
JILT 1996 (2) - De Mulder & Combrink-Kuiters
Is a computer capable of interpreting case law?
Prof. R.V. De Mulder (mulder@rrj.frg.eur.nl)
and C.J.M. Combrink-Kuiters (combrink@rrj.frg.eur.nl)
Contents
2. Introduction
3. The cases
4. The determination of the legal item
5. The mathematical technique of the experiment
6. First results
7. The calculation of the model leaving out one of the decisions each time (n-1 method)
8. The prediction of a case using its information alternatively both as a positive and as a negative case (actual/reversed method)
9. The results compared
10. Another validity check
11. An alternative approach to the custody set
12. Conclusion
References
This is a refereed article.
Date of publication of this version 1.1: 7 May 1996.
Original version was published on 31 January 1996.
Citation: De Mulder, R.V. & Combrink-Kuiters, C.J.M. (1996) 'Is a Computer Capable of Interpreting Case Law?' (version 1.1), 1996 (2) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/elj/jilt/issue2/11demldr/>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1996_2/mulder/>
The availability of legal texts in electronic form provides us with enormous opportunities for legal research. At present only a selection of verdicts (law reports) is available on CD ROM, consisting mainly of selected parts of verdicts reached by the Supreme Court.
In the near future the complete texts of all the verdicts of the Supreme Court and a selection of lower courts verdicts will be electronically accessible. This will give a new stimulus to jurimetrical research because some techniques can be applied only on digitised material.
One of these techniques, a 'conceptual' one, has been used in our research project on the prediction of judicial verdicts. The technique can be applied at various stages in the research:
- the collection of the court cases,
- the searching and coding procedure to distinguish the relevant facts within these cases and finally,
- the predicting of the outcome of these cases.
Some possibilities of the application of these conceptual (retrieval) techniques will be described in this paper. Particular attention is paid to the question of whether a conceptual technique is capable of deciding whether cases could be classified as 'positive' or 'negative' in the light of a specific legal item. In other words, whether a computer could interpret legal cases with respect to their outcome.
In a jurimetrical research project which has been carried out at the Centre for Computers and Law at the Erasmus University Rotterdam, an effort has been made to obtain empirical knowledge on judicial decision-making.
This project is aimed at predicting judicial verdicts. One way to reach this goal is by determining which facts are the most important and to what extent and in which direction these facts influence the outcome of court cases.
This is done by using the texts of previous verdicts as a source of information. With the help of this information, an assessment can then be made of which facts are really of influence in reaching a particular decision. This knowledge can then be used to predict court decisions with the help of a statistical model {eg Pipers et al 1993}.
The technique is extremely time consuming. First, the cases must be selected and a list of potentially important factors must be drawn up. Then for all cases and for all factors it has to be assessed, whether the factor on the list is present or not present.
This article describes a specific experiment which was part of our recent attempts to reduce the enormous amount of manual 'coding' work by using an automated technique. The method used could help to determine which cases have a positive and which cases have a negative decision.
It is hoped that if the computer model works for the coding of the decisions, it could also work with respect to the factors that determine those decisions.
The first step in this experiment was to collect a homogeneous set of relevant court cases. Before the search routine for the relevant cases could be put into operation, it was necessary to define the specific legal subject of the research. For the statistical analysis it was desirable to collect as many comparable cases as possible on this subject. It was estimated that twenty cases would be the minimum.
For practical reasons we decided to use only verdicts which had been published in the 'Nederlandse Jurisprudentie'. This is a collection of cases which is, for one reason or another, of interest to a larger public. Those verdicts which have been published are usually of cases which have been referred to the Supreme Court (the 'Hoge Raad'). Verdicts of lower courts are rarely published.
In order to obtain a sufficiently homogeneous set of cases it was decided to use only the cases of the Supreme Court. One advantage of using the published verdicts of the Supreme Court is that they are available in a computerised format: being on CD ROM as a part of an electronic databank published by Kluwer Datalex. While this facilitated searching for cases on the chosen subject, it was also helpful for the experiment itself, i.e. the interpretation of the cases by computer.
After some preliminary research it was decided to focus on family law and two sets of cases were collected: one on custody conflicts containing 24 cases and one on visitation rights conflicts consisting of 38 cases.
The determination of the legal item
The term 'legal item' is used to indicate the specific subject upon which the judge makes a decision. The texts of the verdicts which were retrieved concerning custody and visitation rights conflicts could be interpreted from various perspectives.
For example, one possibility was to establish who - the father or the mother - was granted custody at the end of the procedure. A similar way to express this point of view would be to establish whether the non-custodial parent was granted custody and the child had to move from one parent to the other as a result of the verdict. Another possibility was to establish whether the Supreme Court followed the decision of the lower court in reaching a verdict.
For the sake of the statistical analyses it must always be possible to state unequivocally how the court decided upon the legal item. The legal items, therefore, had to be formulated clearly and completely. The legal item that was finally chosen for the first set of verdicts concerned the outcome from the point of view of the father in custody disputes - had he been successful in his attempt to obtain or maintain the custody of his child? The legal item for the second set of verdicts concerned the question of whether the non custodial parent was granted visitation rights by the court.
The mathematical technique of the experiment
Bayesian statistics are particularly suited to making decisions in conditions of uncertainty {see Lindley 1971}. The basic idea is that information changes the odds. For example, the information that a certain horse has hurt its leg (information X), will change the probability that it will win the race (fact F). The odds after the information are nevertheless a function of the original (or 'a priori') odds.
Bayes says, that;
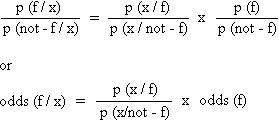
in which p(f) means: the probability of F and p(x|f) means: the probability of X given F.
This is important because the expressions on the right of the equal signs are often known, whereas the odds on the left have to be ascertained. In other words, with information x it is possible to estimate to what extent the probability of f increases (or decreases), if the probability of x given f as well as that of x given not-f are known.
In the example of the horse, p(x|f) would mean: the probability that the horse had a hurt leg, given that it won. This probability is a very low one. The new odds, (odds(f|x)) would be considerably lower than the a priori odds (odds(f)).
In the same way as the fact that the horse's leg was hurt could be used as information in estimating the probability that it would win, so too the characteristics of a document, for example its word-use, could serve as information in 'predicting' the outcome of a case.
An advantage of documents is that they have many characteristics. Words, combinations of words and the properties of the sentence construction can provide indications (information x).
A computer program has been developed with the help of which the word-use of each document could be compared in order to produce a large series of p(x|f), in which x denotes the presence of a word and f denotes a positive decision and p(x|not-f) in cases of a negative decision.
When all these numbers have been aggregated for all documents it is possible to rank these documents according to the estimated probability of the outcome (odds(f|x)).
Those with the highest probability of being positively decided appear at the top of the list and those with the highest probability of being negatively decided appear at the bottom of the list. Two examples of such an ordering on the basis of the value of the odds are shown in the following section.
The application of the principles described above to our two sets of cases led to the following ranking of the cases.
Table 1: The ranking of the cases: on custody (n=24) and on visitation rights (n=38).
The most certainly predicted cases are either at the top of the list (positive prediction) or at the bottom (in case of a negative prediction). The cases in the middle are the 'weakest'. In the table shown above, both cases at the top are certainly predicted positive cases and both cases at the bottom, case number 24 and 38, are certainly predicted negative cases. All cases are predicted correctly.
An objection to this method of interpreting the texts by computer is that each case contributes to its own prediction. It might even be expected that this contribution is substantial because the number of cases is rather limited. In the following sections we will report on the results of two possible ways of coping with this problem. n the first method, we have left the decision of one of the cases out each time the model was calculated and, therefore, the ranking of each case was based solely upon the information of all other cases. In the second method both possible outcomes for each case - positive or negative - have been calculated with the original method described above and then it was decided which of the two outcomes would fit best.
The calculation of the model leaving out one of the decisions each time (n-1 method)
The information about the decision on the case itself was left out for each case consecutively and the model was calculated on the basis of the word-use in the remaining (n-1) cases. Each model was examined with respect to whether this particular case would then appear on the negative or on the positive side in the ranking.
In the following table two examples are shown of a positively decided custody case. The case itself was predicted on the word-use within the case, on the basis of the combination of the word-use and the outcomes of the other cases.
In the left-hand column the actual positive decision of case NJ81-237 is validated by the model: the case is between other positively decided cases. The right-hand column shows the positively decided case NJ69-021 set down on the 'wrong' side: between the negatively decided cases. If we would not know the outcome of this case we would, on the basis of this model, expect the decision in it to be a negative one.
Table 2: Two positively decided custody cases: both correctly and wrongly predicted.
In the following table an example is shown of two negatively decided custody cases: NJ90-732 and NJ89-054. The case in the left-hand column is more likely to be a positive one, although this prediction is rather weak (or uncertain).
Table 3: The prediction of two negatively decided custody cases: both wrongly and rightly.
Sometimes, when the cases appear in the 'grey' area between the positive and negative cases, the model does not clearly indicate the most likely outcome. An example is shown below: case NJ91-267.
Table 4: A negatively decided case in the middle band.
The results of this proceedure are shown in Table 5.
Table 5: The Results of the Application of the First Method (n-1), with and without using the a priori chance.
This table shows that many cases appeared in the category 'uncertain'. When this occured, we used the a priori chance - the overall probability for a positive or negative decision - as an additional criterion. From the set of custody cases it is known that 16 out of 24 cases (66.6%) were decided negatively. From the visitation rights set we know that in 25 out of 38 cases (65.8%) the judge decided negatively on the legal item.
Using the a priori chance, case NJ91-267 in table four will be predicted negatively because in general each case is twice as likely to be a negative one. [1]
The fact that so many cases appeared in the grey area can be seen as a weakness of this method. Without using the additional criterium the results are very poor (see also table 8).
The prediction of a case using its information alternatively both as a positive and as a negative case (actual/reversed method).
In the second approach, we calculated two models for both the possible outcomes of each case. The following table shows an example; the first column shows the model using the actual decision of case NJ81-237, and the second column showing the model after reversing this case into a negative decision (in the 10th place).
Table 6: Custody case NJ81-237 actual and reversed.
Both models were compared and the alternative that fitted best was selected. The fit was determined with the help of several criteria.
The first criterion was the prediction of the case itself. The positive alternative should appear between the positive cases, the negative between the negative cases. In the examples shown, both cases are on the right side, so in this example this criterion is not decisive. Therefore, we needed a second criterion: the overall consistency of the model.
When the whole model becomes irregular after reverse, with the positive and negative decisions contaminated instead of separated, the most regular alternative (in our example the model based on the actual decision) was chosen.
In this example this criterion did not help in selecting the best fitting model either. Both models are equally and maximally regular.
Therefore, a third criterion was needed: the strength of the prediction of the case involved. As described above, the most certain cases are at the top and at the bottom and the unreliable predictions are in the middle of the table. Using this criterion we were able to make a choice between the two models: in this example the left model was chosen.
After having made a choice between the two models it was determined whether the selected alternatives corresponded to the actual or to the reversed decision. In the example of case NJ81-237, the actual decision corresponded to the decision which fitted best. This procedure was followed for all the 24 custody cases and the 38 visitation rights cases.
In the following table an example is given of a negatively decided visitation rights case (NJ86-003) of which the reversed (positive) decision fitted better.
Table 7: Visitation rights case NJ86-003 actual and reversed.
With the help of the third criterion, the reversed model was chosen because in this model case NJ86-003 is nearer to the top of the list, in other words more certainly predicted.
The position of the case was calculated by dividing the ranking number of a negatively decided case by the total number of negatively decided cases and the ranking number of a positively predicted case by the total number of positive cases.
In the left-hand table, case NJ86-003 is in the 21th position (from the bottom) and the total number is 25, which gives a factor of 21/25=0.84. In the right-hand column the factor is 2/14=0.14. The model in which the case that has the lowest factor will be selected.
To measure the effectivity of the application of these three prediction methods, the results - the percentage of correctly predicted cases - were compared with the a priori chances of both sets of cases.
The first method, using the information of the case itself for the prediction, resulted for both sets in a clear division between the positive and the negative cases (see table 1: The ranking of the cases). The results of the two alternative methods are shown in the following tables.
Table 8: The results of the application of the first cross validation method (n-1) compared with the a priori chance.
| Set of cases | n | a priori chance | attainable improvement / relapse | predicted correctly | results vis-à-vis a priori chance | results vis-à-vis attainable improvement / relapse | |
| custody | 24 | 16 / 24 (67%) | 33% / 67% | 13 | 13 / 24 (54%) | -3 / 24 (-13%) | -13 / 67 (-20%) |
| visitation rights | 38 | 25 / 38 (66%) | 34% / 66% | 15 | 15 / 38 (39%) | -10 / 38 (-27%) | -27 / 66 (-41%) |
Table 9: The results of the application of the second cross validation method (actual/reversed) compared with the a priori chance
| Set of cases | n | a priori chance | attainable improvement / relapse | predicted correctly | results vis-à-vis a priori chance | results vis-à-vis attainable improvement / relapse | |
| custody | 24 | 16 / 24 (67%) | 33% / 67% | 18 | 18 / 24 (75%) | 2 / 24 ( 8%) | 8 / 33 (24%) |
| visitation rights | 38 | 25 / 38 (66%) | 34% / 66% | 24 | 24 / 38 (63%) | -1 / 38 (-3%) | -3 / 66 (-5%) |
These tables show that the application of the second cross-validation method gives the best results. The application of the first method gives a considerable relapse of 13% (actual 20%) and 27% (actual 41%). Only by using an additional decisive ctiterion for cases in the middel band (as shown in table four) did the first method show an improvement of teh correctly predicted verdicts compared to trhe prediction merely using teh a priori chance. In the set of 24 custody cases the a priori chance was exceeded by two cases: from 16 to 18, which is an improvement of 8% (actual 24%). In the visitation rights set the level of the a priori chance was exactly reached both being 25 cases out of 38 predicted correctly.
To check the validity of these methods we also applied the two ways of cross validation on to artificially created files. These files were equal to the original two, with the exception of the decision, which was attributed at random by the computer, according to the ratio of the a priori chances.
When we allowed each case to contribute to its own prediction, we obtained (like we did using the actual verdicts) a perfectly ordered ranking on the basis of the odds(f|x) with the positive cases on one side and the negative cases on the other.
The results of the application of the cross validation methods on the random set, however, are clearly worse than those obtained using the real decisions, which is shown in the two tables below.
Table 9: The results of the application of the first method (n-1) on the random set
| Set of cases | n | a priori chance | attainable improvement / relapse | predicted correctly | results vis-à-vis a priori chance | results vis-à-vis attainable improvement / relapse | |
| custody | 24 | 16 / 24 (67%) | 33% / 67% | 0 | 0% | -16 / 24 (-67%) | -67 / 67 (-100%) |
| visitation rights | 38 | 25 / 38 (66%) | 34% / 66% | 2 | 2 / 38 (5%) | -23 / 38 (-61%) | -61 / 66 (-92%) |
Table 10: The results of the application of the second cross validation method (actual/reversed) on the random set
| Set of cases | n | a priori chance | attainable improvement / relapse | predicted correctly | results vis-à-vis a priori chance | results vis-à-vis attainable improvement / relapse | |
| custody | 24 | 16 / 24 (67%) | 33% / 67% | 14 | 14/24 (58%) | -2 / 24 (-8%) | -8 / 67 (-12%) |
| visitation rights | 38 | 25 / 38 (66%) | 34% / 66% | 13 | 13 / 38 (34%) | -12 / 38 (-32%) | -32 / 66 (-48%) |
These tables show that when the results reached by the application of the cross validation methods on the real decisions are compared to the results of the procedure on the random decisions the outcomes of the real verdicts are much better.
Only by adding the additional a priori criterion in the first (n-1) approach do the random results reach an acceptable level (exactly the a priori chance).
An alternative approach to the custody set
As described in the determination of the legal item section, the texts concerning custody and visitation rights can also be analyzed from other perspectives. Therefore, in the custody set we also used as an alternative legal item whether the child had to move from one parent to the other as a result of the verdict. This occurred in 11 out of the 23 cases. [2]
The use of this item appears to give the best results so far. Not only was the ranking of the cases perfect as before, but also the application of the (n-1) method was better. When the a priori chance was used as an additional criterion, the gain was even substantial: 26% (versus custody: 8% and visitation: 0%). As the attainable improvement is 48% (the a priori chance is 52%), the actual result is over 50% (26/48).
The second cross validation method led to an equally favourable result: 18 out of 23 cases (78%) were predicted correctly. The random results of this alternative legal item, however, were similar to the results of the original custody item.
These results indicate that the word-use regarding this adjusted legal item for custody is more specific. However, further research will be necessary on this point.
Analyzing judicial decisions with the aim of predicting verdicts based on the factors which are present is an extremely time consuming task. Determining the list of facts, and particularly coding the verdicts, is labour intensive. All the cases have to be scrutinized at least several times to ascertain whether each factor is present or not. In this article, an attempt has been made to show that Bayesian statistics could be a useful aid in the interpreting of judicial decisions by computer.
The results reached by the application of the models described on two sets of court cases are equal to or better than the prediction on the basis of the a priori chance. The comparison with the results obtained using randomly attached decisions provides an extra validation of the technique.
In the near future, the same technique will be applied in an effort to reduce the time-consuming coding process needed for the statistical analyses of court cases. It is hoped that even with less than all the available cases coded, the computer could separate the cases in which a certain factor appears from the cases in which it does not. From the results of the experiment described in this article, it would appear that although further research is needed, this hope is not without empirical foundation.
It is early days for this research, but the possibility that the computer will be able to interpret case law one day could well be science fact rather than science fiction.
Combrink-Kuiters, C.J.M. and P.A.W. Piepers 1993 The Implementation of Predictive Capabilities into Legal Computer Advice Systems. Paper for The 8th Bileta Conference, 1st and 2nd April 1993, University of Warwick, Coventry. Proceedings of the Conference, pp. 63-72.
Combrink-Kuiters, C.J.M. and P.A.W. Piepers 1995 The Use of Information Systems in Research for the Acquisition of Knowledge. Pre-Proceedings of the Conference, Paper for Electronic Communications, The 10th Bileta Conference, 30th and 31st March 1995,Stathclyde Business School, University of Strathclyde, Glasgow, pp. 23-32.
Mulder De, R.V.,1984 Een model voor juridische informatica, Koninklijke Vermande bv
Mulder De, R.V., 1985 A Model for Legal Decision Making by Computer, Logica Informatica Diritto, preproceeding of conference, Florence.
Mulder De, R.V./Hoven, M.J. van den/Wildemast, C., October 1993. The concept of concept in conceptual legal information retrieval, Law Technology Journal vol. 3, no. 1.
Lindley, D.V., 1971. Making Decisions, 2nd. edition, John Wiley and Sons, London.
P.A.W. Piepers and Combrink-Kuiters, C.J.M. 1994. Statistically Analysing Court Decisions on Custody Disputes. Paper for The 9th Bileta Conference, 11th and 12th April 1994, University of Warwick, Coventry. Proceedings of the Conference, The Changing Legal Information Environment, pp. 65-72.
Piepers, P.A.W., Combrink-Kuiters, C.J.M., and R.V. DeMulder, 1993. Towards a Statistical Model for Knowledge Representation; Predicting Court Decisions on Custody Disputes, Florence Conference, 1-3 December
Salton G, 1989. Automatic Text Processing; The transformation, Analysis, and Retrieval of Information by Computer, Addison-Wesley Publishing Company, US.
Footnotes
1. These percentages are also used as the lower boundaries of correct predictions which a model should be able to provide (see section 7.).
2. One of the 24 cases had to be removed from the list because the child was living with both parents in turn.
