
JILT 1996 (2) - Dan Hunter
Commercialising Legal Neural Networks
Dan Hunter
Emmanuel College
University of Cambridge
dah29@cam.ac.uk
Contents
1. Introduction
2. The Basics of Neural Networks
3. Legal Theory for Neural Networks
4. Lessons for Legal Neural Network Development
4.2 Lesson 2: Neural Networks Can't Explain Worth a Damn
4.3 Lesson 3: Use Many Cases in the Training Set
4.4 Lesson 4: Don't Use Hypothetical Cases in the Training Set
4.5 Lesson 5: Avoid Doctrinal Cases in the Training Set
4.6 Lesson 6: Be Careful of Contradictory Cases
4.7 Lesson 7: Choose Case Attributes Carefully
5. Conclusion
7. Further Reading :Legal Neural Network Papers
This paper argues that neural networks are an appropriate artificial intelligence technique for legal practice. It outlines the technical basics for neural networks, and shows that they can provide a useful statistical model for predicting the outcome of cases. The paper then reviews a number of legal theories which provide the legal basis for the use of neural networks in law. Finally, it presents seven lessons from research examples which practitioners must bear in mind if they wish to build successful legal neural networks.
This is a refereed article.
Date of publication: 7 May 1996
Citation: Hunter D (1996) 'Commercialising Legal Neural Networks', 1996 (2) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/elj/jilt/artifint/2hunter/>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1996_2/hunter/>
For many years lawyers have been using artificial intelligence techniques to assist in their practices, and by students and academics better to understand the law. Techniques from those as simple as flowcharts and word-processing macros, to the more complicated drafting assistance systems and legal expert systems, all rely in part on artificial intelligence theory. However these approaches share the common feature that they use explicit symbolic representation of law, and are consequently fairly easy for lawyers to use. After all, law schools teach law as a type of symbolic manipulation, and some go so far as to introduce classes on logic and argument.
More recently neural networks have emerged as an artificial intelligence approach which has utility in certain fields. Though a little neural network research has been done in legal domains, few practitioners have taken the leap into neural networks. Initially, this was largely due to the difficulty of using the technology. Nowadays there are numerous commercial neural network shells which take the sting out of commercial neural network creation. The absence of neural networks in law is therefore probably attributable to a lack of understanding of the technology, and uncertainty as to whether neural networks can generate results worth the effort of implementation.
In this paper I argue that the time is now ripe for practitioners to use the enormous power of neural network technology. In order to show this, I discuss three vital considerations in the commercial development of legal neural networks. The first consideration is the technology. The paper outlines the technical basics for neural networks, and shows that they can provide a useful statistical model for predicting the outcome of cases. The second consideration is whether the statistics at the heart of neural networks is consistent with legal reasoning. The paper therefore reviews a number of legal theories which show that neural networks are suitable in law, provided certain features are borne in mind. Finally, there are the practical issues in building legal neural networks. There is little point in spending large amounts of time and money on neural network implementation is the results are to be spurious. Therefore, the paper presents seven lessons from research examples which practitioners must bear in mind if they wish to build successful legal neural networks.
In keeping with the above aims, this paper is divided into five sections, including this introduction. The next section will sketch briefly the technical details of neural networks. Section three will explain the legal theories which are most relevant to neural network development. Section four will suggest some lessons from the theory and practice of neural networks, which commercialisers in the legal domain should take into account. Section five will provide a brief conclusion.
2. The Basics of Neural Networks
2.1 Neurodes [1]
The only genuine neural networks in existence occur in the brains of all animals, including humans. Artificial neural networks seek to mimic certain features of neurophysiology [2] . The artificial neurons are often called 'neural nodes' or 'neurodes'. Neurodes are connected to each other by 'links', each of which have an associated weight. The total input to a neurode is the sum of all the weighted inputs to that node. This input is measured against a threshold function or activation level, and if the input exceeds the threshold then the neurode 'fires'. When the neurode fires it passes a full strength signal, viz a 1, to the output.
A diagram showing this process is given in figure 1.
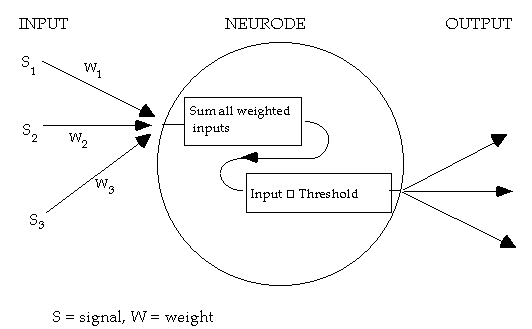
Figure 1: Basic neurode structure
This may become clearer with an example. Let us say that we wish to model the practice of a given court in granting bail to an offender. Let us simplify the domain by limiting it to include a small number of relevant factors—say, if the crime was one committed with violence, and whether the defendant has prior convictions. We could represent our simplified bail system by a simple type of neural network which only has two inputs (crime_with_violence and prior_convictions) and one output (bail_granted) and uses only one neurode:
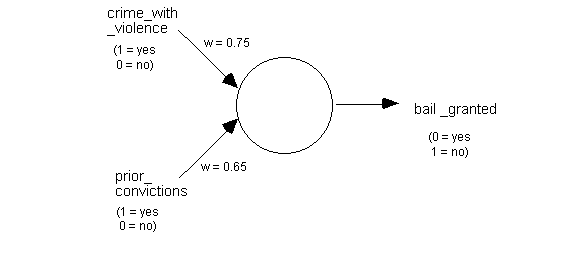
Figure 2: Simple bail neurode
Looking at the diagram, if the offender is positive to both factors (crime_with_violence and prior_convictions) then each of the signals on the inputs will be 1 and this will be multiplied by the appropriate weights. Hence:
(1 x 0.75) (1 x 0.65) = 1.4
If the threshold value on the neurode is 1, then the neurode will pass a signal of 1 to the output and this simple network will suggest that the offender should not be bailed (since 1 means ‘no’ on the bail_granted output. Alternatively, if the offender only has prior convictions but has not committed a crime with violence then the calculation will be:
(0 x 0.75) (1 x 0.65) = 0.65
If the threshold value on the neurode is again 1, then the neurode will not fire, and the network will predict that the offender be bailed. The calculations, of course, depend on the values for the threshold and the weights. These values come from the training process which we will examine shortly. However before we do so, we need to see how we can use these neurodes to build more sophisticated networks.
Neurodes are connected in large arrays which form 'networks.' Various configurations are possible, but the most common is called a feed-forward network, which usually comprisesthree layers [3] . The first layer provides the input nodes, the second layer is known as the 'hidden layer' and assists in the 'reasoning' of the network, and the third layer contains the output nodes. In this configuration every neurode of a layer is connected to every neurode of adjacent layers. An example of a network—that again might be used for bail hearing predictions—is given in figure 3. Note that weights, signals, thresholds, etc are not shown.
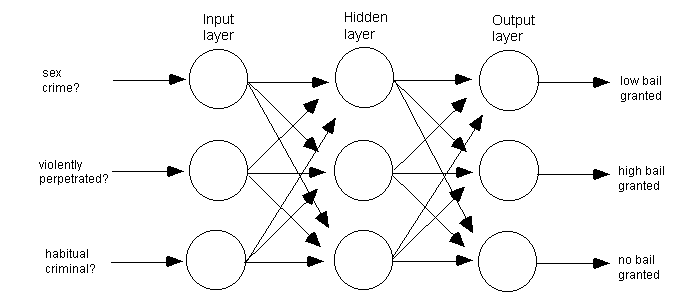
Figure 3: Example three layer, feed forward network
In order to specify relevant weights on each of the arcs, the system must be trained (Fausett L V 1994, pp. 294-300; Rose D E & Belew R K 1991, pp. 20-21). This involves presenting the network with a large training set of previously decided cases. The network is then asked to re-evaluate the weights on the arcs by matching the inputs and the outputs of all the training set cases, in a process called 'back propagation.' This involves initially assigning random numbers on the arcs, presenting the network with the same inputs as a known case in the training set, comparing the output from network with the known result, repeating the process for each case in the training set, and changing the weights. This occurs repeatedly until the difference between the results from the training set and the neural network’s prediction of the output of the training set cases is very small. At this point the network is said to be trained, and can then be used to assess other cases the outcomes of which are not known.
Returning to our bail example will make this clearer. Looking at the network in figure 3, let us say that the initial random weights are wrong—a state which is almost always the case. This means that when the net is presented with the first case in the training set—for example, a sex crime, committed with violence by an habitual criminal—it will generate an outcome which does not match the actual result—for example, it might suggest 'low bail' when the outcome is actually 'no bail.' To make the inputs and outputs match, it is necessary to change the weights until the input and output nodes on the network match the case in the training set. Then the next case is presented, and the same process occurs. This occurs many times (typically thousands of iterations of the entire training set) until the network accurately predicts all of the bail cases in the training set.
The important aspect to note from this is that the system is producing a sophisticated statistical model of the domain. The weights on the links are modified according to statistical methods (the details of which need not concern us). Consequently there are a number of assumptions which must be made about the domain that are due to the network’s statistical nature. We will return to this point in section four.
We need to look at a legal theory which one might use for neural networks. For if an inappropriate legal model is used which does not match these two assumptions, then the output from the network will be useless. Thus the next section is about legal theory.
3. Legal Theory for Neural Networks
Neural networks use statistics to derive their conclusions. Hence we need to be careful not to use an approach to law which represents legal cases in a way that is inconsistent with statistics. Instead we must see whether statistical methods fit with our conceptions of how cases are decided.
Statistical methods can be quite suitable for law depending on the purpose for which we use them and the model of legal reasoning which we adopt. The concern we might have with statistical techniques is that they provide no normative basis for decision-making, and they fail to capture any element of the abstract reasoning of judges. As to the first point, we can merely suggest that provided we seek only to define a descriptive model of adjudication, then there is no concern with this approach. At this point we seek merely to generate a model of adjudication which is consistent with prior decisions and which is an accurate predictor of subsequent decisions. This stems from the work of the American legal realists who set out to challenge the doctrinal rules on the basis that they were inadequate predictive models of judicial decision-making. The legal realists were equally suspicious of the 'abstract reasoning of judges,' since they recognised that judges very often fail to articulate the actual motivations for decisions. Whether one accepts these theorists, as commercial developers we care little how judges should decide cases and care only about a model of how judges do decide cases.
The legal realists lead to two movements which have relied heavily on statistical analysis of law: the behaviourists and subsequently the socio-legal theorists. The behaviourists began as a movement during the 1960s and 1970s and are distinguished by their use of sophisticated statistical techniques in analysing adjudication. Theorists like Kort (Kort 1963a; Kort 1963b; Kort 1965), Lawlor (Lawlor 1963; Lawlor 1964; Lawlor 1968; Lawlor 1972), Nagel (Nagel 1960; Nagel 1963) and Schubert (Schubert 1964; Schubert 1968) all showed statistically significant correlations in appellate court decisions between the political attitudes of judges and the outcomes of cases in their courts. At times the correlation was strained or the model presented was inadequate to predict a likely change in the basic doctrinal analysis. However their work showed that even in the unusual arena of appellate court decision-making one could use statistical models to predict decision-making [4] .
More recently has been the growing importance of the work of the socio-legal theorists, see for example (Ingleby R 1993; Johnstone R 1995; McBarnett D 1981). This can be contrasted with the above work in that it tends not to examine judicial decision-making at appellate court level but rather is concerned with empirical studies of lower court decision-making. Socio-legal studies show that lower jurisdictional courts follow distinct patterns in decision-making which are both different from the appellate court decision patterns and often differ from the stated doctrinal legal position. These theorists largely reject abstract black-letter analysis of law in favour of seeing how law actually operates in practice. This work also relies heavily on statistical analysis—usually statistical regression analysis which shows the statistical correlation between variables.
Both the behaviourists and the socio-legal theorists provide the basis for adopting a statistical model of legal reasoning, at least as a descriptive analysis. They also provide a theory which verifies the practitioner’s intuitive understanding that judges often decide cases for reasons having little to do with the law, and a lot to do with their political stripe, the 'smell' of the case, or the respective physical charms of the plaintiff and defendant. As Judge Jerome Frank said:
'[W]hen pivotal testimony at the trial is oral and conflicting, as it is in most lawsuits, the trial court’s 'finding' of the facts involves a multitude of elusive factors' [T]he trial judges or juries, also human, may have prejudices' often unconscious, unknown even to themselves' for or against some of the witnesses, or the parties to the suit, or the lawyers.'(Frank J 1963)Hence, if we are to build neural networks which accurately predict the outcome of undecided cases we must first identify the case-features that will be important to all the relevant judges. We do not have to assess the importance of these features, since the neural network will do this for us. The neural network can then accurately predict the outcome of these new cases.
Unfortunately many of the implementations to date have not recognised this point—that legal doctrine is not as important as legal reality. Further they have not realised that neural networks, like all statistical systems need a great many cases. Hence the reported research has been limited, and gives the impression that neural networks are of no use in law. I have reviewed these implementations elsewhere and don't wish to return to those criticisms. The interested reader is referred elsewhere [5] .
There are a number of general lessons which stem from the attempts made at legal neural networks, and also from the observations made in the previous two sections of this paper. These lessons are important to those who intend to build useful neural networks for legal practice.
4. Lessons for legal neural network development
The lessons about building commercial legal neural networks break into two main issues:
the nature of neural networks and the nature of the training set. On the nature of neural networks there are two lessons: (1) that neural networks classify cases; and (2) that neural networks can’t explain their conclusions. On the question of the training set, there are an additional five lessons, to wit: (3) use many cases in the training set; (4) don’t use hypothetical cases; (5) avoid doctrinal cases; (6) be careful of contradictory cases; and (7) choose attributes carefully.
Lesson 1: Neural networks classify cases
Neural networks have performed well in classification and recognition of 'objective' sensory data. The statistical basis of the paradigm means that it is very good at making correlations between a new pattern and a previously trained one. In law we might expect neural networks to perform similar tasks equally successfully. Neural networks can perform useful pattern matching by 'recalling' a previous identical case to the one at bar, see for example (Hobson J B & Slee, D 1994). Further, a network’s statistical basis allows it to recognise associations between related cases by increasing the weighting on the links which correspond to these cases. In this way the neural network can perform classification-type processing. If presented with a sufficient number of cases which contain similar attributes and values, together with relevant outcomes, the neural network can classify these cases as being of one type. For example, if we built a neural network to predict outcomes in contract law, 1000 cases containing the inputs of offer and acceptance with outcome of valid_contract would create a strong classification regime [6] . Then, when presented with a new case (offer = yes and acceptance = no), it will 'recognise' this case as falling within this classification and return the appropriate outcome (valid_contract = no).
This is useful for those seeking to build neural networks to classify a large number of cases, without being aware of which features are the most relevant. Developers don’t have to choose which case-attributes are most relevant, as the network will do this for them. However, they must have a sufficiently large body of cases to classify with any degree of confidence.
This does present a problem however, as it means that neural networks are not good for presenting cases. As an advocate, one wants a set of arguments, a number of analogies and the most relevant cases for an against your client. Neural networks cannot do this, as they really only provide one result for each input, based on classification of the entire training set. Developers must therefore not expect the network to do any more than this.
Lesson 2: Neural networks can’t explain worth a damn
Any practitioner/developer must be aware that neural networks are the quintessential black box. That is, for a given set of inputs they will generate a consistent set of outputs; but the reasons why the outputs are generated are a complete mystery. Unlike symbolic approaches in expert systems, one cannot ask for the rule used to derive the conclusion. If one asks a neural network 'Why,' it will, like a five-year old, say 'Because.'
Hence a legal neural network cannot explain to the lawyer why this conclusion is valid. All of their 'intelligence' is in the weightings on the links between neurodes. This information is not of a type amenable to symbolic manipulation and hence explanation. The lawyer asking the network why it came to the conclusion it did is going to be very disappointed when it can provide no justification [7] .
This observation leads to certain important criteria for practical legal neural networks. We must choose a domain where explanation is either irrelevant or provided by some other method. For example, neural networks will be appropriate where we want a quick predictive model of how a judge is likely to decide a crash-and-bash case, a property split in a divorce, and bail decision, sentencing, or the like. This type of 'quick-and-dirty' model can provide important first-pass information to assess a client’s chances. This is particularly relevant where the firm has a large number of junior lawyers who might not yet have accumulated the experience which makes a good lawyer’s 'intuition.'
Alternatively, we could attempt use neural networks as a model of outcomes which depend on a certain case-feature. For example it may be a useful tool for a lawyer to play 'what-if' with the network. 'What-if this attribute was present?' “what-if we didn’t have this attribute.' If the outputs in these cases differ, when all that has changed is one attribute, we have a strong indication that this attribute is the one on which the case may well turn.
Hence, intelligent research and argument on that point could well be the difference between a good and a bad result. Thus, the absence of explanation in the neural network is unnecessary, and is instead supplemented with human explanation.
Lesson 3: Use many cases in the training set
The training set comprises the basis for the knowledge of any neural network, unlike symbolic systems where the encoded rules provide the intelligence. Thus, if we are to generate anything of value from a neural network, we must be careful in choosing the information encoded in the training set [8] .
The first point to bear in mind is the sheer number of cases which neural networks require in order to train properly (Fausett L V 1994). This is due to their statistical underpinnings—it is impossible to adjudge any feature as statistically significant unless it is seen in a vast range of cases. Thus, ideally a neural network needs thousands, or at least hundreds, of cases to learn properly. Alternatively we could use 'prototypical cases' which are supposed to be representative of all cases in the domain,[9] but there are problems with this type of approach.
To illustrate let us say that we seek to create a neural network to assess whether a driver will lose her licence to drive because she was drunk while driving. It has two inputs (drive and drunk) and one output (licence_loss). Let us say we can train the network using only two prototypical cases:
Case 1: The driver was drunk and driving and lost her licence.
Case 2: The driver was not drunk and did not lose her licence.
If we train the network with sufficient repetitions, it will generate the expected answer. However, if we are relying only on prototypical cases, that is the existing doctrinal rules, why use a neural network when we could use a production rule system (IF drunk AND driving THEN licence_loss)? This is more computationally efficient, and at least we can query the system as to why it generated the answers it did.
The conclusion then is where there are a small number of cases, developers would be better off using traditional rule-based expert system technology (Zeleznikow J & Hunter D 1994, chaps 6 and 10) or even the newer symbolic case-based approaches (Zeleznikow J & Hunter D 1994, chaps 7 and 8). Where there are many cases, neural networks come into their own.
Lesson 4: Don’t use hypothetical cases in the training set
There is another training set feature which keeps appearing in legal implementations—the use of hypothetical cases. Due largely, it seems, to the need for large training sets and the difficulty of obtaining such large sets in law, implementors have chosen to supplement their training sets with hypothetical cases [10] .
'Padding' the training set with hypotheticals seems at first benign, until we consider that these cases are derived from a rule. That is, a rule is specified (for example , IF drunk AND driving THEN licence_loss) and then cases are generated in huge profusion which satisfy the rule. The effect of this upon training the network is, once again, to have the network simulate a doctrinal symbolic rule-based system. Since neural networks have the potential to operate extremely well using legal theories based on statistics, it is quite remarkable that researchers persist with naïve doctrinal analysis in justifying their conclusions.
Again, like the last lesson, when building commercial neural networks in law, avoid hypothetical cases as a basis for padding the training set. If there are so few cases in the domain that hypothetical cases appears appropriate, then it would be better to investigate other artificial intelligence approaches.
Lesson 5: Avoid doctrinal cases in the training set
The blind adherence to doctrine in neural networks is not limited to the use of hypothetical cases in the training set. When one looks at the genuine cases used in a system such as Hobson and Slee (Hobson J B & Slee D 1994) one sees that they use the leading cases of the domain. Since leading cases are exceptional using them as the basis for statistical analysis is virtually guaranteed to generate poor conclusions. Should we not then try to avoid implementing in a neural network that disease which Frank memorably diagnosed as 'appellate-court-itus'?(Frank J 1963) That is, ignoring lower court decisions which are amenable to statistical modelling, and instead concentrating on upper court cases which are not amenable to this type of analysis. Using neural networks intelligently means that we must choose a domain where the descriptive power of the paradigm can be used. These domains will be where there are large corpora of similar cases, and they are likely to be found in the lowest level courts of first instance.
These domains, like car accidents, marital dissolutions and work related injuries, are much more likely to give us the basis for meaningful networks than upper court areas like theft, murder, and so on.
Where commercial developers are assessing the domain, be aware that 'upper court domains' are unlikely to be appropriate for neural networks.
Lesson 6: Be careful of contradictory cases
Philipps (Philipps L 1991) identifies the means by which neural networks handle contradiction: contradictory cases simply lower the weightings on some of the links. So for example, if we have a number of cases which indicate a positive outcome, and one case which indicates the contrary, we will see the weight reduced on the link associating the facts with the positive outcome.
Contradictory cases arrive in many ways, but two are of particular relevance to our discussion. The first is where neural network developers have chosen to use doctrinal cases in the training set, and these appellate-court cases inevitably conflict, and change over time. New leading cases may well contradict old cases, even where there is no explicit overruling. This particular concern is not one which can be remedied by neural network technology, but instead can be fixed by accepting lesson five above. By not relying on doctrinal cases we can avoid the all-too-common contradictions, which would prove fatal for neural networks. The second type of contradiction is likely in lower court cases, where one or a number of judges decide cases according to criteria which other judges reject. For example, judges may have completely different political biases which influence their decision-making. This concern is actually one which does not trouble neural networks, but rather demonstrates one of their strengths. We can explicitly represent the names of judges as a relevant attribute for the outcome of the case, and provide this as an input node for the network. By this technique, we can predict the outcome of two different cases which are identical in all respects but for the name of the judge and the eventual outcome. This is an example where the network can actually provide an accurate prediction of judicial bias.
Lesson 7: Choose case attributes carefully
Developers need to be wary of what input neurodes represent. Intelligent identification of relevant input nodes can provide weight to alternative theories about a given legal domain. For example in death penalty cases, rather than expressing what the judges say are the important criteria in assessing whether the death penalty is appropriate (for example, 'violence' or 'previous convictions' and so on), the system may give credence to what we think might be better explanatory features (for example, what are the races of the defendant and victim). We may find that the neural network generates accurate predictions of outcomes, without reference to the doctrinal basis. This is, of course, a sketch of the approach of the socio-legal theorists, and commercial neural network developers would be advised to see how these theorists approach the analysis of their domain.
There is currently available a great many easy-to-use, commercial neural network shells available. This is both a blessing and a curse; a blessing since it provides practitioners with a real opportunity to build useful neural networks which can be of commercial utility in predicting the outcome of legal cases. It is something of a curse because their ease-of-use may mask some vital issues necessary to build them.
However, I believe that the time is now ripe for legal practitioners to begin applying neural network technology to their practices. Provided that practitioners recognise the nature of neural networks and use appropriate cases in the training set, there is no reason why legal neural networks cannot give a competitive advantage in these difficult commercial times.
Thanks go to the following people who read and commented on previous incarnations of this work: at the University of Melbourne Law School—Richard Ingleby, Richard Johnstone and David Hamer; at LaTrobe University, Department of Computer Science—Andrew Stranieri, Mark Gawler and John Zeleznikow; at the Centre for Law and Computing, Durham University—Michael Aikenhead; at the University of Liverpool, Department of Computer Science—Trevor Bench-Capon; at the University of Edinburgh, Faculty of Law— Lilian Edwards; and to those faculty members and delegates who commented on an earlier work at the Seventh Dutch Conference on Legal Knowledge Based Systems at the Universiteit van Amsterdam, December 1994;
Finally, thanks to Dr Herchel Smith, whose endowment of my fellowship at Emmanuel made this work possible.
7. Further Reading: Legal neural network papers.
Bench-Capon T J M (1993). Neural networks and open texture. In the Proceedings of the Fourth International Conference on Artificial Intelligence and Law, pp. 292-297, Amsterdam: ACM Press.
Birmingham R (1992). A study after Cardozo: De Cicco v. Schweizer, noncooperative games and neural computing. University of Miami Law Review 47: pp. 121-145.
Bochereau L, Bourcier D,& Bourgine P (1991). Extracting legal knowledge by means of a multilayer neural network application to municipal jurisprudence. In the Proceedings of the Third International Conference on Artificial Intelligence and Law, pp. 288-296, Oxford: ACM Press.
Groendijk C & Oskamp A (1993) 'Case recognition and strategy classification.' In the Proceedings of the Fourth International Conference on Artificial Intelligence and Law, pp. 125-132, Boston: ACM Press.
Hobson J B & Slee D (1993) Rules, cases and networks in a legal domain. Law, Computers and Artificial Intelligence 2(2):119-134.
Hobson J B & Slee D (1994) 'Indexing the Theft Act 1968 for case based reasoning and artificial neural networks'. In the Proceedings of the Fourth National Conference on Law, Computers and Artificial Intelligence, unnumbered additions, Exeter: Exeter University Centre for Legal Interdisciplinary Development.
Hunter D (1994) 'Looking for law in all the wrong places: Legal theory and legal neural networks'. In Prakken, H., Muntjewerff, A.J. Soeteman, A. and Winkels, R. (eds) Legal knowledge based systems: The relation with legal theory, pp. 55-64, Lelystad: Koninklijke Vermande.
Philipps L (1989) 'Are legal decisions based on the application of rules or prototype recognition? Legal science on the way to neural networks'. In the Pre-Proceedings of the Third International Conference on Logica, Informatica, Diritto, p. 673, Florence: IDG.
Philipps L (1991) 'Distribution of damages in car accidents through the use of neural networks'. Cardozo Law Review 13:987-1000.
Raghupathi W et al (1991). Exploring connectionist approaches to legal decision making. Behavioural Science 36:133-139.
Rose D E & Belew R K (1989). 'Legal information retrieval—A hybrid Approach'. In the Proceedings of the Second International Conference on Artificial Intelligence and Law, pp. 138-146, Vancouver: ACM Press.
Rose D E and Belew R K 1991. A connectionist and symbolic hybrid for improving legal research. International Journal of Man-Machine Studies 35(1):1-33.
Rose D E (1994) A symbolic and connectionist legal information retrieval system. Hillsdale: Lawrence Erlbaum.
Terrett A (1995) 'Neural networks—Towards predictive law machines', International Journal of Law and Information Technology 3(1): pp. 95-111.
Thagard P (1991) Connectionism and legal inference. Cardozo Law Review 13:1001-1004.
van Opdorp G J & Walker R F (1990).' A neural network approach to open texture'. In Kasperen H W K & Oskamp, A. (eds), Amongst Friends in Computers and Law, Deventer: Kluwer Law and Taxation.
van Opdorp G J, Walker RF, Schrickx J A, Groendijk C & van den Berg P H (1991). 'Networks at work: a connectionist approach to non-deductive legal reasoning'. In the Proceedings of the Third International Conference on Artificial Intelligence and Law, 278-287, Oxford: ACM Press.
Walker R F, Oskamp A, Schrickx J A, Opdorp G J & van den Berg P H (1991). 'PROLEXS: Creating law and order in a heterogeneous domain.' International Journal of Man-Machine Studies 35(1):35-68.
Warner D R (1989) 'Towards a simple law machine'. Jurimetrics 29:451-467.
Warner D R (1990). 'The role of neural networks in law machine development.' Rutgers Computer and Technology Law Journal 16:129-144.
Warner D R (1992) 'A neural network based law machine: Initial Steps'. Rutgers Computer and Technology Law Journal 18:51-63.
Warner D R (1993) 'A neural network-based law machine: The problem of legitimacy'. Law, Computers and Artificial Intelligence 2(2):135-147.
Andersen J A & Rosenfeld E (eds) (1989), Neurocomputing: Foundations of research (Cambridge: MIT Press).Bench-Capon T J M (1993), 'Neural networks and open texture' in Proceedings of the Fourth International Conference on Artificial Intelligence and Law, (Amsterdam: ACM Press), p. 292;
Bochereau L, Bourcier D & Bourgine P, (1991) 'Extracting legal knowledge by means of a multilayer neural network application to municipal jurisprudence' in Proceedings of the Third International Conference on Artificial Intelligence and Law, (Oxford: ACM Press), p. 288.
Fausett L V (1994), Fundamentals of neural networks: Architectures, algorithms, and applications (Englewood Cliffs: Prentice-Hall).
Frank J (1963) Law and the modern mind (Garden City: Anchor Books) xii-xiii.
Hobson J B and Slee D, (1994), 'Indexing the Theft Act 1968 for case based reasoning and artificial neural networks' in Proceedings of the Fourth National Conference on Law, Computers and Artificial Intelligence, (Exeter: Exeter University Centre for Legal Interdisciplinary Development), unnumbered additions.
Hunter D (1994), 'Looking for law in all the wrong places:Legal theory and legal neural networks,' in Prakken H, Muntjewerff A J, Soeteman A & Winkels R (eds) Legal knowledge based systems: The relation with legal theory, pp. 55-64, (Lelystad: Koninklijke Vermande).
Ingleby R (1993) Family law and society (Sydney: Butterworths);
Johnstone R (1995) 'The court and the factory: The legal construction of occupational health and safety offences in Victoria', Unpublished PhD diss., Law School, University of Melbourne;
Kort F (1963a), 'Content analysis of judicial opinions and rules of law' in Judicial decision-making, International Yearbook of Political Behavior Research, (Schubert, G. (ed), New York: Free Press of Glencoe) vol. 4, 133.
Kort F (1963b), 'Simultaneous equations and boolean algebra in the analysis of judicial decisions' 28 Law and Contemporary Problems 143.
Kort F (1965) 'Quantitative analysis of fact patterns in cases and their impact on judicial decision’ 79 Harvard Law Review 1595.
Lawlor R C (1963), 'What computers can do: Analysis and prediction of judicial decisions' 49 American Bar Association Journal 337.
Lawlor R C (1964), 'Stare decisis and electronic computers' in Judicial behavior: A reader in theory and research, (Schubert, G. (ed), Chicago: Rand McNally), 503.
Lawlor R C (1968), 'Personal stare decisis' 41 Southern California Law Review 73.
Lawlor R C (1972), 'Fact content of cases and precedent—A modern theory of precedent' 12 Jurimetrics Journal 245.
Luger G F & Stubblefield W A (1993) Artificial intelligence: Structures and strategies for complex problem solving (2nd ed, Redwood City: Benjamin Cummings), pp. 516-26;
McBarnett D (1981) Conviction: Law, the state, and the construction of justice (Oxford: Clarendon Press).
McClelland J, Rumelhart D & the PDP Research Group. (1988), Parallel distributed processing: Explorations in the microstructure of cognition (Cambridge: MIT Press);
Nagel S S (1960) 'Using simple calculations to predict judicial decisions' 4 American Behavioral Scientist 24.
Nagel S S (1963), 'Off-the-bench judicial attitudes' in Judicial decision-making, (Schubert, G. (ed), New York: Free Press of Glencoe), 29.
Philipps L (1991) , 'Distribution of damages in car accidents through the use of neural networks' 13 Cardozo Law Review 987, 996.
Popple J (1993) , 'SHYSTER: A pragmatic legal expert system' Unpublished PhD diss., Department of Computer Science, Australian National University, pp. 23-27.
Rose D E & Belew R K (1991), 'A connectionist and symbolic hybrid for improving legal research' 35 International Journal of Man-Machine Studies 1.
Schubert G (ed), (1964), Judicial behavior: A reader in theory and research (Chicago: Rand McNally & Co).
Schubert G (1968), 'The importance of computer technology to political science research in judicial behavior' 8 Jurimetrics Journal 56.
Stranieri A & Zeleznikow J, (1992), 'SPLIT-UP—Expert system [sic] to determine spousal property distribution on litigation in the Family Court of Australia 'in the Proceedings of the Fifth Artificial Intelligence Congress, (Hobart: World Scientific), p. 51.
Stranieri A, Gawler M & Zeleznikow J (1994), 'Toulmin structures as a higher level abstraction for hybrid reasoning' in Proceedings of the Seventh Australian Joint Conference on Artificial Intelligence, (Zhang, C., Debenham, J and Lukose, D. (eds), Armidale: World Scientific), p. 203.
Warner D R (1990), 'The role of neural networks in law machine development' 16 Rutgers Computer and Technology Law Journal 129.
Warner D R (1992), 'A neural network based law machine: Initial steps' 18 Rutgers Computer and Technology Law Journal 51.
Warner D R (1993), 'A neural network-based law machine: The problem of legitimacy' 2 Law, Computers and Artificial Intelligence 135.
Winston P H (1992), Artificial intelligence (3rd ed, Reading, Addison Wesley), pp. 443-69.
Zeleznikow J & Hunter D (1994), Building intelligent legal information systems—Representation and reasoning in law (Deventer: Kluwer Law & Taxation).
Zurada J M (1992) Introduction to artificial neural systems (St Paul: West Publishing).
Footnotes
[1] For further technical details of neural networks, see (Andersen J A & Rosenfeld E (eds) (1989); Fausett L V (1994); Luger G F & Stubblefield W A (1993) ; McClelland J, Rumelhart D. & the PDP Research Group.1988; Winston P H (1992); Zurada J M (1992)).[2] Hereafter, the term 'neural network' will refer to artificial neural networks only.
[3] I will only consider feed-forward, three layer networks in this paper, though many other types of neural networks exist. I do so since this type of neural network (1) is simple; (2) has commercially available shells; and (3) provides the best type of simple predictive network. I should also note that I use the convention of describing the networks by the number of node layers (therefore 'three layer') rather than the number of reasoning arc layers ('two layer' in this case).
[4] For a more detailed analysis of the theories of the behaviourists in the context of legal expert systems see (Popple J 1993).
[5] An extensive bibliography is included in section seven. For an analysis of those implementations, consistent with this paper, see (Hunter D 1994).
[6] This example is based on a network built by Professor David Warner, see (Warner D R (1990); Warner D R (1992); Warner D R 1993).
[7] Some researchers suggest analysing the weights of the neural network links in order to derive symbolic information, for example (Warner 1993), (Bench-Capon T J M, 1993), (Bochereau L, Bourcier D & Bourgine P (1991)). I have argued elsewhere that this approach is flawed, see (Hunter D 1994). Flawed or not, these approaches are not currently commercialisable.
More interesting approaches to resolve the problem (which are also not commercialisable) suggest integrating rule-based expert systems with neural networks; see for example (Stranieri A, Gawler M & Zeleznikow J 1994); (Stranieri A & Zeleznikow J, 1992 p. 51).
[8] Unfortunately, this has been perhaps the greatest failing on the part of the legal neural network implementors, see (Hunter D, 1994).
[9] Philipps suggests that there are 'prototypical' cases which define the subject matter: (Philipps L, 1991). He argues that if one uses only, or mostly, these prototypical cases then one can train a neural network to generate the correct answer.
[10] Some implementations add hypothetical cases to genuine ones, for example (Hobson JB & Slee, D 1994), while others rely only entirely on hypotheticals, for example (Warner D R 1990), (Bench-Capon T J M (1993)). The distinction is immaterial.
