
Evaluating the Proficiency of Generative Artificial Intelligence in University-Level Mathematics and Statistics Problem-Solving
- Home
- 1.Formal Report
- 1.1 Introduction to Project
- 1.2 The Emergence of ChatGPT and Limitations of GPT-3.5
- 1.3 Understanding LLMs and Evolution of AI Models
- 1.4 Extending LLM Capabilities and Introduction of ChatGPT o1
- 1.5 A Step Change in AI Capabilities and Key Findings
- 1.6 Performance of AI Models and Urgency for Institutional Action
- 1.7 Recognising the Problem and Specific Regulations
- 1.8 Recommendations and Conclusion
- 2. Student Conversations
- 3. How ChatGPT Performed on University-Level Work
- 4. Suggested Changes and Future Direction of Regulations
- 4.1 Developing Clear Policies on AI Use
- 4.2 Enhancing Student Support and Guidance
- 4.3 Emphasising Skills That AI Cannot Replicate
- 4.4 Adapting Pedagogy and Innovating Assessments
- 4.5 Encouraging Collaborative Solutions Among Stakeholders
- 4.6 Allocating Resources for Training and Support
- 4.7 Adopting Alternative Assessment Methods
- 4.8 Relying on Honour Codes and Academic Integrity Pledges
- 4.9 Designing AI-Resistant Assignments
- 4.10 Using AI Detection Software
- 4.11 Implementing Oral Examinations (VIVAs)
- 5 Opportunities AI Presents
- 6 Tips For Markers on Spotting Potential AI Usage
Evaluating the Proficiency of Generative Artificial Intelligence in University-Level Mathematics and Statistics Problem-Solving
This study evaluates the current capabilities of the current state-of-the-art generative artificial intelligence (AI) in solving university-level mathematics and statistics problems. The research aims to provide a nuanced understanding of AI performance in this domain, with implications for academic assessment and educational support. The study employs a zero-shot approach to assess the baseline capabilities of state-of-the-art large language models (LLM) across a diverse range of mathematical and statistical problems.
Introduction and Methodology
The rapid advancement of generative AI models has raised questions about their potential applications in academic settings. This study focuses on the specific domain of university-level mathematics and statistics, aiming to provide empirical evidence of AI capabilities in this context.
The primary objectives of this investigation are:
a) To critically evaluate the accuracy and depth of comprehension exhibited in AI-generated solutions to university-level mathematical and statistical problems.
b) To conduct a comparative analysis between AI-generated responses and those typically produced by university students, focusing on problem-solving methodologies, mathematical/statistical notation usage, and the level of detail provided in solutions.
c) To identify the potential strengths and limitations of AI models when confronted with academic mathematics and statistics problems of varying complexity.
d) To explore the potential implications of AI capabilities for both assessment strategies and educational support mechanisms in university-level mathematics and statistics courses.
The study employed ChatGPT-4o, a state-of-the-art large language model (LLM), selected for its advanced capabilities in natural language processing and problem-solving, particularly in mathematics.
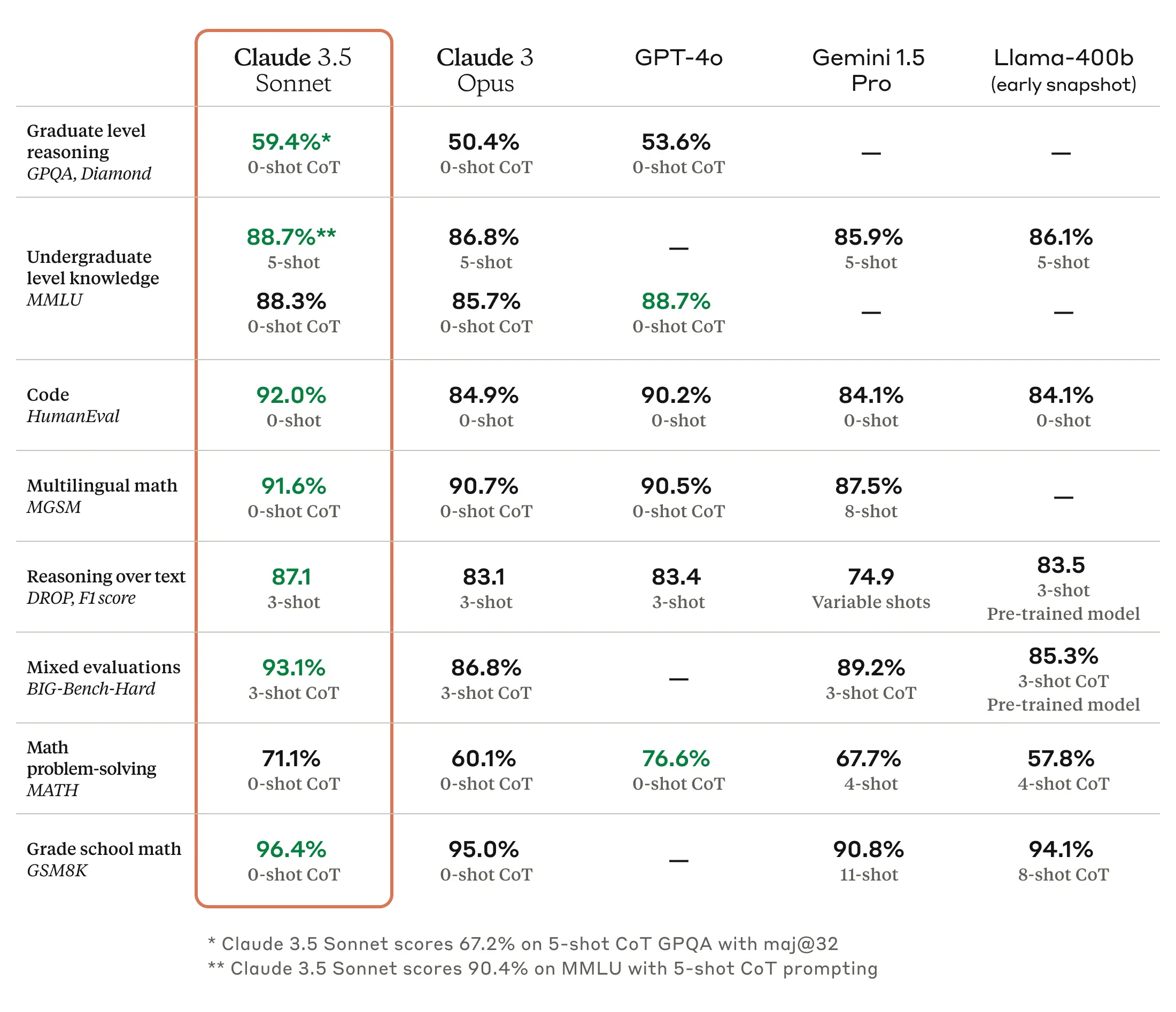
Anthropic, the company that produces the Claude range of LLMs, published information about the state-of-the-art LLMs at the time of this study. Using a zero-shot chain of thought, ChatGPT-4o was the best LLM at the time of this study.
A diverse range of mathematical and statistical questions was curated from both the Mathematics and Statistics departments, spanning academic levels from first-year to fourth-year modules. These questions were submitted from course lecturers and derived from actual assignments to ensure relevance and appropriateness.
The questions, initially in PDF format, were converted into LaTeX to input into the AI model and reduce preventable errors in the LLM's interpretation of the problems.A zero-shot approach was used to simulate more realistic student usage and assess the model's baseline capabilities. ChatGPT-4o is currently free but with usage limitations, further influencing the decision to use a zero-shot approach. There was no prior training or fine-tuning of the model on specific mathematical and statistical problem types beyond the training provided by the model's developers.
The following criteria were established to assess the performance of the AI model:
a) Accuracy and correctness of the provided solutions
b) Appropriate usage of mathematical/statistical notation and terminology c) Logical coherence of problem-solving
d) Demonstrating problem-solving ability and avoiding unnecessary explanations
e) Authenticity in emulating the work typically produced by a university student
The Data

There were 87 questions asked, with 76 coming from mathematics modules and 11 from statistics modules. 57 of the questions were first-year questions, 14 were second-year questions, and 16 were third-year or fourth-year questions.
There is a large skew towards 1st year questions, in particular mathematics questions. The questions used were submitted by professors and we received a larger volume for that area.
Ideally, a larger volume of 2-4th year questions would have been used including an increase in statistics questions. The lack of statistics questions may be because of the fact that a far larger number of mathematics modules are offered, particularly in the lower years compared to mathematics modules.
| Year 1 | Year 2 | Year 3/4 | Total Questions | |
| Mathematics Questions |
49 | 14 | 13 | 76 |
| Statistics Questions | 8 | 0 | 3 | 11 |
| Total Questions | 57 | 14 | 16 | 87 |
.

Results

| Green (100%-70%) | Yellow (69%-35%) | Red (34%-0%) | |
| Number Of Questions | 58 | 12 | 17 |
What was discovered was that ~67% of LLM solutions were designated as being in the green category meaning that they were perfect or near perfect. ~14% of the LLM solutions were designated as being yellow meaning they were an adequate solution with only a few small mistakes. ~20% of LLM solutions were in the red category meaning that they were a poor solution with relatively large mistakes.
When putting this into context with regards to university degree class borders, as seen in the table, ~67% of the LLM solutions were at a First Class classification, ~14% of the LLM solutions were between a pass and Upper Second Class classification and ~20% of the LLM solutions would be classified as being a fail. When considering green and yellow, reflecting classifications required to receive a degree, ~80% of LLM solutions would be good enough to be classified as not a fail. The LLM has an expected score of 67.16%, meaning, on average, it would be designated as an Upper Second Class (Honours) on average.
| Classification | Percentage Requirement |
| First Class (Honours) |
70.0% and above |
| Upper Second Class (Honours) |
60.0% - 69.9% |
| Lower Second Class (Honours) |
50.0% - 59.9% |
| Third Class (Honours) |
40.0%-49.9% |
| Pass |
35.0%-39.9% |
| Fail |
34.9% and below |
| Number of Questions | Year 1 | Year 2 | Year 3/4 |
| Green | 43 | 7 | 8 |
| Yellow | 9 | 1 | 2 |
| Red | 5 | 6 | 6 |
When breaking it down into a per-year basis, in percentage terms, LLM outputs for 1st-year questions were better than the percentage of all questions categorised as green, with 2nd and 3rd/4th years being lower.
In terms of LLM outputs in the yellow category, 2nd-year questions in percentage terms were better than the percentage of total questions with 1st and 3rd/4th year being worse.
For LLM outputs in the red category, 1st-year questions in percentage terms were better than the percentage of total questions with 2nd and 3rd/4th questions being worse.

It is important to remember that there was a much larger sample of first-year questions compared to other years. The results from first-year questions are more reflective of the LLM's ability.
| 1st Year | 2nd Year | 3rd/4th Year | |
| Expected Score | 73.82% | 53.5% | 55.38% |
When comparing this to students, the expected score for first-year students would sit at the upper quartile. For second-year students, third-year students and fourth-year students the expected score would be below the lower quartile.

When looking at LLM solutions categorised as red, the errors could be split into 3 groups: Misunderstood Input, Lack of Detail and Logic Errors. There were 13 logic errors, 2 errors from Misunderstanding the question input, and 2 from having a lack of details.

Out of the 17 red solutions, on 2 occasions the LLM noticed hallucinations and tried to re-do the solution but still got it wrong.
A key observation across the LLM outputs was the style of answers. They were presented in a style which is not to a university standard, they lacked notation and phrases that are expected at a university level. It is more of the standard of an A-Level, which is where LLM’s are currently lacking. Though the logic used in questions was good bar 13 questions out of 144.
Students who have an understanding of how answers should be presented in modules, without having a high-level understanding of the module, would be able to take the LLM answer and present it in a manner suitable for the module.
However, to identify logic mistakes or lack of detail reasoning errors, students would need a good level of understanding of the module. Teaching students to critically analyse LLM outputs would benefit their understanding of the module and help them in future careers if they have to use LLM outputs because it is unlikely an employer would want to simply copy and paste an output, but rather check it for mistakes, and students who could critically analyse LLM outputs would have a ‘leg up’ against other mathematics to statistics students whose university has not taught them how to do so. This may also reduce students potentially being over-resilient on using AI.

4.17% of respondents disagreed or strongly disagreed with this statement. When testing real-world assignment questions 66.67% were green (70%-100% scored).
The expected score based on the assignments marked is 67.16%, which would be in the boundary of Upper Second Class Honours.
The issues may have occurred because students were using older models, which were not trained on as much data or may not have been as algorithmically efficient as the latest models, hence why the latest models perform well. I think students would be surprised at what in reality the latest LLM’s can do.
A reason this may exist is that the notation used may be different, or often, as mentioned above, not to university standard. The logic may be correct but students may not realise that because they fixate on the notation and the way it is presented. Another potential reason is because LLM’s may give a different method for solving a problem than what a student was expecting. Often, there is many different ways to answer questions and students may assume there is one, and so see any other method as wrong, even though that is not the case. Another reason could be the types of questions students are asking. It is more likely students are asking questions they cannot solve. These questions could potentially have more logic errors.

When splitting the questions into 2 groups, 'Proof', a question which is asking to prove or show something, or 'Applied', a question that asks to apply a concept in a more specific situation. The LLM appears every year to be as good or better in proof questions than applied questions.
It is impossible to definitively say, but there is a greater likelihood of the proofs being within the training data, in which case the LLM is going to perform better.
| Green | Yellow | Red | ||
| Year 1 | Proof | 22 | 1 | 2 |
| Year 1 | Applied | 21 | 8 | 3 |
| Year 2 | Proof | 6 | 1 | 2 |
| Year 2 | Applied | 1 | 0 | 4 |
| Year 3 |
Proof | 4 | 1 | 4 |
| Year 3 | Applied | 4 | 1 | 2 |
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) benchmark measures an AI system's ability to efficiently learn new skills. Humans easily score 85% in ARC, whereas the best AI systems only score 34%.
The ability of an LLM to have 'mathematical thinking' is its limiting factor. Across the questions, this limitation was seen and would likely result in the questions marked as red becoming yellow or green and the yellows becoming green.
Artificial General Intelligence (AGI) is the aim of companies such as OpenAI, and may not be far away. Whilst it is currently at this time not possible to say when this will be achieved, OpenAI has been hinting at possible releases of AGI, and currently, a competition on Kaggle exists trying to improve AGI.
If AGI were to improve from 34% on the ARC-AGI to even 50%, the results above would likely be different with a higher number of questions marked green and lower numbers of questions marked yellow or red.
Conclusion
Generative AI is here to stay and will only get better. Progress in Artificial General Intelligence (AGI) could lead to major improvements in AI, allowing it to answer an even wider range of questions at a high level. Trying to create assignments that can't use AI is like trying to make assignments where traditional cheating methods are impossible - it's not realistic.
Assignments usually make up a small part of a module's final grade. Students who rely too heavily on AI without truly understanding the subject will likely struggle in final exams, where such tools aren't available.
Many employers will expect graduates to know how to use AI effectively. Universities need to teach students how to use AI well, especially how to critically evaluate AI outputs. One good way to do this is to include questions in assignments or exams that ask students to analyze an AI's answer to a relevant problem. For example, give students an AI-generated solution and ask them to point out mistakes, unnecessary explanations, or steps that need more detail.
Lecturers should also test their assignments with AI tools to make sure the questions aren't too easy for AI to solve, which could make cheating tempting for students. When marking, it's important to watch for signs that AI has been used inappropriately. Currently, students can use AI if they maintain intellectual ownership of their work and properly cite how and where they used AI. However, simply copying AI-generated text is not allowed.