
JILT 1997 (2) - AustLII Paper 2
2. Managing large scale hypertext databases
This paper discusses the AustLII system from a technical perspective, in contrast to the ?user perspective? of the Introduction. It sets out the history of the system, some of the approaches that we use and some current ideas for future development.
Contents
2.1. Technical History
The initial problem was that although we needed to plan for the creation of a very large database service, we had to achieve a production level system within a very short time frame. Our funding was for the period of one year and was fairly limited. In this time, we had to establish the hardware infrastructure, recruit staff, write the software, gather permissions to publish the data, commission a production level service, and create enough of a user base to justify continuing operations and funding.
Whilst the task was fairly significant, there were a number of factors which worked in our favour.
_ As part of previous work on the DataLex Project (Greenleaf et al, 1992), we had developed an automated approach to hypertext creation (particularly in relation to legislation) which we felt could be scaled up to the levels which would be necessary for the sort of system that we were proposing. Although the free text retrieval tools we were using at this time [12] , proved to be less scaleable, the experience that had been gained in creating these meant that we could quickly write new software which was up to the task.
_ The level of funding which we had available [13] , meant that the initial technical team was very small (Andrew Mowbray, Geoff King and Peter van Dijk). This gave us tremendous flexibility and allowed us to build something very rapidly.
_ We had very good support from one of the initial data providers. David Grainger, the manager of the Commonwealth Attorney-General?s system SCALE, provided us with a copy of the complete Commonwealth consolidated legislation and regulations and AGPS provided us with the necessary permissions to publish this data.
With a large degree of youthful enthusiasm and naivety, we bought the necessary hardware, employed the first AustLII employee (Geoff King) and created a prototype system. The initial offering contained Commonwealth legislation and regulations marked up in a fairly sophisticated hypertext form (which included many of the features which are present in the current system - hypertext references to Act names, section references, definitional terms and so on).
At this point, two very important things had been established: firstly that the DataLex hypertext markup technology was scaleable (at least to the extent that it could deal with the legislation of an entire jurisdiction); and secondly, that there was demand for the sort of Internet service that we were proposing. Within a matter of weeks, we were recording accesses from around 400 sites per day (with daily page accesses reaching about 10,000 hits).
For the first few weeks of operation, we used the Glimpse search engine. It quickly became apparent that this software could not deliver the sort of performance that we would require. Over a three week period a new free text retrieval engine (which came to be called SINO) was written. The main aims of this new piece of software are probably best summarised as Mowbray described them at the time (Mowbray, 1995):
The main things I have tried to achieve in building SINO are as follows: _ annoy Peter (and to a lesser, but still significant extent - Geoff). They still feel that I could be doing something more productive _ write something that anyone could use for free to air services like AustLII _ provide a much more respectable search language and interface than was available on any of the existing public domain products (particularly from an Australian lawyers' perspective) _ produce something that is fast (no real magic needed here, just a conventional inverted file approach with a few smarts borrowed from my old free text system -Airs) _ don't get too hung up about index sizes (the AustLII indexes are running at 30% of text size, which to my mind is more than acceptable) _ try to keep indexing times within sensible limits (AustLII's Sparc 20 is taking about an hour to index 60,000 files containing 250 M) _ keep it portable so that it will at least run under Windows and on the Mac as well as under UNIX _ try not to produce 1/4G spill files again!
Despite the light hearted approach of the time, SINO quickly (within a few days) became the AustLII search engine.
Over the rest of 1995, we received permissions to publish a lot more data [14] . For the most part, our technical efforts were directed at rationalising the hypertext markup approaches and the search engine to deal with the increasing number of databases. The emphasis remained upon achieving fast massively automated hypertext markup of the Commonwealth Attorney-General Department?s data. This data came as extracts from the main Commonwealth AG?s SCALE database. Our aim was to achieve totally automated data conversion (we had little choice given the volumes of the data and the size of the technical team which had by this stage been reduced to two - Geoff and Andrew).
At the end of 1995 and the beginning of 1996, AustLII started to receive data directly from courts and governments. Some of these early data providers included the NSW government (legislation), the Commonwealth Industrial Relations Court and the NSW Land and Environment Court. The provision of this sort of data posed new challenges. It involved us for the first time in document management and in additional data conversion issues. The approach was to convert this material into an intermediate format and then let the established hypertext markup tools take over. For the most part, we were quite surprised to see that our underlying markup technologies continued to work well.
Much of 1996, continued in a similar vein. We were faced with a growing number of different data formats and were being expected to perform automated editorial work to deal with data inconsistencies. This added another layer of complexity on what were doing, but through a process of "pre-processing" to intermediate form proved to be sustainable. In March 1996, we recruited the second AustLII employee (Philip Chung) to help deal with this. During 1996, the reliance on pre-processed data from Commonwealth Attorney-General?s continued to decrease. As demand increased (to its current levels of around 1.5M hits per month with accesses coming from over 4,000 sites per business day), the hardware was upgraded and a system of load sharing between a number of server machines was introduced.
2.2 Current System Dimensions and Configuration
The size of the AustLII collection has grown steadily since the system was established. The current dimensions of the collection as at the time of writing are as follows:
Number of searchable databases / collections: 50 databases
Number of searchable documents: 470,000 documents
Raw text database size [15] : 3,007,000,000 bytes
Number of automatically maintained hypertext links: 12,900,000 links
The current usage figures are:
Average number of pages accessed per business day: 65,000 pages per day
Average number of users/sites per business day: 4,200 users per day
Maximum number of concurrent users / sessions [16] : 200 concurrent users
The current hardware configuration which directly supports the live system [17] consists of three Sun Microsystems servers [18] . Two of these are linked directly via a 100Mbps fibre interface to the main 32G RAID disk array. The machines are linked via a 100Mbps switched ethernet network which is connected to the UTS network via 2 100Mps fibre connections. UTS is the hub of the university regional network and is directly connected to Telstra?s Internet point of presence in Padington via a 10Mbps pipe.
The organisation of the hardware is as set out in the following diagram:
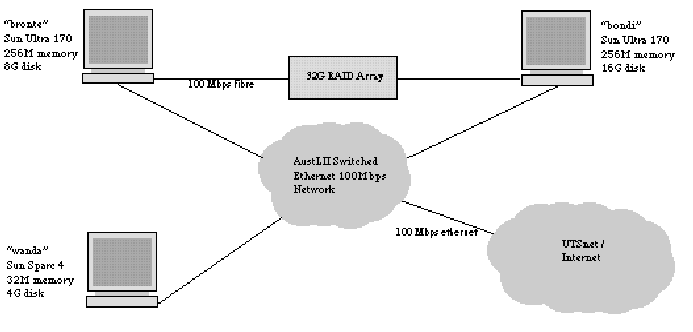 Figure One - AustLII Hardware / Network Setup
Figure One - AustLII Hardware / Network Setup
The hardware setup allows us considerable flexibility. At the moment all of the httpd services are run on the main machine "bronte" using the Apache web server software. SINO searches are shared between this machine as well as "bondi" and "wanda". As load levels increase, additional machines can be added to the live network.
Current plans include to increase the available RAID storage from 32G to 96G and to add a number of additional machines (or to upgrade the current ones) to help with load sharing.
2.3 The SINO Search Engine
The centre-piece of the current AustLII system software is the SINO search engine. SINO was written in May 1995 and has continued to slowly evolve since. The essence of SINO is simplicity and speed. The software is written in C and is very compact (at about 5,000 lines of code including concordance management programs). The central trade-off in SINO?s design is to sacrifice disk usage for speed of execution [19] . Having control of our search engine has been very important. It has meant that we have been able to modify it to meet changing needs and to tune it for increased system performance.
The concordance ratio (that is the size of the text indexed versus the size of the index files) is currently running at about 40%. Although the concordance size is large (1.2), given the amount of text which is being indexed (over 3G), this does not present serious difficulties. In execution, the SINO search interface uses very little memory. For Boolean searches, the amount of memory which is used per search is around 250K. For freeform ("conceptual") searches, this figure increases to about 400K. The size of the temporary files that it generates are fairly large (up to 200M for complex searches).
In order to maximise search times, concordances are stored in a very efficient format. Although concordance building on the current model is very memory intensive (using up to 64M of core memory), the build times are very fast. A typical build on one of the Sparc Ultras (in out of peak hours of usage) is taking around 6 hours to re-create a concordance for the whole of the AustLII database. In sustained terms, the SINO database creation utility (sinomake) is running at about 500M of text (or 90,000 documents) being processed per hour.
The AustLII SINO database is maintained using a single concordance. This means that users can conduct searches across all of the 50 AustLII "databases" without significant performance degradation. Improvements to the way that database "masking" is handled, however, has also meant that there are performance advantages where users restrict the database search scope.
From an interface perspective, the SINO interface presents an "interactive" model which is suitable for processing by custom written scripts. We currently use a set of perl programs for this purpose. A typical SINO session goes something like:
sino> set options ranked
sino> set mask au/cases/cth/high_ct
sino> set display file title rank
sino> search banana
sino: total-docs 7: message: 7 matching documents found
au/cases/cth/high_ct/173clr33.html
CALIN v. THE GREATER UNION ORGANISATION PTY. LIMITED (1991) 173 CLR 33
100
au/cases/cth/high_ct/124clr60.html
KILCOY SHIRE COUNCIL v. BRISBANE CITY COUNCIL (1971) 124 CLR 60
75
au/cases/cth/high_ct/115clr10.html
MEYER HEINE PTY. LTD. v. CHINA NAVIGATION CO. LTD. (1966) 115 CLR 10
66
...
sino>
Figure Two - Low level communication with SINO
This sort of approach is very flexible and means that SINO searches can be easily shared across a number of machines using a standard UNIX sockets approach.
The SINO user search parser is very forgiving. It will accept searches in a number of standard search languages which legal researchers might be familiar with. The current search syntaxes which are recognised include Lexis, Status, Info-One (now Butterworths On-line), DiskROM, C and agrep. The desire to handle all of these command languages mean that there have been a number of tradeoffs (eg the use of characters such as minus for a Boolean not in Status). Nevertheless, the compromise is designed to work in the majority of cases and seems generally to work well.
2.3.1 Relevance ranking and ?freeform? searches
As well as conventional Boolean searches, SINO also supports "freeform" (that is, "conceptual") searches. Both now display results using relevance ranking (see the Introduction). ?Freeform? searches do not involve the need for operators or other formal syntax and are designed for users who do not have experience with Boolean systems or who wish to be lazy.
Freeform searches are processed as follows (similar elements except the first are also used in our Boolean retrieval with relevance ranking):
_ All non-alphabetic characters are stripped and common (non-indexed) or non-occurring words are removed.
_ Based on the relative infrequency of the remaining search terms, SINO builds the biggest list of matching documents (that is, any document which contains at least one search term) that it can within set memory constraints.
_ The system then ranks these on the basis of (a) how many search terms appear; then (b) how many "weighted" hits appear. The "weighted hits" are calculated according to a formula which gives preference based on how early word "hits" appear in a document, how commonly the word occurs and (inversely) on the document size.
This is the current formula which is used - we stress that there is no magic in this, but it does yield a sensible result:
(a * b S (c * (d/((e 1) 1))) * 100 / ((a 1) * b);
where:
a = the total number of search terms
b = the largest number of occurrences for any of these search terms
c = the number of occurrences for this word
d = a constant to reflect how early a word must occur to deserve special weighting (currently 300)
e = the document offset for this word in the current document
Figure Three - the Current SINO Freeform Ranking Algorithm
The effect of this ranking algorithm is to yield a percentage. A document receives 100% where it contains all of the search terms and the greatest number of ranked hits. The relative "importance" of other documents is proportional to this figure.
As is the case with most conceptual ranking systems of this type, the "correctness" of the search results is best judged from a study of their usefulness from a user perspective. Whilst it is a bit difficult to gauge this with total accuracy, it appears from user feedback and on the basis of our own experience that the approach seems to work well. The ranking mechanism for Boolean search results works on a similar basis.
In summary, we maintain that SINO is the fastest, most flexible, and (most importantly to its author at least), the most elegant search engine that is available for use on legal web sites.
2.4 Document Management
From the outset, it was clear that we had to adopt a sustainable document management regime. The solution which we adopted was to maximise the use of the UNIX file system on the computers that we were using.
The raw UNIX file organisation provided us with a mechanism to achieve most of our objectives. It provides an elegant mechanism for organising documents (including such matters as added dates, updated dates, and database/directory organisation) without the requirement of more complex custom written software. It was also a very efficient way of handling things (without need to resort to separate document management databases). Despite the limitations, this fairly simplistic approach has proved to work.
In order to encourage other web sites to link directly to our pages, we have had to maintain a static set of file hierarchies and file names. The file naming hierarchy which we have adopted is as follows:
/country (/au)
/legis (legislation)
/jurisdiction (act, cth, nsw, nt, sa, tas or vic)
/consol_act (consolidated acts)
/consol_reg (consolidated regulations)
/num_act (numbered acts)
/num_reg (numbered regulations)
/cases (judgments)
/jurisdiction (act, cth, nsw, nt, sa, tas or vic)
/court (a court designator [20] )
/other (secondary materials)
Figure Four - The AustLII Directory Hierarchy
Although the case file and directory names continue to be something of a problem (there being no existing way of actually referring to a judgment! (Greenleaf et al, 1996), we have adopted a standard way of referring to legislation. Individual sections always take the form "s123.html" and schedules are stored as "sch123.html".
The act or regulation entries are stored under short form directory entries which include the first letter of each word of the act or regulation followed by the year and then a checksum which is based on the remaining letters in the act/regulation name. The reasons why we have adopted such a seemingly complex approach are set out in the following section (along with a copy of the algorithm which we use for determining this).
2.5 Hypertext markup
Hypertext markup on AustLII (nearly 13 million links) is done on a massively automated basis. There is no manual editing of hypertext links. The main reason for this is one of resources. The data is constantly changing (particularly in the case of legislation) and new data is constantly being added to the system. We do not have the very large team of editors necessary to maintain the links on a manual basis.
The main aim of the hypertext markup approach is to achieve the richest possible set of hypertext cross references possible on a completely automated basis. Prior to the start of the AustLII project, we had already gathered a number of years experience in automated markup.The markup attempts to achieve three basic things :
_ it should be as rich is as possible
_ it should minimise the number of erroneous links
_ it should be as simple as possible (both for speed and maintainability)
Unfortunately, of course, these factors tend to contradict each other. There is always a temptation to modify the scripts to take care of very isolated examples. As changes are made, however, there are often side effects which can stop other parts of the markup working properly or which tend to introduce an unacceptable number of errors and slow down the overall markup times. The current markup essentially represents a design compromise which seeks a balance between the constraints.
The mechanics of marking up raw materials are implemented as a number of 'markup scripts'. These are written in a combination of C and perl. The most important of these scripts are independent of the source data formats. Currently we receive our data in a number of forms, including: word processing files (Microsoft Word, Word Perfect and RTF), database dumps (BRS, Status and HTML) and as plain text. A system of pre-processing is used to convert these to the various intermediate formats which are used by the main markup processes.
The total size of the code which is involved in the markup scripts is quite small (less than 10,000 lines of source). There are currently about 60 individual modules (a lot of which are very small and are used for pre-processing).
As was discussed in the previous section, we rely heavily on the use of file organisation for document management. Currently, there are no separate document control databases. Partly because of this and partly for reasons of markup efficiency, all hypertext links on the system can be mapped on a 'one way' basis. The central idea is that whenever a potential link is found, it is possible to determine an appropriate destination without any database lookups (other than perhaps a check to make sure that the target HTML file actually exists).
This problem is dealt with in the main by the persistent naming conventions discussed above. Acts and regulations are something of a special problem. By and large, all references to Acts and Regulations tend to involve a complete recital of the short name of the instrument. The approach which we have adopted is to convert these references to a quasi-unique file name abbreviation which is determined by the following algorithm:
| char * uniq_pref(s) char * s; { |
|||||||
| static char char |
buf[MAXLINE]; * s1, |
||||||
| * s2 = buf; | |||||||
| long | count = 0; | ||||||
| for (s1 = s; *s1; s1 ) { | |||||||
| if (isdigit(*s1)) | |||||||
| *(s2 ) = *s1; | |||||||
| else if (isalpha(*s1) && (s1 == s || isspace(*(s1-1)))) { | |||||||
| if (isupper(*s1)) | |||||||
| *(s2++) = tolower(*s1); | |||||||
| else | |||||||
| *(s2++) = *s1; | |||||||
| } | |||||||
| if (islower(*s1)) | |||||||
| count += (*s1 - 'a'); | |||||||
| else if (isupper(*s1)) | |||||||
| count += (*s1 - 'A'); | |||||||
| } | |||||||
| sprintf(s2, "%ld", count); | |||||||
| return buf; | |||||||
| } | |||||||
The effect of this algorithm, is to create a short relatively unique file / directory name for an act or regulation. It consists of the first letter from each word in the act title, followed by the year and then a checksum which is based upon all of the other letters which go to make up the name. An Act name such as the Trade Practices Act 1974 becomes tpa1974149 and the Historic Shipwrecks Act 1976 becomes hsa1976235.
Although this approach is not at all perfect, an analysis of all of the legislative databases on AustLII shows that it is functional without any intra-jurisdictional duplication. As between jurisdictions, of course, it is sometimes the case that different states will enact legislation with identical names and years. This issue is dealt with by "seeding" the markup scripts with some idea of a "default jurisdiction" (ie if the markup process is dealing with the NSW Supreme Court, it gives priority to NSW legislation).
The markup scripts are highly heuristic and designed to pick up a number of salient text features. Some of the things which we currently aim to identify and add hypertext links for are:
_ references to Act names
_ references to sections of Acts (both internally and externally)
_ references to other structural legislation elements (parts, schedules etc.)
_ references to legislatively defined terms
_ references to case citations
Although some of these can be dealt with without reference to any contextual matters, a lot of these items are highly context sensitive. This is particularly the case in relation to legislation markup. The current legislative markup scheme depends upon a number of sequential passes through the raw text. The approach is summarised as follows:
 Figure Six - Legislative Hypertext Markup
Figure Six - Legislative Hypertext Markup
For the most part, all markup is done ahead of time. Dynamic markup is kept to an absolute minimum in order to maximise system performance. The major exception to this is in relation to the noteup functions which are included for all legislative documents and some cases. The noteup function allows users to conduct canned SINO searches which are based upon stored URL addresses. The effect of noteups is to perform a "reverse hypertext lookup" thereby returning related documents which refer to the current document.
2.6 Future plans
Now that the database is relatively stable, we are taking the opportunity to redesign several system elements. The nature of the markup work is changing from a model which is based on large scale conversion of pre-prepared collections to one where further editorial control is required.
Some of the things that we are doing to address this include a proposed new directory / file organisation for case law and the adoption of a more flexible intermediate file format. The cases law reorganisation is already partially implemented for some databases. The idea is to move to a system of years and judgment numbers. This poses several challenges for older materials where it will probably be necessary to impose a degree of arbitrary organisation. The file format issue is a much larger problem. At the moment, files are stored and dealt with in their original source form. Over the remainder of the year, we propose to convert all of the data into a simplified SGML format on a largely automated basis.
