1990, 167 et seq.). Polysems are expressions with initially the same importance, however by transfer, analogy, historical or regional development have developed different meanings or are employed as general terms in different contexts. For this problem the Boolean search in inverted files offers no solution since words with the same spelling are taken as homonyms. In jurisprudence, polysems are very frequent but represented with other characteristics. Many legal terms are employed in a different context than in natural language. The exact importance of a legal term can only be understood in its context. This phenomenon is considerably more frequent than the similar homonymy and substantially affects the quality of results in legal database queries. Homonymy and polysemy depress precision because such words have more than one meaning. Sense resolution will be an important component in future retrieval systems. The disambiguation techniques are mainly based on the idea that a set of words occurring together in context determine appropriate connotations. This approach can be used to compute various senses of descriptors (see below the KONTERM project) or determine appropriate senses for word sets despite each individual word being multiply ambiguous. So far, the experiments with word sense disambiguation techniques have been disappointing. Voorhees (1993) uses the word senses in the lexicon WorldNet for disambiguation. The improvement of the retrieval is modest. The sense disambiguation is very difficult in short query statements. Missing correct matches because of incorrect sense resolution have a deleterious effect on retrieval performance. Sanderson (1994) uses pseudo-words for disambiguation. The results on retrieval performance are similar to those of Voorhees. An implementation can only be recommended if the disambiguator is able to resolve word senses to a high degree of accuracy. The NetSerf application of (Chakravarthy, Haase 1995) is a programme for searching in information archives on the Internet with semantic knowledge representations and with a disambiguator using the lexicon WorldNet. Semantic knowledge representations of archives lead to a remarkable increase of performance. The disambiguated version performs slightly worse than the undisambiguated version. Disambiguation with the help of a lexicon or a text corpus provides a strong impetus to the goal of multilingual information retrieval (see the proceedings of SIGIR'96 and SIGIR'97, especially (Davis, Ogden 1997, Hull, Grefenstette 1996)). The situation is different if the technique of word sense disambiguation is used for automatic indexing. Quite promising results were achieved with disambiguation (Stairmand 1997) and in the KONTERM project. The KONTERM workstation was created within the framework of the projects KONTERM I and II, that were carried out at the University of Vienna, Institute for Public International Law and International Relations under the direction of the author from 1992 to 1996. The aim of the project KONTERM workstation is to provide a hybrid application of methods of legal knowledge representation assisting lawyers in their task of managing large quantities of legal information contained in natural language documents. A major part of the project consisted of developing the word sense disambiguation. Other important elements were document description and the automatic generation of hypertext links. The goal of the project KONTERM I was the test of statistical means for the approximation of legal language. The emphasis was on the analysis of language (Schweighofer, Winiwarter 1993b, Schweighofer 1995) and document description (Schweighofer, Winiwarter 1993a). The prototype of the workstation KONTERM II (Schweighofer et al 1995, Schweighofer 1998) contains the following functions:
The following graphics show the course of the functions of the prototype KONTERM II:
Figure 3: Functions of Konterm II
The detection of word senses is a central issue of the KONTERM workstation. In practice we used the results obtained from statistical cluster analysis although the results achieved with the self-organising maps were slightly better. This is because of the very long time needed to train the self-organising maps especially when given long document descriptions that are natural in a real working environment. The core of lexical analysis of concept meanings is the recognition of linguistic patterns. A characteristic of the approach is the inclusion of knowledge on the legal language in a cascaded architecture. Features of analysis are:
We give an example of the procedure of sense disambiguation with the concept of mandates:
Figure 4: Description of the Term mandate The five various meanings concern mandates for inspection or implementation (cluster 1), expansion of the territorial field of application to mandated territories (cluster 2), UN trusteeship system for mandates (cluster 3), mandate of the Inter-American Convention of Human Rights (occurrence 1 not allowing arbitrary allocation) and expansion of the mandate (occurrence 2 not allowing arbitrary allocation). The self-organising feature map of Kohonen is a net with a layer of input units and output units which are arranged in a two-dimensional field (Schweighofer et al 1995, Merkl, Schweighofer 1997). The vectors of the term meanings are employed as input. The output units are weighted vectors (wi of the neuron i ) with the same dimension as the input vectors those are initialised with coincidental values. Moreover, the output units are combined with their topographical neighbours. The neural net learns in an unsupervised manner, e.g. in the training phase no additional information is provided. The learning procedure is described in detail in (Schweighofer et al 1995). An order of the input data in a two-dimensional field of the neurons which corresponds to its respective similarities is established as a result of the learning process of the self-organising map. In contrast to the cluster analysis, instead of classes, maps are provided as output. The view of the concept space is considerably better while the explanation of respective concentrations is still insufficient. Due to space restrictions, we refer to the example of the term neutrality as described in (Schweighofer et al 1995). The word sense disambiguation is quite successful for linguistic research and document description. A hypertext environment enables the user to cope with some slight inconsistencies. More advanced mark-up may improve the results. The success depends on proper text corpora and more use in legal research. Related research in legal IR refers to solutions similar to those applied in the KONTERM project. Mackaay (1977, 65 et seq.) proposed the intensified structuring of the database as well as the inclusion of abstracts as a solution. Another approach has its starting point in the idea of the so-called search synonyms (searchonyms). Search words are added as search synonyms to the term for the better representation of an idea and the relevant context (Bing 1984, 259 et seq.). The best example of an application is the Responsa project which includes local metric feedback (Choueka 1980). Elegant implementations of some linguistic knowledge can be carried out with probabilistic approaches (Turtle, Croft 1990, Turtle, Croft 1992, Turtle 1995, 27 et seq.). The essential assumption of this model consists in the fact that the best retrieval quality is achieved with a ranking according to probability of relevancy of the documents. The task of the IR system is an inference and evaluation process in that the best possible estimate of relevance probability occurs. The core of this approach is the probability ranking principle: The search result is a ranking of all documents with decreasing relevance probability, where the probabilities are estimated as precisely as possible on the basis of a best possible appreciation (Van Rijsbergen 1979, 113-114). The very general probability ranking principle was advanced in a series of very different models (cf. for an overview (Turtle 1995, 27 et seq.)). In legal IR, at present only the inference network is employed. Inference nets of Bayes represent an elegant method of representation of probabilistic dependencies. The most important model was developed by Croft and Turtle for the natural language search in the legal IR system WESTLAW (Turtle, Croft 1990). According to Croft and Turtle, information needs are a complex value sequence over the document contents with the possible values W (true) and F (false). The query represents the information needs. The essential advantage consists in it that an abundance of different evidence sources can be employed for relevancy of the document in order to compute probability (e.g. terms, phrases, citations, thesauruses, document structure). With the aid of the knowledge base, legal terms are recognised and linguistic structures (morphology, misspellings, thesaurus relationships) are considered. Statistical calculations are also included. With the inference network, Boolean search and the vector space model can be simulated (Turtle, Croft 1992). The attractiveness of the inference network consists in the fact that knowledge can be represented via relevancy of every search word in an elegant manner. Search words with low selectivity receive a low conditional probability while legal terms are provided with high conditional probability. The problem of this approach is reduced to the as precise as possible definition of relevancy of every search word. This inference network is used commercially as WIN (Westlaw Is Natural) by the American database WESTLAW. LEXIS also created a similar search possibility with FREESTYLE. The very extensive tests of WESTLAW suggest that significant improvements are observed both in recall and in precision (Turtle 1994). The costs of computer power are comparable with those of commercial systems with Boolean search. 6.5 Connectionist Information Retrieval In connectionist models of IR information is represented as a network in which nodes represent objects (concepts and documents) and edges represent the connections between these objects. The advantages for IR are the associative representation of concepts and documents (Belew 1987, Rose 1994) as well as the support of queries. Applications in legal IR exist in the projects AIR and SCALIR. The AIR (Adaptive Information Retrieval) of (Belew 1987) is based on a connectionist network containing three node types: terms, documents and authors. The initial term-document connection weights are based in the inverse document frequency (IDF). A query in AIR is the activation of nodes. Activity propagates through the network to activate other nodes until equilibrium is achieved. The query result is the set of most active nodes after propagation (documents but also terms or authors). The learning in AIR is achieved in changing the connection weights according to the relevance-feedback of the users. This approach was further developed by (Rose 1994) with SCALIR (a Symbolic and Connectionist Approach to Legal Information Retrieval) incorporating traditional symbolic inference. The basic idea is that the activity of the network is proportional to the relevance of documents. The result of a query are documents whose nodes have thehighest activation. The neural network includes nodes to represent terms, cases and statute sections.
Figure 5: The general structure of the SCALIR network (Source: (Rose 1994, 151))
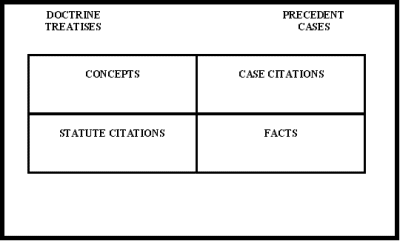
Three types of links represent associations between the nodes: The connectionist links or C-links represent weighted, unlabeled associations based on statistical inference (modified form of inverse document frequency) (Rose 1994, 152 et seq.). A document is represented by approximately 10 terms. Additionally, the West key number taxonomy for copyright law and the statute tree are manually assigned. The symbolic link or S-links form the semantic network of the system. S-links contain the formal relations between cases and statutes. These connections were taken from Shepard's citations. The labels affirmed, reversed, superseded, modified represent the relationships between court decisions. S-links also represent statute dependencies (e.g. contains, refers-to). S-links were fixed at creation and cannot be modified by learning. The hybrid links or H-links describe relationships between documents representing the subjective opinion of an expert indexer. Typical associations are similarity of the facts (parallel or distinguished) or issue of law (followed or overruled). H-links are learnable and therefore subject to adjustment. The task of the 'retrieval engine' of SCALIR is the retrieval of documents with the highest activation according to the query. SCALIR retrieves at least a few documents but no more than about a dozen. The learning capabilities of SCALIR were tested only in a small experiment. SCALIR is the best developed connectionist system in IR. Due to the renunciation of hidden units, the propagation within the neural network remains open to examination. Despite the remarkable number of documents and units the question remains if such results could not be achieved with symbolic representation and relevance feedback. Rose had to implement considerable restrictions in order to retain the functions of SCALIR's network: the number of terms per document is limited to about 10 and only a small subset of a node's neighbours are visited. 7. Automatic Acquisition of Legal Knowledge (Machine Learning) and Summarising of Documents This model is typical of applications involving information filtering. The analysis is divided into two steps. Pattern recognition is used on the sentence level for the identification of concepts. Word groups in documents are matched with a templates library. These templates contain linguistic structures with some probability concepts. Found templates are used for the document description. Typical applications of this model are SCISOR (Jacobs, Rau 1990) or FASTUS (Hobbs 1992). An important prerequisite is the cascaded architecture. Irrelevant documents are filtered out by classification. For the remaining documents, a domain specific analysis is done. This procedure limits the work and enhances the quality. A simplification is the extraction approach. Important sentences or parts of sentences can be recognised through document structures such as the position of the sentence within the document or paragraph, the existence of catchwords or catch phrases and the number of semantic relations between a sentence and its neighbours (Paice, Jones 1993). In practice, such systems were seldom implemented due to the unsolved problem of anaphers and ellipses. In the case of good structured texts interesting results are possible. In the system BREVIDOC, documents are automatically structured and catchwords are used for the extraction of important sentences. These sentences are classified according to the relative importance of rhetorical relations (Mike et al 1994). The system of (Kupiec et al 1995) also uses pattern matching for extraction. For each sentence the probability of being included in a summary is computed. Legal applications use the approaches of template library and extraction with a matching of templates (descriptors of a thesaurus, phrases or citations). Methods for the automatic generation of such templates must be implemented. Otherwise the effort of building the knowledge base is too high. Linguistic research concentrates on the generation of phrases with significant meaning. The goal is more focused on the automatic description than on retrieval of documents. The methods used include: development of thesauri, machine learning for feature recognition, disambiguation of polysems, automatic clustering and neural networks. The very often neglected automatic knowledge acquisition is very important. This research shares many common goals with IR. The most important systems are FLEXICON, KONTERM, ILAM, RUBRIC, SPIRE, the HYPO extension (Bruninghaus 1997) and SALOMON. The main problem of these approaches lies in the fact that they cannot be used for huge databases yet. One of the best known applications is the FLEXICON system (Gelbart, Smith 1990, Gelbart, Smith 1993, Smith et al 1995, Smith 1997). The structured representation contains legal terms, quoted cases, quoted norms and factual terms. It is generated automatically and employed for the vector-based representation of a document. The required computer power was reduced essentially by this reduction of the vector length. Documents and queries are represented as weighted vectors. The calculation of similarity occurs with the cosine coefficient. The descriptors are weighted with the inverse document frequency. The users can determine the importance of the term in their query with the categories [high, average, low, not]. The FLEXICON project applied heuristics for the semi-automatic creation of a concept dictionary that was dependent of the respective text corpora. The basis for these heuristics are intellectually developed templates: All root forms of a word are regarded as representing the same concept. The following terms are extracted from the text corpus and integrated into the concept dictionary: Terms which frequently appear in proximity to each other, terms which have a strong semantic relationship to doctrinal structures, terms and phrases in foreign languages (e.g. not in English), which are not names or locations, multi-word concepts including joiner words like 'by' and 'of' (e.g. standard of care), two or more words if the prior word is a certain kind of modifier or qualifier (e.g. reasonable doubt), phrases or set of words found in proximity to the words principle and doctrine (e.g. the good neighbor principle). After this automatic generation of descriptors, the concept dictionary is improved using a wide variety of legal sources such as dictionaries, thesauri, statutes, indexes, learned authorities and treatises. The result is a concept dictionary with root forms and synonym information. The matched information can appear in any order in the text and phrases can be separated by noise words. Case and statute citations are recognised through template matching based on the citation mechanism for cases and statutes. Fact phrases are recognised by term distribution and proximity information with a lexicon of noise words. A set of rules identifies classes of noise terms like names, numbers, etc. The creation of the concept dictionary (lexicon) in FLEXICON is semi-automatic with a quite strong input of knowledge on legal language. Extraction is heavily used for citations. A corpus-based heuristic is applied for the selection of fact phrases. Results are satisfying and show the potential of the semi-automatic approach. Cases were summarised as flexnotes. A flexnote consists of case header information and four quadrants containing the most significant concepts, facts, case citations and statute citations.
Figure 6: Profile of FLEXICON (Source: Smith et al 1995, 60]) This profile of a legal document can be used to form queries and to summarise the document in form of flexnotes. A characteristic of the FLEXICON system is the extensive use of legal language and formal structures of law. This knowledge base requires consecutive adjustment. The quality of the retrieval is significantly higher than Boolean search. One problem with FLEXICON as well as the connectionist IR system SCALIR, the inference network is a more elegant implementation of linguistic and structural knowledge and the required computational power is not much higher than for Boolean search. The added-value of FLEXICON or SCALIR is not so high that the disadvantages of higher computational power and knowledge acquisition can be justified. KONTERM's knowledge acquisition tool for word sense disambiguation has been already described above. The other techniques are typical for information filtering. The knowledge base contains linguistic structures. In case of its occurrence, one refers to the specific contents of the document. In the model, noun phrases are above all used where these are formulated with distance operators in Boolean search logic with probabilities. The information in the context is excerpted and used for the document description. In the same manner and in the case of context-related rules, an interpretation can occur on the meta level. The problem of anaphors and of ellipses can be neglected for the goal of document description. The knowledge base of KONTERM consists of the following parts:
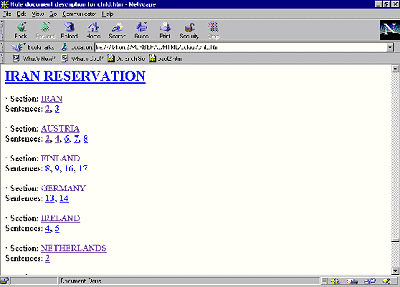
The construction of the knowledge base is planned according to the basic principles of object-oriented and deductive programming. The knowledge base is built up for specific partial disciplines (especially public international and European law). This general knowledge base is the subject of an iterative refinement within the framework of a jurisprudendial analysis. The result is a specific knowledge base for specific legal questions. Although a comparison can give only a rough picture of the possibilities, the matching of text corpora to this knowledge base can be compared with qualified glancing of texts by lawyers. Those document segments which are important for legal application and need a precise analysis are selected from the abundance of information. The knowledge-based model of the semi-automatic text analysis achieves valuable preparatory work for further research of the legal problems. The approach employed here corresponds to that of FLEXICON where it is given more importance to excerpts of relevant parts of laws or court decisions. The citations have a considerably smaller role to play in public international law than in national law. A good example of this approach is the computation of objections to the general reservation (Sharia law) of Iran to the human rights treaties:
Figure 7: Excerpts/Extracts from the Document Description of the Reservations to the Convention to the Protection of the Child Other applications consist of the generation of principles of public international law or the extraction of important parts of a judgement of the ECJ. The document description of KONTERM shows the full potential of this approach. Adjusted to general or particular legal problems (in the example: general overview) important parts of documents are selected for further analysis. United Nations Convention to Combat Desertification in those Countries Experiencing Serious Drought and/or Desertification, particularly in Africa, 17.6.1994
Figure 8a: Document Segmentation: A Figurative Representation of the UN Convention on Desertification
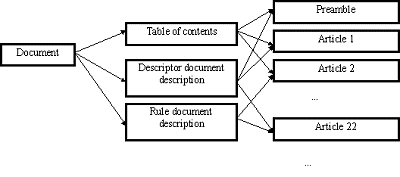
Note: The full document description could not be represented here due to space restriction but can be found at < http://www.ifs.univie.ac.at/intlaw/konterm/konterm.htm>. Figure 8b: Document description - Desertification Convention For the automatic summarisation and classification of documents (Schweighofer 1998), the various documents are represented as feature vectors of the form x={t1, ..., tm, c1, ..., cn, m1, ..., m0}. The ti represent terms extracted from the fulltext of the document, the ci are the context-sensitive rules, and the mi represent the meta rules associated with the document. The description of documents is done by matching documents with the knowledge base. The document space can be described using cluster analysis or neural network. The analysis of the document space by the Kohonen map has been presented in detail in (Schweighofer et al 1995). The problem of the cluster analysis remains the long list of files without group assignment if the number of descriptors and of rules is not sufficient. The results of the neural net are considerably nicer. All documents are included in the analysis even if information may still be inadequate. A further improvement of the self-organising map is the hierarchical neural networks (see for details on the architecture (Merkl, Schweighofer 1997)). This feature map model comprises a layered arrangement of mutually independent self-organising maps. The major benefits of this new model which justify its utilisation are a substantially reduced training time as compared to self-organising maps as well as a explicit and model inherent cluster separation. The semi-automatic knowledge acquisition in the ILAM part (TECSIEL, Rome) of the NOMOS project exploits certain features of the domain (Pietrosanti et al 1994, Konstantinou et al 1993). The Macro-Level Processors produce the structure of the text (hierarchical organisation, inter-relations of its substructures). The Micro-Level Processors discover the functional roles of phrases based on the semantic mark-up language and the text patterns typical of the domain. The Syntactic/Semantic Analyser (SAA) creates a conceptual graph representation of the text. The SAA is a deep NLP parser. Syntactic analysis use a shallow grammar to produce structures between word pairs and triples (groups of substantives, adjective-substantive, substantive-preposition-substantive). The lexicon is built using the SLAT (Semantic Lexicon Acquisition Tool) module with a Functional Processor to recognise text pattern in the text corpora. In comparison with the FLEXICON project, more precise templates are generated due to the improved linguistics. Rule-based retrieval systems make use of a knowledge base of rules (templates library) specifying how concepts or important structures are to be recognised in documents (Turtle 1995, 25 et seq., Apt, et al 1994). The language of the rules comprises Boolean logic with distance operations. Probabilities improve the quality of such rules. The advantage is the matching of the knowledge base with the text corpus resulting in a list of relevant documents as well as a document description. In RUBRIC (Tong et al 1987, Tong et al 1989), the conceptual description of a legal domain is transformed into rules for recognising templates in documents. Probabilities can be expressed as evidence rules in order to achieve several conclusions depending on the degree of belief. Two applications are available: corporate mergers and acquisitions and news agency reports of terrorist incidents (Tong et al 1989). The RUBRIC system has a conceptual knowledge structure. The templates are formalised with Boolean logic. The user has the essential advantage that the search is optimised with the given query. The belief functions allow the interpretation of Boolean operators as fuzzy-set operators. The results of the RUBRIC system were very promising. Remaining difficulties are the creation of the knowledge base and the belief rules. SPIRE (Selection of Passages for Information REduction) is a hybrid case-based reasoning and IR system locating passages with interesting factors in fulltext judgements (Rissland, Daniels 1995, Daniels, Rissland 1997). The knowledge base is organised like in the case-based reasoning system HYPO. SPIRE computes the similarity between the problem and the cases of the knowledge base. Best cases are used to produce automatically a query in the INQUERY IR system. SPIRE can rank the most important passages (information extraction system). Within the relevance feedback, the user can mark relevant passages or improve the given representation of factors. Feature vectors are used to extract relevant factors from fulltext decisions for the case-based reasoning system HYPO (Bruninghaus, Ashley 1997). For each relevant factor, a weighted feature vector is defined. A learning phase determines threshold values for classification. The attached factors are used for the computation of case similarity. The system shows great similarities with the KONTERM project but differs in the non-use of neural networks and the use of complex methods of machine learning. Another similar approach to the KONTERM project is reported in the SALOMON project (Moens et al 1997). Belgian criminal cases are summarised automatically and presented by a case profile. Case category, case structure and irrelevant text units are identified based on a knowledge base represented as a text grammar. Thematically important text units and key terms are selected by shallow techniques. These paragraphs are represented as weighted vectors and clustered. The system points the user effectively towards relevant texts. In his invited talk at DEXA '98, Bing (1999) described hypertext as a form of representation of hyperstructures with strong relations to the basic theory of text retrieval and older efforts. This positions puts hypertext in its right place: a hyperstructure in the form of an indexation of collections of documents. This concept was already described by Vannevar Bush (1945). Distributed storage somewhere on a server and a somehow quite simple implementation of hypertext characterise the present state of the art. Hypertext represents the main solution for the appropriate representation of complex legal hyperstructure such as thesauri, classifications, citations and so on. The DataLex workstations and the AustLII project are well known (Greenleaf et al 1995, Greenleaf et al 1997) but many other applications are reported in (Di Giorgi, Nannucci 1994). The success of the Web is a major impetus for improving legal information retrieval with hypertext. Present research aims at improved hypertext links on the Web implementing already known concepts or a new form of ranking of documents. Li (1998) has proposed a qualitative search engine - Hyperlink Vector Voting (HVV) - using the hyperlinks pointing to these documents. The 'voting' links are transformed into a vector allowing the computation of the highest similarity between the link and query vectors. It is interesting to note that a similar idea was proposed by Tapper with his citation vectors (Tapper 1982). The citations are represented as vectors where these are weighted according to their importance. By means of a cluster analysis, similar citations are found. The main problem of this approach remained the knowledge acquisition for the citation vectors but the HVV would solve this problem. 8.1 Automatic Generation of Hypertext Links In comparison to other hypertext applications (Nielson 1993), special problems arise in the legal field. Legal text corpi are huge, complex and undergo regular change. The number of involved hypertext links can only be counted in thousands. The majority are 'lateral' links to definitions, cross-references between sections and articles rather than 'hierarchical' links to tables of contents or footnotes (Greenleaf et al 1995). The huge number of hypertext links makes manual insertion impractical and cost intensive. Therefore, the automatic generation of hypertext links is a very important question in legal applications. Existing applications in law are based mainly on pattern recognition. In the DataLex workstations and the AUSTLII project (Greenleaf et al 1997) automated marking-up scripts are created for each category of document that has a reasonably regular form. Linguistic patterns are used to recognise automatically citations. The approach of the research group at the CRDP in Montreal (Choquette et al 1995) is based on the use of text grammars and parsers. Processes of text reconnaissance and grammar construction allow the identification of link anchor points. In the KONTERM project (Schweighofer, Scheithauer 1996), the basis for the automatic generation of hypertext links is the available segmentation of the documents into document parts (especially articles and paragraphs) and sentences. As a result, a table of contents can be generated automatically. In the case of occurrences of terms and context-related rules, hypertext links are managed automatically for the respective sentences. The following types of hypertext links are available: document list/documents, table of contents/document segments, concepts/documents, rules/documents, document descriptions/rules or concepts and document descriptions and documents. As a result, the glancing over of the documents as well as the further jurisprudential analysis is facilitated essentially.
Figure 9: Structure of the Hypertext Links The above graphic of the network with hypertext links shows the document list as a central element of access. From this list, respective documents and their description with descriptors and rules can be called up as well as the indexing of the text corpus with descriptors, rules and meta rules and the list of document groups. Direct hypertext links exist between descriptors, rules and meta rules and the document descriptions.
Figure 10: Hypertext Links of the Document Description From the table of contents one can jump to the relevant sections. For every occurrence of a descriptor or of a rule, a hypertext link is available for the document position. This combination of summarising technique and hypertext greatly facilitates a closer look at legal documents. The emerging integration of IR and AI leads to so-called hybrid systems. A hybrid system is characterised by using a combination of various methods of AI and IR focusing on the success of the application. This integrative approach shifts the emphasis from expert systems to the whole domain of informatics and law. Huge text collections, search engines, hypertext as a realisation of legal superstructures, more appropriate treatment of the problem of legal language, word sense disambiguation and learning of meaningful templates provide the infrastructure for the dynamic commentary of the future. The flood of information in present legal orders is automatically compressed and analysed in order to provide a proper tool for the lawyer. Legal informatics has to move in this direction. Only the best possible implementation of available technologies could secure a useful support tool for lawyers. This aim brings the empire of legal information back into the core of research in legal informatics. Existing research is quite promising but much work has to be done in order to achieve the goal of a dynamic commentary on a legal order. Apt? Ch., Damerau F, Weiss S M (1994): Towards Language Independent Automated Learning of Text Categorization Models, in: SIGIR '94, 23-30. Belew R K (1987): A Connectionist Approach to Conceptual Information Retrieval, in: International Conference on Artificial Intelligence and Law, ACM Press, Baltimore, 116-126. Berring R C (1987): Volltext-Datenbanken und juristische Informationssuche: Mit dem Rucken zur Zukunft, in: IUR, 5-11, 70-75, 115-123. Bing J (1983): Third Generation Text Retrieval Systems, in: Journal of Law and Information Science, Vol 1, 183-210. Bing J (1986): Legal Text Retrieval Systems - The Unsatisfactory State of the Art, in: Council of Europe '86, Access to Legal Data Bases in Europe, Proc. of the Eighth Symposium on Legal Data Processing in Europe, Strasbourg, 201-220. Bing J (1987a): Designing Text Retrieval Systems for Conceptual Searching, in: ICAIL '87, 43-52. Bing J (1987b): Performance of Legal Text Retrieval Systems: The Curse of Boole, in: Law Librarian Journal, Vol 79, 187-202. Bing J (1995): Legal Text Retrieval and Information Services, in: Bing J, Torvund O, 25 Years Anniversary Anthology, Norwegian Research Center for Computers and Law, Tano, Oslo, 525-585. Bing J (1999): Hypertext - The Deep Structure, DEXA '98 [to be published in the Proc. of DEXA '99]. Bing J (ed) (1984): Handbook of Legal Information Retrieval, North-Holland, Amsterdam. Blair D C, Maron M E (1985): An Evaluation of Retrieval Effectiveness for a Full-text Document-retrieval System, in: Comm ACM, Vol 28, 289-299. Bruninghaus St., Ashley K D (1997): Finding Factors: Learning to Classify Case Opinions under Abstract Fact Categories, in: ICAIL '97, 123-131. Burkart M (1990): Dokumentationssprachen, in: Buder M, Rehfeld W, Seeger Th. (Hrsg.) (1990): Grundlagen der praktischen Information und Dokumentation, 3. vollig neu gefaBte Ausgabe, Munchen, 143-182. Bush V (1945): As we may think, in: Atlantic Monthly, <http://www.isg.sfu.ca/~duchier/misc/vbush>. Chakravarthy A S, Haase K B (1995): NetSerf: Using Semantic Knowledge to Find Internet Information Archives, in: SIGIR '95, 4-11. Choquette M, Poulin D, Bratley P (1995): Compiling Legal Hypertexts, in: DEXA '95, 449-458. Choueka Y (1980): Computerized Full-text Retrieval System and Research in the Humanities: The Responsa Project, in: Computers and the humanities, Vol 14, 153-169. Church K W, Mercer R L (1993): Introduction to the Special Issue on Computational Linguistics Using Large Corpora, in: Computational Linguistics, Vol 19, 1-24. Dabney D P (1986): The Curse von Thamus: An Analysis of Full-Text Legal Document Retrieval, in: Law Library Journal, Vol 78, 5-40. Daniels J J, Rissland E L (1997): Integrating IR and CBR to Locate Relevant Text Passages, in: DEXA Workshop '97 (Legal Systems), 206-212. Davis M W, Ogden W C (1997): QUILT: Implementing a Large-Scale Cross-Language Text Retrieval System, in: SIGIR '97, 92-97. De Mulder R V, van Noortwijk C (1994): A System for Ranking Douments According to their Relevance to a (Legal) Concept, in: RIAO '94, 733-750. Di Giorgi R M, Nannucci R (ed) (1994): Hypertext and Hypermedia in the Law, Special Issue, IeD, Edizioni Scientifiche Italiane. Filman R E, Pant S (1998): Searching the Internet, in: IEEE Internet Computing, Vol 2, No 4, 21-23. Fjeldvig T (1982): Natural Language as a Means of Formulating Search Requests, in: Council of Europe '82, Artificial Intelligence and Linguistic Problems in Legal Data Processing Systems, Proceedings of the Sixth Symposium on Legal Data Processing in Europe, Thessaloniki 1981, Strasbourg, 83-102. Gelbart D, Smith J C (1990): Toward a Comprehensive Legal Information Retrieval System, in: DEXA '90, 121-125. Gelbart D, Smith J C (1993): FLEXICON: An Evaluation of a Statistical Ranking Model Adapted to Intelligent Legal Text Management, in: ICAIL '93, 142-151. Greenleaf G, Mowbray A, King G (1997): The AustLII Papers, Background Papers for Presentations by AustLII Staff, in: Law via the Internet '97 Conference, June 1997, Sydney, Australia. Greenleaf G, Mowbray A, van Dijk P (1995): Representing and Using Legal Knowledge in Integrated Decision Support Systems: DataLex WorkStations, in: AI & Law, 97-142. Gudivada V N, Raghavan V V, Grosky W I, Kasanagottu R (1997): Information Retrieval on the World Wide Web, in: IEEE Internet Computing, Vol 1, No 5, 58-68. Heesterman W (1996): A Comparative Review of Information Retrieval Software, in: JILT, No 3, < http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1996_3/heesterman/>. Hobbs J R et al (1992): SRI International: Description of the FASTUS System Used for MUC-4, in: MUC-4, Fourth Message Understanding Conference, McLean, Virginia, USA, Morgan Kaufmann Publishers, San Mateo, CA, 143-147. Hull D A, Grefenstette G (1996): Querying Across Languages: A Dictionary-Based Approach to Multilingual Information Retrieval, in: SIGIR '96, 49-57. Jacobs P S, Rau L F (1990): SCISOR: Extracting Information from On-line News, in: Comm ACM, Vol 33, No 11, 88-97. Khare R, Rifkin A (1997): Special Feature: XML - A Door to Automated Web Applications, in: IEEE Internet Computing, Vol 1, No 4, 78-87. Konstantinou V, Sykes J, Yannopoulos G N (1993): Can Legal Knowledge be Derived from Legal Texts? In: ICAIL '93, 218-227. Kupiec J, Pedersen J, Chen F (1995): A Trainable Document Summarizer, in: SIGIR '95, 68-73. Lauritsen M (1996): Technology Report: Work Product Retrieval Systems in Today's Law Offices, in: AI & Law, Vol 3, 287-304. Li Y (1998): Toward a Qualitative Search Engine, in: IEEE Internet Computing, Vol 2, No 4, 47-54. Mackaay E (1977): Designing Datum II: Why not and how?, in: DVR 6, 47-82. Merkl D, Schweighofer E (1997): The Exploration of Legal Text Corpora with Hierarchical Neural Networks: A Guided Tour in Public International Law, in: ICAIL '97, 98-105. Merkl D, Vieweg S, Karapetjan A (1990): Kelp: A Hypertext Oriented User-Interface for an Intelligent Legal Fulltext Information Retrieval System, in: DEXA '90, 399-405. Mike S, Itoh E, Ono K, Sumita K (1994): A Full-Text Retrieval System with a Dynamic Abstract Generation Function, in: SIGIR '94, 152-161. Moens M-F, Uyttendaele C, Dumortier J (1997): Abstracting of Legal Cases: The SALOMON Experience, in: ICAIL '97, 114-122. Nielsen J (1993): Hypertext & Hypermedia, Academic Presss Professional, Boston. Paice Ch. D, Jones P A (1993): The Identification of Important Concepts in Highly Structured Technical Papers, in: SIGIR '93, 69-78. Panyr J (1987): Vektorraum-Modell und Clusteranalyse im Information-Retrieval-Systemen, in: Nachr Dok 38, 13-20. Pietrosanti E, Mussetto P, Marchignoli G, Fabrizi S, Russo D (1994): Search and Navigation on Legal Documents Based on Automatic Acquisition of Content Representation, in: RIAO '94, 369-389. Rissland E L, Daniels J J (1995): A Hybrid CBR-IR Approach to Legal Information Retrieval, in: ICAIL '95, 52-61. Rose D E (1994): A Symbolic and Connectionist Approach to Legal Information Retrieval, PhD thesis, University of California, San Diego, Lawrence Erlbaum Associates Publishers, Hillsdale, NJ. Salton G (ed) (1971): The SMART Retrieval System, Experiments in Automatic Document Processing, Prentice-Hall, Englewood Cliffs, NJ. Salton G, McGill M J (1983): Introduction to Modern Information Retrieval, McGraw-Hill, New York. Sanderson M (1994): Word Sense Disambiguation and Information Retrieval, in: SIGIR '94, 142-151. Schweighofer E (1995): Wissensrepr?sentation in Information Retrieval-Systemen am Beispiel des EU-Rechts, Dissertation, Universitat Wien 1995. Schweighofer E (1998): Legal Knowledge Representation, Automatic Text Analysis in Public International and European Law, Kluwer Law International, The Hague [in print] (Habilitationsschrift of the University of Vienna 1996). Schweighofer E, Scheithauer D (1996): The Automatic Generation of Hypertext Links in Legal Documents, in: DEXA '96, 889-898. Schweighofer E, Winiwarter W (1993a): Legal Expert System KONTERM - Automatic Representation of Document Structure and Contents, in: DEXA '93, 486-497. Schweighofer E, Winiwarter W (1993b): Refining the Selectivity of Thesauri by Means of Statistical Analysis, in: TKE '93, 105-113. Schweighofer E, Winiwarter W, Merkl D (1995): The Computation of Similarities in Large Corpora of Legal Texts, in: ICAIL '95, 119-126. Simitis S (1970): Informationskrise des Rechts und Datenverarbeitung, Muller, Karlsruhe. Smith J C (1997): The Use of Lexicons in Information Retrieval in Legal Databases, in: ICAIL '97, 29-38. Smith J C, Gelbart D, MacCrimmon K, Atherton B, McClean J, Shinehoft M, Qunitana L (1995): Artificial Intelligence and Legal Discourse: The Flexlaw Legal Text Management System, in: AI & Law, 55-95. Stairmand M A (1997): Textual Context Analysis for Information Retrieval, in: SIGIR '97, 140-147. Svoboda W R (1978): Automated Generation of Context Associations on the Problem of Creating a Legal Thesaurus fur Fulltext Systems, in: Corte Suprema di Cassazione, Centro Elettronico de Documentazione, L'informatica giuridica al servizio del Paese, Roma. Tapper C (1982): An Experiment in Use of Citation Vectors in the Area of Legal Data, CompLex 9, Universitetsforlaget, Oslo. Tong R M, Appelbaum L A, Askman V N (1989): A Knowledge Representation for Conceptual Information Retrieval, in: International Journal of Intelligent Systems, Vol 4, 259-283. Tong R M, Reid C A, Crowe G J, Douglas P R (1987): Conceptual Legal Document Retrieval Using the RUBRIC System, in: ICAIL '87, 28-34. Turtle H (1994): Natural Language vs Boolean Query Evaluation: A Comparison of Retrieval Performance, in: SIGIR '94, 212-220. Turtle H (1995): Text Retrieval in the Legal World, in: AI & Law, 5-54. Turtle H, Croft W B (1990): Inference Networks for Document Retrieval, in: SIGIR '90, 1-24. Turtle H R, Croft W B (1992): A Comparison of Text Retrieval Models, The Computer Journal 35, 279-290. Van Rijsbergen C J (1992): Probabilistic Retrieval Revisited, in: The Computer Journal 35, 291-298. Voorhees E M (1993): Using WordNet to Disambiguate Word Senses for Text Retrieval, in: SIGIR '93, 171-180.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||