
Michael Pearce
I am working on a new personal page www.BayesianBlog.com

I work with Gaussian Processes as surrogate models for model based optimisation, algortihms for efficient sequential data collection. When there are multiple objectives one problem setting is when a user must pick a single input that comprimises between objectives (traditional multiobjecitve optimisaiton). In another setting we study, a user aims to find separate inputs to optimise each objective (multi-task optimisation or policy learning). In June-Oct 2018, I did an internship at Google Deepmind in London UK. In March-July 2019 I did an internship at Uber AI Labs in San Francisco.
Email: m.a.l.pearce[at.mark]warwick.ac.uk
Github: https://github.com/scrambledpie
Linkedin: https://www.linkedin.com/in/michael-pearce-3a8b18b6/
Download my academic CV here: MichaelPearceCV_Academic.pdf
Download my non-academic CV here: MichaelPearceCV_NonAcademic.pdf
Google Scholar: Michael Pearce
Publications
- Continuous Multi-Task Bayesian Optimisation with Correlation, Michael Pearce, Juergen Branke. To appear in European Journal of Operational Research
- Bayesian Simulation Optimisation with Input Uncertainty, Michael Pearce, Juergen Branke. Winter Simulation Conference 2017. This paper won Informs best student contributed paper.
- Efficient Expected Improvement Estimation for Continuous Multiple Ranking and Selection, Michael Pearce, Juergen Branke. Winter Simulation Conference 2017
- Value of information methods to design a clinical trial in a small population to optimise a health economic utility function, Pearce et.al. BMC Medical Research Mthodology
- Approaches to sample size calculation for clinical trials in rare diseases Miller et. al. To appear in Pharmaceutical Statistics
- Recent advances in methodology for clinical trials in small populations: the InSPiRe project, Friede et. al. submitted to Orphanet Journal of Rare Diseases
- Bayesian Simulation Optimization with Common Random Numbers. Pearce et.al. To appear Winter Simulation Conference 2019
- Comparing Interpretable Inference Models for Videos of Physical Motion Symposium on Advances in Approximate Bayesian Inference 2018
- On parallelizing Multi-Task Bayesian Optimization Groves, Pearce, Branke, Winter Simulation Conference 2018
Submitted Papers
- Multiple Ranking and Selection with Gaussian Processes, Michael Pearce, Juergen Branke. 2nd reviews at Informs Journal on Computing
Conferences, Workshops and Activities
- Winter Simulation Conference 2017, PhD Colloquium (slides), BayesOpt with Input Uncertainty (slides), Multiple Ranking and Selection (slides)
-
The Genetic and Evolutionary Computation Conference 2017, 2018, programme committee member.
- Introduction to Machine Learning Summer School, Warwick Mathematics Institute, I helped make tutorials series on nerual Networks .
- Warwick Summer School on Complexity Science 2015, Gaussian Process Regression talk (slides).
- Data Study Group, Alan Turing Institute May 2017, Siemens, optimising traffic lights to minimise pollution (slides, video)
- Data Study Group, Alan Turing Institute Sept 2017, Cochrane Reviews, automating allocation of research papers to reviews
- Complexity Summer Retreat 2017, my (award winning!) slides on "Deep Linear Regression and Wide Learning"
- Mondays 4pm, come join the Machine Learning discussion and speaker series run by Iliana Peneva and Jevgenji Gamper.
About Me
Although I find myself getting excited by anything machine learning, my interests are in Bayesian Statistics and Deep Neural Networks (cycleGAN is amazing!) and my PhD work is focused on Gaussian Process regression and their use in active learning. Particularly I have worked a lot with the Efficient Global Optimisation (EGO) and Knowledge Gradient algortihms.
Outside of academia, I am also mad about bikes and snowboarding, I love to ride my road bikes and my trials bike and visit the snowy Alps at least once a year. I like to think that I can speak Japanese (passed JLPT N2) and I am slowly learning Spanish.
My PhD Work
Imagine a user who is a faced with an optimisation problem where the objective function is hard to model and expensive to evaluate. For example tuning hyperparameters of machine learning algorithms. Active learning is the branch of machine learning where the training data is collected adaptively in an optimal fashion for a particular goal. Within this, field of Bayesian Optimisation is using Gaussian Process Regression to cheaply interpolate and statistically predict the large expensive objective function using only a few function evaluations. Then one can use the cheap model to guide the search for the optimum of the expensive function ensuring that every time the expensive function is evaluated, each new value gives the maximum information gain thereby fewer evaluations are required to find a satisfactory optimum. Hopefully, after a while a user will have collected a dataset that is the best possible dataset for this particular purpose! The start of my PhD has been using these methods for the case when there are multiple objective functions that are independent and/or correlated with one another and the goal is to find the unique optimum for each function.
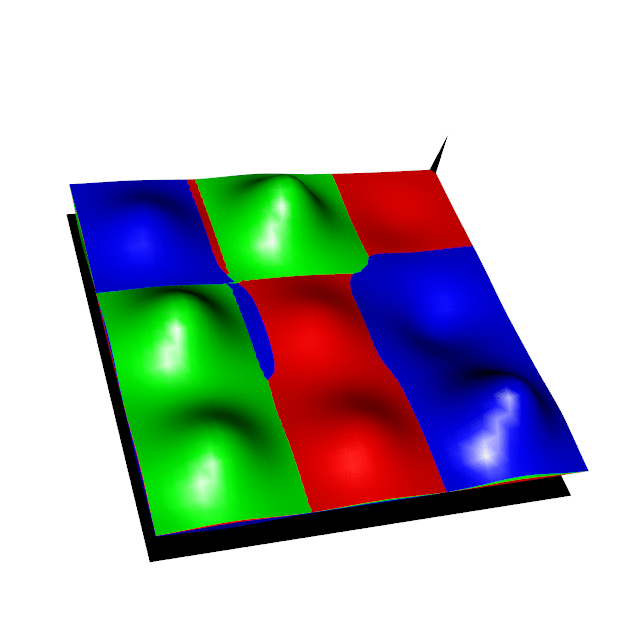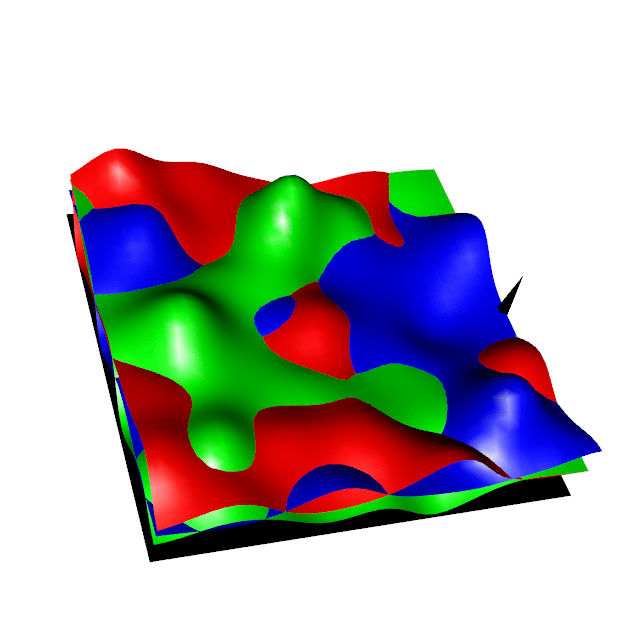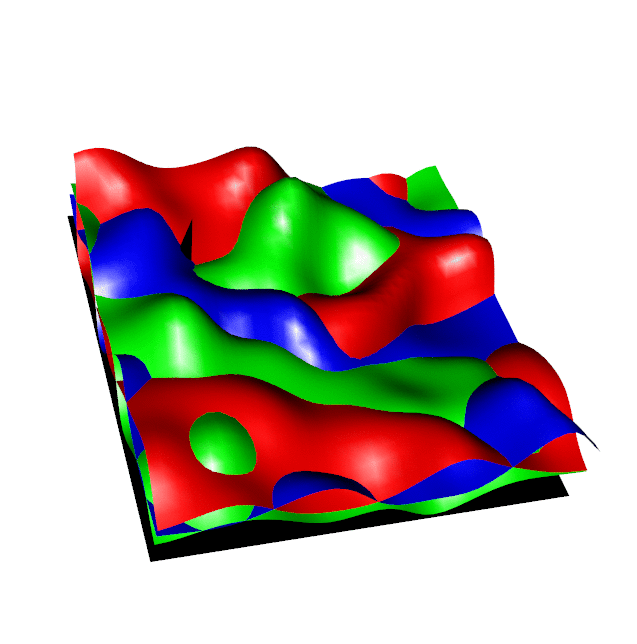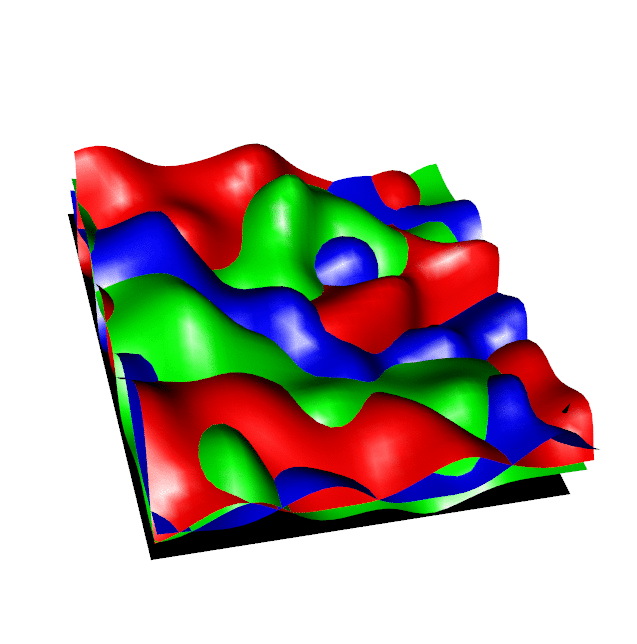
In a simple discrete case, this is like finding the "ceiling" of multiple overlapping expensive functions, for each point in a 2D plane we aim to find the highest of the available funtions ensuring that each new function evaluation has maximum information gain about the ceiling overall. We derive the Regional Expected Value of Improvement (REVI) and an implementation of this procedure is given in the right hand animation below, the coloured surfaces show the Gausian Process estimate of each function and the black point shows where the new function is selected for evaluation.
The most general case of this framework is learning the optimal points of a function for a range of parameters, for example in reinforcement learning, one may want to know the best continuous action that optimises the instantaneous reward for each unique (possibly continuous) state.
MSc Work and other Projects
In my Msc Projects I used deep convolutional neural networks for image classification and in my second project my supervisor and I built an agent based housing market to invesitgate the effects of interest rates and doposit sizes on stability in the mortgage market. In my PhD I have used genetic algorithms to optimise sample allocations, support vector machines for algorithm selection, Gaussian Processes for surrogate modelling, Markov-Chain Monte-Carlo for sampling hyperparameters. Previously at a Study Group at the Alan Turing Istitute my teammembers and I used Q-learning to optimise traffic light emmmisions which was a lot of fun. At a more recent event we used word embeddings and neural networks and t-SNE to visualise and classify medical papers into review groups.
Medical School Internship
I spent 6 months in 2016 working on the Inspire Project for clinical trial design in small populations (rare deseases) with Dr. Siew Wan Hee, Dr. Jason Madan, and Prof. Nigel Stallard. We developed hybrid Bayesian-frequentist models, the trial designers have prior knowledge about a new treatment from previous trials and therefore can use bayesian statistics. However a regulator requires a p-value and a frequentist hypothesis test with a predetermined significance level, usually 5%, we aimed to make models that fulfil both these criteria.