
Training Sets
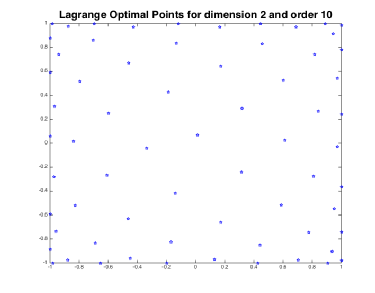
Lagrange Optimal points
Our first candidate for a training set are the Lagrange optimal points which are based on the Lagrange characteristic polynomials.
Let be the set of polynomials on
with total degree at most
and let
. For
consider
, the Lagrange characteristic polynomials, defined so that
which form a basis of
. They can be written in terms of Vandermonde determinants,
where is such that
. Recall that the Lebesgue constant
of
is defined by,
We are interested in the solutions of the following optimization problem,
These solutions constitute the definition of the Lagrange optimal points.
Clenshaw-Curtis points
Consider the -th degree Chebyshev polynomial
defined by
. The Gauss-Chebyshev-Lobatto points (of degree
) are the extrema in
of
. They are given by the explicit formula:
The Clenshaw-Curtis points are the nested subsequence of such points with
A property of the Clenshaw-Curtis points that can be easily deduced from the explicit formula above is the asymptotic (for large) clustering of points near the boundary (i.e. near -1 and 1).
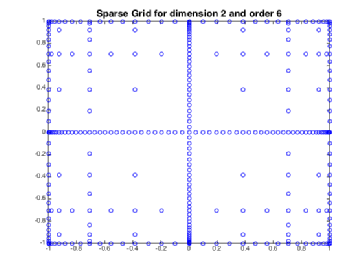
Sparse Grids
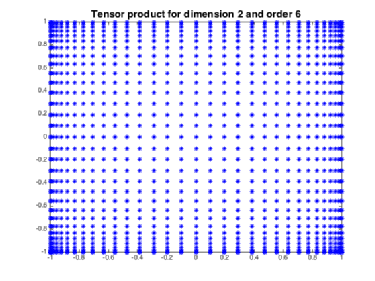
Previously we discussed the one dimensional Clenshaw-Curtis points and now we would like to go to an arbitrary dimension 1. As soon as we try that we run into the Curse of Dimensionality: If we took the full tensor product of
one dimensional points we end up with
points in
dimensions which is far too big a number for numerical schemes. The technique of Sparse Grids allows us to overcome this problem.
We start off with one dimensional points
. We would like to build a collection
of
-dimensional points, our sparse grid. Let
be a multi-index and consider the norm
and let
Take a nested family of collections of points so that
for all
,
if
and
Now define the sparse grid in dimensions as follows,
One should note that even though the actual points in the sparse grid depend on how we chose the nested family , the cardinality of the sparse grid is independent of this choice.
Other points that we have used as training sets are :
- Uniform Grid points.
- Random points.