JILT 2000 (3) - Curran & Higgins
A Legal Retrieval Information SystemKevin Curranand Lee Higgins As the demand for legal services increases and the Internet threatens to dominate as a general research and business tool, two related challenges are presented to the Information Technology and Legal Communities: 1. The provision of easy to use services/applications which are cost-effective to develop and which improve the efficiency of the lawyer's research task; 2. Finding effective means of making such services widely and publicly available across the Internet We demonstrate how such services might be created by building on lessons learnt from an investigation into current legal applications and we also examine those technologies that offer an appealing means of realising the second goal above, with the eventual goal of describing the framework of an application which provides the basis for meeting both challenges. Keywords: Legal Information Retrieval Systems, Legal Databases, CBR, Pattern Matching, Web Based Legal Applications This is a Refereed article published on 31 October 2000. Citation: Curran K and Higgins L, 'A Legal Retrieval Information System', 2000 (3) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/00-3/curran.html>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/2000_3/curran/> Since the early 1990s there has been a marked increase in demand for legal services, especially within specialised areas of the law such as commercial law[R1]. At the same time empirical studies have clearly revealed that more and more cases are being decided in negotiations rather than by decree[R2]. The upshot of this combined with a dramatic decrease in the availability of legal aid, the growth in popularity of contingency fees and a sharp increase in the cost of specialised legal services is that clients rights in these specialised areas are more frequently being represented by lawyers not specialised in particular fields. For such professionals to service their clients effectively they need wide access to up-to-date legal materials[1] in order to complete their legal research tasks. However at the same time the large and continuous increase in the volume of such legal materials means that the problem for non-specialist lawyers is not just one of information availability but also one of efficient information retrieval. The highest legal authorities in the land have recognised that Information Technology (IT) can and should play a role in this area.[R3] The Internet has for some time been used by a wide class of lawyers as both a general business tool and more specifically as a research tool. Indications are that this trend is set to increase and infect all areas of legal practice. It should therefore be cultivated and exploited[R4]. Nevertheless, while the Internet remains a powerful and efficient means of exchanging and communicating information, the standard web-site approach of fetching documents through predetermined hyperlinks or via keyword search through search engines, is not likely to prove overly helpful in satisfying the sophisticated information needs of lawyers. However, technologies such as Java promises to transform the Web into a truly interactive information forum and also provide simple yet powerful means of making services not particularly designed for the web available across the Internet. It could thus help to better meet the aforementioned information needs. At the same time it is crucial (and a central argument in this work) that we recognise that most modern legal information retrieval applications (whether web-based or not) are, for some basic reasons failing to service the requirements of non-specialist lawyers. In light of the above the current situation poses 2 distinct but related challenges for IT. Providing easy to use services which improve the efficiency of the lawyers research tasks and thus effectively meeting the information needs of non-specialist lawyers Making these services widely and publicly available across the Internet The goal of this paper is to investigate and demonstrate how simple but powerful web-based technologies, provided through Java, might be used to meet the challenges outlined above. 2. S.459 Ca 1985 and the Lawyer's Research Task S.459 (State and Local Investment Opportunities Act of 1985) of the Companies Act 1985 aims at offering minority shareholders in companies a judicial remedy whenever they wish to complain of the behaviour of (usually) the majority/controlling shareholders in a company. The provision states that a member of a company may petition the court for relief on the grounds that: 'the company's affairs are or have been conducted in a manner which is unfairly prejudicial to the interests of its members......or that any proposed act or omission of the company......is or would be so prejudicial' Empirical studies[R5] have clearly demonstrated that most cases dealt with under this area concern 'quasi-partnerships' which may be defined as limited liability companies which have evolved from close partnership-like agreements[R6]. We shall create our prototype application to target this particular class of cases. The key concept here is that of unfair prejudice and the lawyers task basically consists of demonstrating to the court (or convincing his opponent) that the conduct their client complains of can constitute unfair prejudice for the purposes of the section.[R7] However no clear statutory definition exists to guide the lawyer. No clear rules exist to dictate what might make for a successful petition. What do exist are general guidelines for guiding the court as to what types of conduct might be tolerated in a particular situation[R8]. As such, a lawyer searching for solutions must dig through a wealth of case law and doctrinal writings to find relevant guidance on the problem case at hand. Searching through this document corpus (either in digital format in electronic databases or manually in a law library) can be a very time-consuming process. It is not only the fact that S.459, given its nature is a notoriously difficult area to research that makes it meritorious of consideration in this project. S.459 is also stereotypical of the problems outlined in our introduction. Most cases are decided in negotiations, which can require costly expert advice due to the specialised nature of negotiations. In addition to this we might note that while new cases are added to the overall case body on a regular basis, it is still possible to identify with confidence a finite number of legal issues that might be involved[R9]. Our proposed system aims at supporting the lawyer in his research tasks for a problem situation. Therefore some understanding of the how this task is generally carried out and how we might improve efficiency here is called for. The overriding goal for the lawyer in this context is to get to potentially relevant legal resources (here decided cases and doctrinal writings) that can help him better understand the legal issues he is dealing with and how he might go about tackling the legal problems at hand. Once the lawyer has completed the laborious background research work, he will use his results to begin the legal reasoning process i.e. that of forming an argument for his client and in doing so will inevitably need to revisit these research tasks. Overall this approach can be exceedingly time-consuming and wasteful, whether carried out manually in a law library or through the use of electronic databases. 2.2 Improving the Efficiency of the Research Task Making information publicly available i.e. via the Internet, obviously overcomes the some of the problems of obtaining sources which are identified as relevant. However our problem is also one of efficiently identifying which materials could be relevant as the sheer volume of potentially relevant information on the Internet makes it an inefficient source. It is argued that the efficiency of the lawyer in this context could be greatly improved if an information retrieval system could boast, at the very least, the following functionality. An interface designed with the guidance of a legal expert, which 'walks' the lawyer through the various possible issues in the case - this interface (through a series of yes/no questions) could help the lawyer build up a profile of his case at hand. Once a basic profile is built up the system should indicate (through a process of basic pattern matching) those important cases in the field which best match the profile of the current problem case. We do not aim here at reasoning through stare decisis. Instead the goal is not to retrieve cases, which shall be used in an actual court hearing etc, but cases, which are most likely to discuss the kind of issues the lawyers problem case involves. This functionality would therefore serve as a springboard into more intensive and informed research. If the system does indicate which cases best 'match' the input case, it should explain how this match occurs and also indicate how the retrieved cases are distinguishable from the current case. Lawyers search by concept (i.e. legal issues) not (potentially) random keywords. Any index of our document repository should allow the lawyer to find, inter alia, the leading case on a given issue, the latest case on a given issue, important cases where a given issue is discussed and also doctrinal articles where a given issue is discussed. When looking at a given case the lawyer should be able quickly to identify other cases where this case was distinguished or cases similar to the case or doctrinal writings where the actual case is discussed. 3. Legal Information Retrieval Systems The most widely used research tool is the electronic database. Most legal databases exist in CD-ROM format (e.g. CELEX[R10]) usually purchased through a one-off subscription payment. However given the growth in importance of networked computing and more specifically the Internet an increasing number are available 'on-line' so capable of immediate updates and paid for on an 'as-you-use' basis. Examples of this latter category include LEXIS[R11] and Smith Bernal's on-line casebases[R12]. Usually the full text of documents is stored or an abstract of the full document and the index to the database built on this. While a variety of indexing possibilities exist (such as vector space or probabilistic[R13]), search (effected over this text or an index referencing this text) is most commonly carried out using keywords and Boolean processing. This functionality may be extended through the use of truncation or thesauri services (as is the case with the KLUWER database[R14]). Users may also have the option of searching on specific fields such as date or jurisdiction or even presiding judge(s)[R15]. A growing number of tools now offer the ability to limit your search space by legal topic and a common trend nowadays is to include hypertext links within retrieved documents so that users can easily access other materials referenced in the retrieved text[R16]. 3.1 Problems with Legal Databases It goes without saying that such technologies have greatly improved the efficiency of the lawyers research task, at least in as far as they make materials more freely available. However some basic problems with such tools still exist which reduce their usefulness to our target set of users. The fundamental problem derives from the combination of free-text and Boolean processing as a means of retrieval[R17]. Usually all the words in the full-text (or abstract) are indexed. Given the open-text nature of law, this means that while relevant documents may be returned on a keyword search they shall be subsumed in a wealth of irrelevant material too (i.e. levels of recall and more importantly relevance are deceptively low) and the user must sift through these to reach useful materials. Given that the volume of legal materials is rapidly increasing the number of random and meaningless associations made on a keyword search is likely to increase (despite moves towards allowing users to limit their search to a particular legal area), thus exacerbating this 'false-drop' problem. Furthermore, Matthijssen[R18] has noted that for the optimal use of text retrieval systems users must:
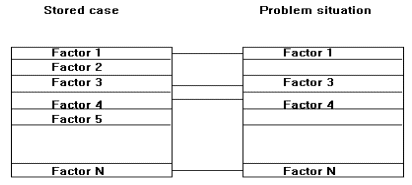
However expressing an information need satisfactorily in Boolean terms has proved difficult for lawyers, meaning that assembling and applying effective search requests remains a specialist job[R19]. We might also note at this point that our target set of users (non-specialists in an area of law) are unlikely to know what 'keywords' will be of use. It is important also to note that lawyers do not formulate their information needs in terms of 'keywords' but shall instead use abstract concepts such as legal issues involved in a case. Furthermore lawyers being lawyers and not computer scientists are not likely to understand (or desire to understand) the complexities of content and storage. The upshot is that lawyers wishing to make effective use of the database must overcome a 'conceptual gap' - translating the information need they have in their head in legal terms into a query which should be put in technical database terms thus distorting the semantics of their request[R20]. 3.2 Improving the Efficiency of Legal Databases The basic problem therefore is that such databases lack structure (most of the text is indexed) and fail to effectively provide for the likely information needs of lawyers. Formulating effective Boolean queries is difficult and usually results in the return of much irrelevant materials or references. These problems, it is suggested might be rectified by the following simple means. Firstly, free-text should not be used as the basis for an index. Instead an index should be created which sits on top of the text and acts as a sort of document management system providing intelligent guidance to the relevant texts. To minimize the likelihood of the 'false-drop' problem, the initial effort in compiling a human-created index should be made. To make this index more efficient, we have based it on the users task-domain and structured it so that it can be easily queried to meet the most likely information needs. In addition the interface to this database should hide the complexities of the index and allow the user to make queries using his 'own language', hence avoiding the 'conceptual gap' described above. A goal far more ambitious than speeding up the lawyers research process has been the use of Artificial Intelligence techniques to emulate the substantive legal jobs performed by the legal expert. If this goal could be achieved then not only would other relevant documents be indicated but guidance on how to actually use them would also be supplied. Initially this class of machines were developed with a view to providing solutions to a legal problem as would a real-life expert (legal expert systems - legal E.S). However such systems have moved from this expert solution goal and now instead purport only to incorporate legal knowledge with a view to proving guidance or 'decision support' to lawyers (such systems are referred to as legal knowledge-based systems - Legal Knowledge Based System or Legal Decision Support Systems[R21]). Most systems in this field have adopted techniques based on one of two dominant legal theoretical paradigms. Rule-based systems basically involve adopting a positivistic view of the law as a determined set of rules. In such systems the law is symbolically encoded as a set of production (if/then) rules which are manipulated through a process of forward (or less commonly) backward chaining with rules being fired depending on the input facts of the current problem case. Given the flexible nature of S.459 this approach is hardly suitable. Of more interest here therefore are those systems which adopt a more realist view of the law and place emphasis on recognizing that an important component of legal reasoning is identifying from decided case-law precedents for decisions in a particular case. Case-based reasoning (CBR) as it is known basically involves reasoning from collected examples of previous problem solving experiences[R22]. These experiences in this field being actual or hypothetical legal decisions. Typically cases are represented as frames, with slots representing factors or legal issues. Cases may then be compared and analogies created and manipulated on the basis of the presence or absence of factors. (See Figure 1) Complex weighting algorithms may be incorporated into the process to help determine the thorny issue of similarity.
Figure 1: Basic CBR factor matching[R23] This CBR approach may be employed at several levels. Retrieved cases can be used to form the basis of an argument to a solution, or used as the input into algorithms for constructing legal arguments using cases. Increasingly the CBR approach is being used to seed information retrieval over a large corpus of materials (usually existing free-text case repositories). At the simplest level, such techniques are used for basic information retrieval using factors and a matching process to select materials likely to be relevant to the user. Increasingly, both techniques (production rules and CBR) are employed in hybrid systems. For example Popple's SHYSTER system[R24] uses rules until some conflict arises and the uses CBR to attempt to resolve this conflict. 3.3.1 Problems with Ai-Legal Applications Despite the intensive and laborious research conducted into such machines they have largely failed to attain their goals and very few have made the transition from research ventures to applied systems. This failure, it is submitted is due to fundamental problems both at the philosophical/theoretical level and the practical level. Firstly all such systems involve the creation of a model of the legal domain - referred to as an 'ontology'. The overriding goal here is one of representing the knowledge in a manner that is at once computer encodeable, and at the same time remains true to the meaning of the original source material. Making this knowledge computer encodeable almost always involves viewing the law as a (fixed) set of rules. It is almost universally accepted that the law is slightly more complex than this. The law is not self-contained and autonomous; instead it's meaning must be interpreted in the light of many implicit and ever-changing assumptions in the political and social context. It is seriously doubted whether current technologies can handle such a complex model. It thus follows that this process of isomorphism has yet to be achieved and representing legal reasoning in a computer encodeable form involves a certain distortion of the subject material. Given the work involved in building a satisfactory model, it comes as no surprise that such machines are notoriously costly to develop, and given the underlying complexity they are extremely difficult to maintain (ease of maintenance being one of the cornerstones of any applied system) and update[R25]. Developing intelligent systems that can easily handle change is no trivial matter and this problem is all the worse if we accept that the law is a notably fickle and changeable creature[R26]. Furthermore unlike other areas of AI the complexity involved in automating or providing support for legal reasoning means that no generic commercial shells are available and most systems (capable of covering only one or two legal problem areas) must be built from scratch[R27]. In addition such applications whether Knowledge Based Systems (KBS) or Decision Support Systems (DSS), fail to recognize the realities of legal practice in the sense that they tend to place too much emphasis on the law as an entity embodied in written texts rather then the product of an oral tradition. Computer technologies should therefore assist with mechanical research/retrieval tasks and not delve into more creative (and inherently uncertain) task of legal reasoning. We might also ask ourselves whether such machines have a large enough target audience to justify the massive effort required in building them. To make sense of the complicated output they produce the user must have already a considerable knowledge of the target area of the law and sophisticated IT skills - qualities missing in our target (and most) users. In addition we might note that the complex reasoning strategies and output they produce are likely only to be of use in cases decided in the highest courts in the land (about 1%)[R28]. Most lawyers especially in the lower courts and in negotiation cases only consult case materials to get a grasp of the basics of the law and to find illustrations of situations which might justify the clients pleas. Since most cases within S.459 are decided in negotiations an application that produces complex legal argument strategies is likely to be of little practical use. Attempts to automate legal reasoning have as yet, it is argued not proved very successful. However this is not to say that this goal is impossible nor that work conducted in this area has been in vain. Nevertheless we must accept that the law is too changeable, legal reasoning too difficult to model accurately and the number of potential target users too small to make such machines cost-effective. This said, if we keep in mind the limitations of these systems (i.e. they are, after all only sophisticated pattern matchers[R29 ] and our development efforts should reflect this) then we can derive some use from this particular field of research. These limitations should also be clearly communicated to our users[R30]. The CBR process of comparing cases based on the notion of factors is, it is argued, relatively easy to replicate. It is also quite useful to (and a common strategy adopted by) lawyers who use it not for any substantive purpose of legal reasoning but to identify cases that could help them better understand the issues involved in their case. Bearing this limited goal in mind our system shall attempt to implement some form of basic pattern-matching mechanism. In order to make legal resources (here legal cases and doctrinal writings) susceptible to treatment by an information retrieval application we need to represent our target area of the law in some computer searchable fashion. In the most basic terms this involves creating a 'model' of the legal area. This is crucial in understanding how our proposed application works and shall be referred to in our implementation chapter. Remaining true to our findings earlier, our representation should remain simple (thus easy to update or alter), efficient, easy to understand and intuitive to lawyers. One common approach used by lawyers in performing research on an area of the law is to describe the area of the law in terms of factors or legal issues which arise in the area and then analyse a problem situation (and express their information needs) in terms of the legal issues involved. This simple strategy also forms the fundamental building blocks of the most praised legal CBR systems- HYPO[R31] and CATO[R32]. Basically a legal case can be described in terms of the factors it exhibits. Each factor can either:
At the most simple level factors can be binary i.e. yes or no. At a more sophisticated level, factors can be quantifiable having a strength and direction (we call this category of factors 'dimensions'). This is a simple prototype application so we shall stick to simple binary factors, i.e. factors which are either present or not in a case This is not a legal dissertation therefore the 'legal knowledge elicitation' performed here, i.e. the process of determining the factors which arise in S.459, is purely rudimentary and is based on the classification found in the most popular textbooks [R33][R34 ][R35]. It does not purport to be a true representation of the law merely a crude approximation used for demonstration purposes. In any polished system this task should be an intensive one carried out by a lawyer experienced in the field since the quality of our model will condition greatly the quality of our end product. This said concerning S.459 and quasi-partnerships we can identify the following factors/legal issues:
Thus cases can be described in terms of the presence or absence of these factors or alternatively in terms of the factors/legal issues it discusses. We want to keep our representation simple in this prototype application therefore we stick to binary factors. So if a factor is present in a case we call it a p-factor otherwise we term it a d-factor. For example if we had a case where the facts were such that the plaintiff had lost his livelihood (Factor 2), then we would state that factor 2 was a p-factor in relation to this case 4.1 Using our Basic Representation We will use a classification based upon an approach adopted by Bench-Capon [R36] in our application by Performing information retrieval on an index (stored in a database) that describes and references information held in a legal case and doctrinal writing repository. Using the above model we can describe/identify a case by the factors it exhibits. For example we could describe a certain case as being the leading case on Factor 6, or indicate in our index that the main factors dealt with in the case are Factors 3,4 and 6 etc. Doing so will thus allow a lawyer to retrieve cases on the basis of legal concepts i.e. legal issues. Likewise a doctrinal writing could be defined in terms of the legal issues it discusses. 4.2 Pattern Matching to Retrieve Similar Cases As noted earlier, this is a very common strategy employed by lawyers not only for the purpose of analogical reasoning but also to help find/retrieve factual examples, found in cases, which could help explain their current problem situation. Here we use simple pattern matching for this latter purpose. Pattern matching in the most basic terms involves comparing cases on the basis of the presence or absence of factors. Each case is defined in terms of p-factors or d-factors. Thus, if we compare 2 cases (on the basis of P-factors & D-factors they exhibit in relation to each other):
The set of factors exhibited when comparing cases is classified into 4 groups: i P-factors common to the 2-cases. ii Factors that make C1 stronger for the plaintiff than C2 (p-factors in C1 but not in C2 /d-factors in C2 but not in C1). iii Factors which make C2 stronger for plaintiff than C1 (p-factors in C2 but not in C1/d-factors in C1 but not in C2). iv D-factors common to both cases. Using this classification we can create a profile of our problem case and then match it against a set of stored cases, which are defined in terms of the factors they exhibit, thus allowing us to find the closest matching cases. Using the above 4-group classification we can also describe usefully how this match occurs (by for example pinpointing where similarities lie) and helpfully explain where distinguishing points between compared cases lie. 5. Legal-Aid Database Implementation Most modern web applications (or indeed any category of application) to be truly interactive, informative and useful require access to structured data, which is not embedded in the application. Such data is most usually (and usefully) contained in databases. Database management system (DBMS) products, consist of a series of programmes which together offer highly effective means of managing the data. Through the use of powerful data definition languages and data manipulation languages (DDL, DML) such as SQL, these products offer an excellent basis for populating, querying and otherwise communicating with databases. The system/application proposed here basically aims at improving the lawyer's research task by providing web-based access to a legal document repository, which resides on the server. The database index sits on top of the documents and provides structured details of the documents and pointers. The representation of the documents referenced (legal cases and doctrinal writings) aims at providing efficiently for information needs. We represent the documents in the database in accordance with our target area of the law being broken down into a series of 'factors' symbolising legal issues. These issues/factors (we identified 8 for demonstration purposes) may or may not be present in our case or doctrinal writing. Here these 8 factors are denoted I1-I8. Thus a document can be described in terms of the issues it deals with. Importantly a document can also be described in terms of other cases. The database contains tables made up of rows (and columns), which correspond to our legal documents. Each document is represented as a tuple, having a unique identifier (Cnum/Anum) with the other attributes being used to describe various facets of the document referenced (See Figure 2 and Figure 3). The attribute values are used for query and retrieval purposes.
Figure 2: The legal case table The column headers include (for cases), the unique identifier, name, law reports citation, date of judgement, the full address of the document on the server and the verdict of the case (either pro-plaintiff, or pro-defendant). These fields are pretty self-explanatory. However certain other fields will represent the opinion of some expert in the legal area:
Please note that instead of using multi-valued attributes here we use continuous strings. Thus, for example, case C1 above is the leading case on Issue 1, the main issues discussed in the case are issues 2, 3 & 6, it hasn't been distinguished in any case but is similar to case C3.
Figure 3: The doctrinal writings (Article) table The 'Article' table is structured along the same lines as the 'Case' table, also having similarly column headers for name, author etc. The 'Issue' field informs us as to what legal issues are dealt with in the doctrinal writing. If any cases are discussed this is stated in the 'Case' field. For example article A1 above deals with issues 4 and 7 and discusses case C1. Overall this structure allows us to move away from the 'false drop' inducing keyword search. The number of possible queries on the database is potentially massive. For this prototype application we have created only a select number of queries that correspond to the most likely information needs. The types of query we specifically cater for here include:
Furthermore we could add, quite easily several other fields to enable queries of the sort:
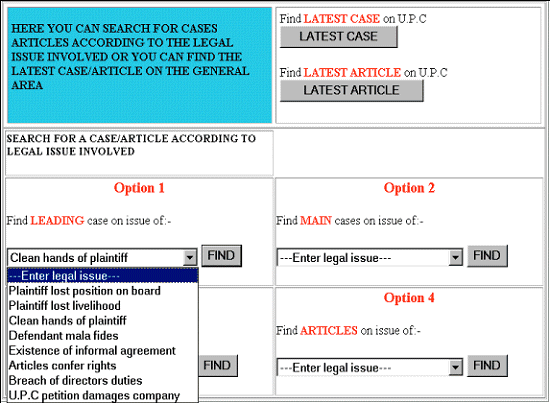
The point advanced here is that the simple representation above can permit powerful and varied queries on our materials and that our database is easily extendable to cater for additional user needs. The interface (see Figure 4) is presented in the lawyers own terms i.e. the user is invited to find leading cases, main cases etc. according to a certain legal issue, or the user can request cases which are distinguished from the current case he is reading. This enables the lawyer to more easily make specific and meaningful queries. The lawyer basically selects a legal issue within the appropriate form and submits by clicking 'Find'. The 'Find Latest Case/article' forms at the top of the page do not allow the user to specify input parameters - instead here we use 'hidden' fields. This is discussed below.
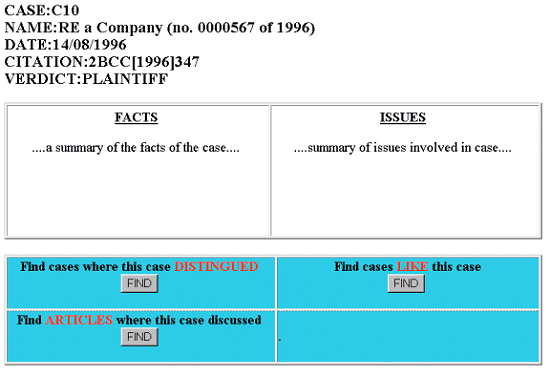
Figure 4: Legal Aid Web Page When reading a legal case or article the user may also access the database (See Figure 5). In this instance however the user does not specify any input data and the data sent is decided according to the actual page we are on (i.e. the value attached to the name is the case identifier). By clicking the form buttons the user submits a query to the Servlet.
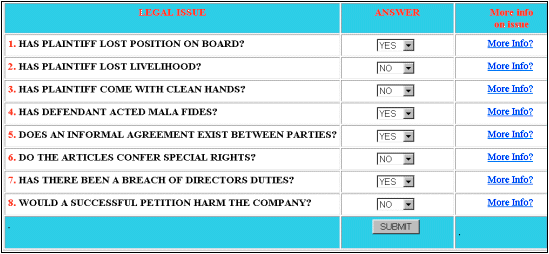
Figure 5: Legal Case Page A successful request returns a HTML table to the user which contains details of and a link to, documents satisfying the request. The user can then follow the link to obtain more details on the document. Here we describe how we might use a strategy based on that in the previous to perform a case-match function. To recap, the main goal of this component of the proposed application is not to produce highly complex and detailed reasoning strategies which devices such as HYPO and CATO generate but instead to provide the lawyer with a useful guide as to what important cases could prove useful in their reasoning task. As such a very simple pattern-matching algorithm/method, based on the model presented in Chapter 4 is employed. This basically operates on the simple premise that those cases which bear the most positives similarities (i.e. PPS factors or OCS factors as described in Chapter 4) to the lawyer's current problem case are most likely to be of use in building an argument which supports the lawyers case[2]. The corollary here is that those cases with more negative factors (i.e. TCS and PDS factors) will generally not be so beneficial. The value the lawyer would take from such an application would reside in the output of a core set of cases[3] that could help form the basis of the legal reasoning process. Unlike the AI-legal applications as described in Chapter 3 no attempt is made to simulate or usurp the reasoning task of the lawyer, instead an effort is made to speed up the initial input (the legal research), which forms the basis of this task. Importantly the core cases returned to the user would be described in terms of comparison to the current problem scenario (i.e. in terms of PPS etc. so that the user could easily determine how the retrieved case might be used in their favour or to their detriment[4]). The case-match Servlet operates with a web browser which the user uses to create a profile of their problem case by answering a set of yes/no questions. (See Figure 6 below)
Figure 6: The case-match interface The more info column allows the user to access materials that help him to better answer this question. This leads to a series of HTML documents which help clarify what constitutes a Yes or No with regards to each question (as this can be a grey area at times). Data is submitted in the same way as with the previous Servlet. The parameters input by the user are then compared against the pre-defined database data. Comparison would be based on the PPS/OCS/TCS/PDS approach described in Section 4.2. At the same time, a counter is set up to help determine the best matching cases. The count of each pre-defined case is represented as a cell in an array. What forms a good match (and scores highest) is based on the simple approach described above. For example PPS could score 2pts, OCS 1pt, TCS 0pt and PDS -1pt. Once all comparisons have been run, we search for and identify the highest (possibly 3) scoring cases.[5] Once the best matching cases are found a second round of comparisons is run (between the best matching cases and the user-defined case). The goal here is to classify each retrieved case in terms of PPS/OCS/TCS/PDS factors. We then use the output from this to generate 'HTML-on-the-fly', and send a response back to the user which describes the 'best' matching cases in terms of PPS etc and also attributes such as name, citation, verdict and location. A Vector space model is where documents are represented as vectors of the descriptors that are employed for retrieving information[R37, R38]. A vector consists of so many qualities as the different words available in the body of text. Every attribute can be weighted concerning its importance. In the simplest case, the attribute will receive a value of 1 if the descriptor occurs and a value of 0 if it doesn't. Vector Space Models may not be commercially successful as yet, however they remain an important tool for research[R39]. Web Search Engines provide a similar service howbeit much broader in scope. Search Engines employ in addition to Boolean search in particular the statistical means of the term frequency and of the inverse document frequency for ranking of documents. Terms in specific document parts like title, beginning of the document as well as the META tag receive higher weights during indexation. Retrieval quality is modest and requires better techniques of the automatic and semi-automatic document description[R40]. XML provides a greater possibility if the research results of document structuring could be reused. Recall and precision will be greatly improved[R41]. There is commercial Legal Expert System Software available at present which provides legal professionals with the ability to draft complex legal documents. This software works on rule based principles, which guide the lawyer through a question-and-answer session until the document is complete. These software programs typically support each question with expert legal and strategic analysis, practice tips and model language. Some companies offering these solutions include Expert Legal Systems Limited, Legal Software Solutions and Lawgic. Lawgic publishes intelligent applications for legal professionals by applying a comprehensive knowledge of complex subject areas to the details of a particular case. Each Lawgic title combines an intelligent question-and-answer process; on-point legal research, analysis, and practice tips from leading authorities; interactive, case-specific checklists of issues; document drafting with dynamically sculpted model language; updates to reflect changing law and practice. Current legal applications largely fail to efficiently service the information needs of lawyers. Most legal databases it has been submitted, lack valuable structure that can help lawyers quickly get to some information that may be of use in their research tasks. The can also suffer from lack of volume with regards to relevant cases. The sheer scale of transcribing antiquated law books into digitised media is no trivial task. The complexity and cost involved in creating AI-legal applications far outweigh the value they can provide to most lawyers. However taking some of the structure inherent in the latter (i.e. classifying legal cases in terms of the 'factors' they exhibit) can greatly benefit the former and recognising the limitations in the latter (AI-legal applications are at best pattern-matchers), could help form the basis of useful, cost-effective and usable applications. By indexing legal cases (and articles) according to the issues/legal concepts involved (as we have done here) rather than on a keyword basis can, it is submitted, help lawyers get quickly to information that may be of use to them and also help them to better focus and express their information needs. By applying CBR principles to a very simplified model of the law we can provide lawyers with a useful springboard into the more uncertain and unpredictable task of legal reasoning while at the same time avoid the overwhelming complexity involved in creating AI-legal applications. The Internet (or more specifically the World Wide Web) has become the forum for information gathering and will surely be an essential tool of all modern lawyers. The Java language can enable us to transform the Web into a truly interactive law library. Most modern legal information is contained (or can be structured as we have described) within databases. The Java Servlet API helps provide the processing power needed to service the complex information needs of lawyers, and can also provide the backbone on which we can construct Intelligent Legal Aid retrieval systems. [R1 ] Wall, Information Technology & The Shaping of Legal Practice in the U.K., 13th BILETA Conference <http://www.bileta.ac.uk> [R2] Galanter, Law Abounding: Legalisation Around the North Atlantic, [1992] 55 Modern Law Review [R3] Lord Woolf. Access to Justice Final Report, HMSO (1996) [R4] Electronic Law Practice: An Exercise in Legal Futurology, [1997] 60 Modern Law Review [R5] Law Commission, Shareholder Remedies (Consultation Paper 142) [1996] [ R6] Ebrahimi v Westbourne Galleries [1973] AC 360 [R7] Davies & Prentice, Gower's Principles of Modern Company Law, (1997), Sweet & Maxwell [R8] Boyle & Bird's Company Law, 3rd Edition, (1995) Jordan [R9] Mason, French & Ryan on Company Law (1998), Blackstone [R10] CELEX Database: <http://www.kun.nl/celex/> [R11] LEXIS/NEXIS: <http://www.lexis-nexis.com/lncc/custserv/html/lexis/intlaw.html> [R12] SMITH-BORNEL on-line casebase: <http://www.smithbornal.com> [R13] Combrink-Reuters & Piepers: The Use of Information Systems in Research for the Acquisition of Knowledge (1995), 10th BILETA Conference: <http://www.bileta.ac.uk> [R14] Kluwer Database: <http://epms.nl> [R15] Smith-Bornal, supra [R16] O'Shea & Wilson: Using Hypertext and Parallel Processing to integrate a European law database (1997), 12th BILETA Conference: <http://www.bileta.ac.uk> [R17] Sturdy: Wisps of Smoke? The Electronic Library, New Information Retrieval techniques and Diminishing Returns (1994), 9th BILETA Conference: <http://www.bileta.ac.uk> [R18] Matthijsson: A Task-based Interface to Legal Databases (1998\), Artificial Intelligence 7 Law, Vol.6 No.1 [R19] De Mulder et al: The Concept of Concept in Conceptual Legal Information Retrieval (1993), 8th BILETA Conference pre-proceedings: <http://www.bileta.ac.uk> [R20] Matthijsson: An Intelligent Interface for Legal Databases, Proceedings of 5th International conference On Artificial Intelligeng and Law (1995), Kluwer [R21] Aikenhead: A Discourse on Law & Artificial Intelligence, JILT 5,1: <http://www.law.warwick.ac.uk/ltj/S-lc.html> [R22] Luger & Stubblefield: AI - Structures & Strategies for Complex Problem Solving (1997), Addison-Wesley [R23] Aikenhead: Legal Knowledge-based systems: some observations on the future (1995) 2Web JCLI: <http://webjcli.ncl.ac.uk/articles2/aiken2.html> [ R24] Popple: SHYSTER: A Pragmatic Legal Expert System, PhD thesis, Australian National University, Canberra (1993): <http://cs.anu.edu.au/~James.Popple/publications/> [R25] Poulin et al: Coping with Change (1991): <http://www.confpriv.qc.ca/crdp/en/equipes/technologie/textes/ia/bratley91a.html> [R26] Bratley et al: The effect of change on legal applications (1991): <http://liguria.crdp.umontreal.ca/crdp/en/equipes/technologie/textes/ia/ [R27] Hunter & Zeleznikov, supra [R28] Morrisson & Leith, The Barristers World and The Nature of Law (1992), Open University Press [R29] Greinke, supra [R30] Leith, The Computerised lawyer (2nd Ed.) (1998), Springer-Verlag [R31] Ashley, Modelling Legal Argument (1990), MIT Press Cambridge [R32] Aleven, Teaching Case-Based Argumentation Through a Model & Examples, PhD Dissert, University of Pittsburgh Graduate Program in Intelligent Systems [R33] Davies & Prentice, Gower's Principles of Modern Company Law, (1997), Sweet & Maxwell [R34] Boyle & Bird's Company Law, 3rd Edition, (1995), Jordan [R35] Mason, French & Ryan on Company Law (1998), Blackstone [R36] Bench-Capon, Arguing with Cases (1997), Proceedings of JURIX '97, <http://jurix.nl:591/jurix/index.htm> [R37 ] Salton G (ed) (1971): The SMART Retrieval System, Experiments in Automatic Document Processing, Prentice-Hall, Englewood Cliffs, NJ. [R38] Salton G, McGill M J (1983): Introduction to Modern Information Retrieval, McGraw-Hill, New York. [R39] Schweighofer E, 'The Revolution in Legal Information Retrieval or: The Empire Strikes Back', 1999 (1) The Journal of Information, Law and Technology (JILT). <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1999_1/schweighofer/> [R40] Gudivada V N, Raghavan V V, Grosky W I, Kasanagottu R (1997): Information Retrieval on the World Wide Web, in: IEEE Internet Computing, Vol 1, No 5, 58-68. [R41] Khare, Rohit. XML: Principles, Tools, and Techniques. World Wide Web Journal Volume 2, Issue 4. Sebastopol, 1997. O'Reilly & Associates, Inc. Footnotes 1. Such as decided cases and doctrinal writings 2. Please note that this application is geared towards supporting the plaintiff and it is assumed here that the lawyer argues for the plaintiff. 3. The usefulness or relevance of which is decided by the simple strategy described above 4. e.g. if a case exhibits PPS factors then these factors could be used to advance the current case and should be stressed. However if a case exhibits TCS factors then we must explain why these factors are not of crucial importance in this case if we wish to use the case in our favour. 5. Please note no consideration has been given here to the situation where several cases may have the same point score. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||