
Sound Samples and Discussion
Sound files are found on SoundCloud at this address: https://soundcloud.com/joe-rosettenstein/sets/text-to-music
"Vowel Examples" - First, a demonstration of the standard SuperCollider classes 'Formants' and 'Vowel'. Five vowel sounds are played one after another. The artificial sound is characterstic of additive formant synthesis, which is restricted to a relatively small number of frequencies and thus is a poor replication of a real voice.
The entire code fits onto one screen and is a good illustration of how SuperCollider works:
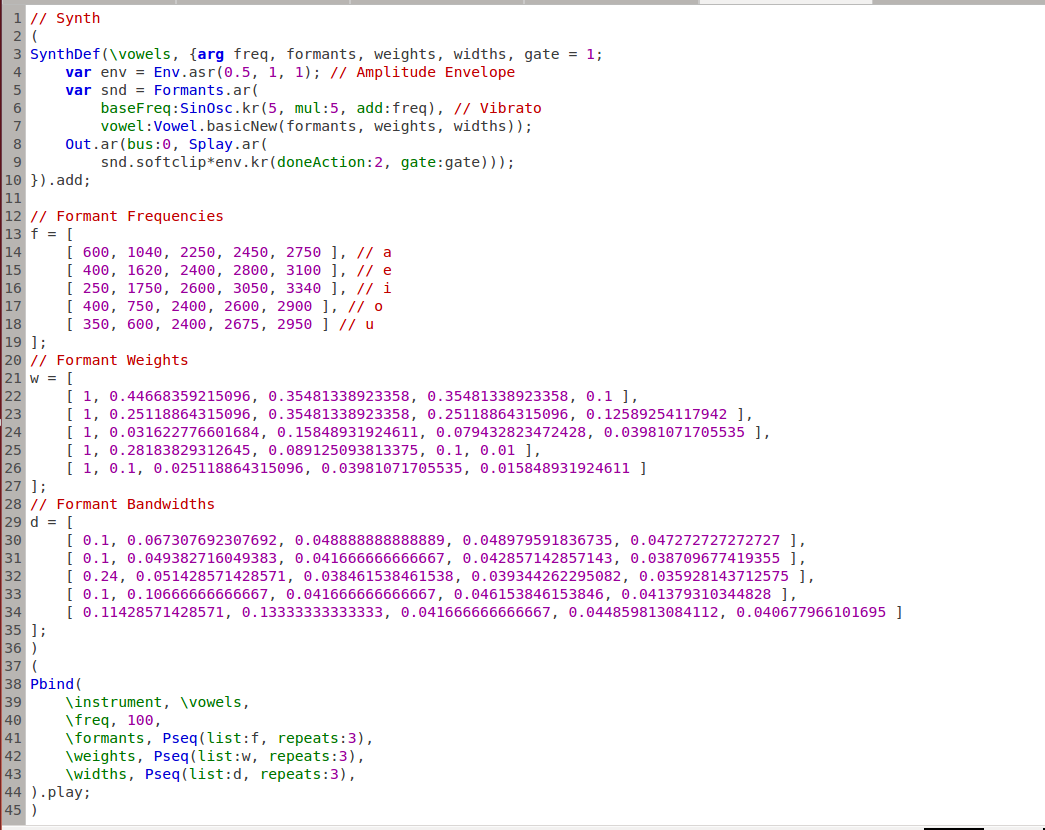
First the synth is created/defined. The formant parameters are arranged as lists of lists, which the Pbind cycles through one element at a time.
As an example, the spectrum resulting from the vowel 'a' ('AA' in ARPA representation) as in 'car' is shown in Figure 1 below. The first line in each list 'f' (formant frequencies), 'w' (relative weights) and 'd' (bandwidths), makes up figure 1 below. Close examination shows that the three peaks correspond to formant frequencies in the list, and that the associated bandwidths and weights are also manifest in the frequency spectrum. The third peak is actually three peaks combined, but the logarithmic scale means that they fall closer together on the frequency spectrum than one might expect.
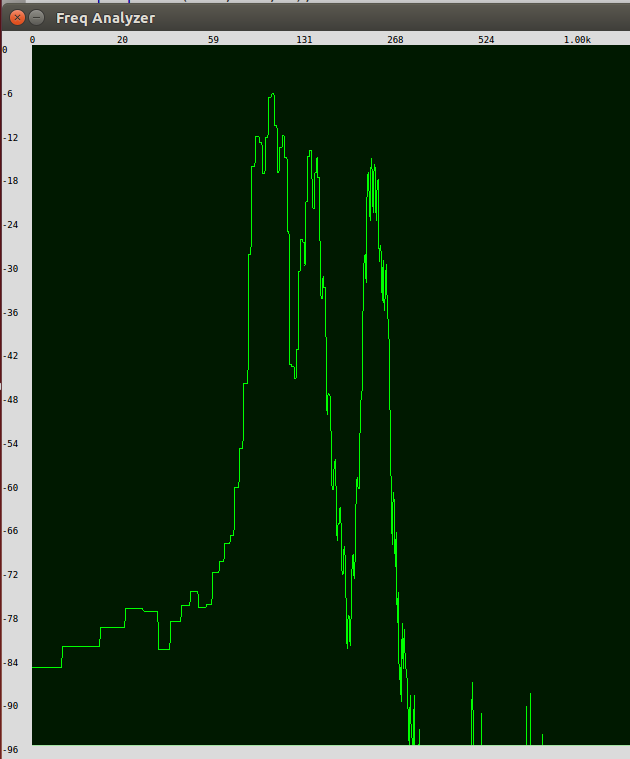
Figure 1: Frequency spectrum of the vowel "a", generated by the 'Formants' UGen and measured using SuperCollider.
If the UGen (unit/signal generator) Formants is exchanged for a stack of band-pass filters (BPFStack) which act upon an noisy input, the sound produced sounds more like a real voice, since it better imitates the real, physical mechanism for voice production. This is subtractive synthesis, where a harmonically rich input is filtered at certain frequencies - in this case, the formants. The result is a similar spectrum to figure 1, which is shown in figure 2.
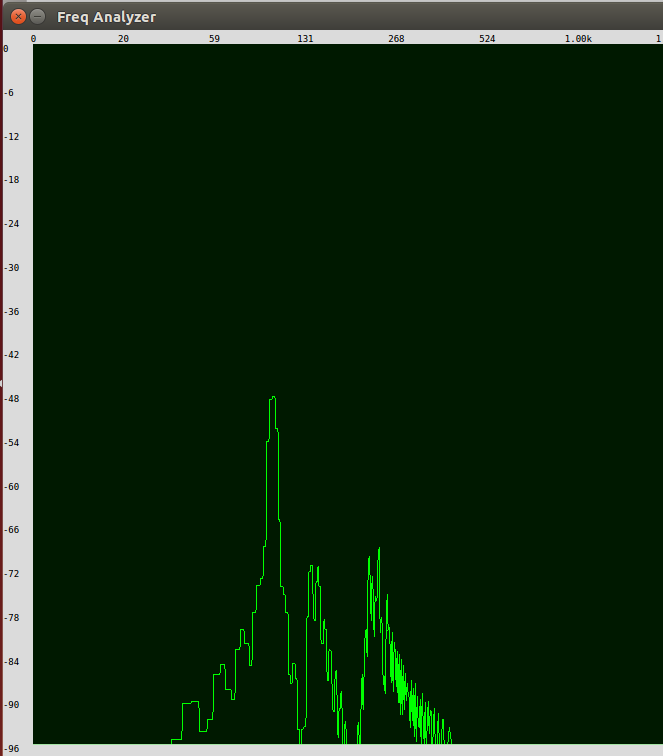
Figure 2: Frequency spectrum of the vowel "a", generated by the a band-pass filter stack acting on a noisy input UGen and measured using SuperCollider.
The lower amplitude is due to there being a single signal which is filtered rather than multiple signals added together. However, the same three (well, five) peaks at the same frequencies as figure 1 can be seen, which correspond to the Formants associated with the a certain "a" sound at this particular base frequency.
-------------------------------------------------------------------------------------------------------------------------------------------
Who let the Dogs out?
The first verse and chorus of 'Who let the dogs out?' by Baha Men was converted into sound.
"Piano Roll" uses the default SuperCollider synth, and quite simply relates phonemes to scale degrees, durations and amplitudes.
Entropy = 0.9, Scale = Neapolitan Major
"Additive synthesis 3" ignores consonants, and uses additive synthesis to recreate the vowel sounds heard. Only two formants are used, but this is all that is necessary to distinguish vowel sounds, as demonstrated by Figure 3:
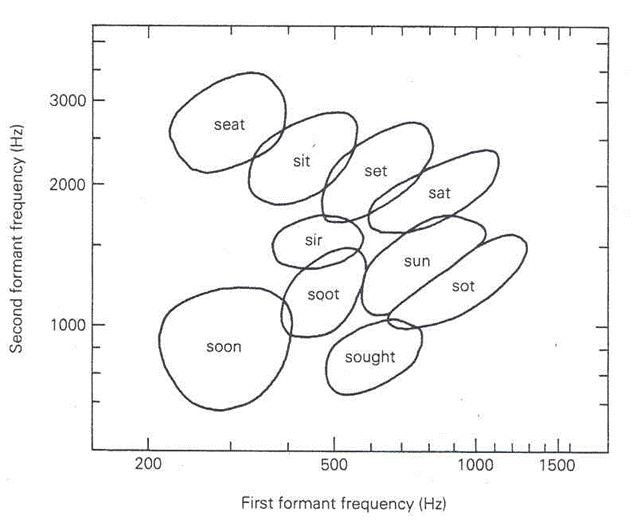
Figure 3: positions of the first and second formants of various vowel sounds on a frequency scale. Credit to Dan Boye, http://www.phy.davidson.edu/fachome/dmb/digitalspeech/formantmap.gif
Entropy = 0.7, Scale = Melodic Minor
"Additive synthesis 1 & 2" includes consonants, which are given the same formant frequencies as the succeeding vowel, but a more percussive envelope. This really needs more development; the idea was to make a separate percussive synth for the non-vowel phonemes but running parallel Pbinds was more difficult than first anticipated, and another workaround was not thought of in the time.
Entropy = 0.1, Scale = Romanian Minor & Major Pentatonic
"Subtractive synthesis" uses some code written by Bruno Ruviaro which performs subtractive synthesis using a band-pass filter stack. It is far more recogniseable as a voice, and this can be attributed to several factors:
- Subtractive synthesis results in a more harmonically varied sound, which better resembles the complex process of voice generation than additive, which is made of relatively few frequencies.
- Information about 5 formant frequencies, their bandwidths and relative weights is used in this code, whereas the lack of available information of formants resulted in the previous code, which was written from scratch, containing only 2 formants of equal bandwidth and weight - a very poor approximation to the real thing!
- This synth contained a randomly varying vibrato speed and depth, whereas the previous ones had constant speed and depth. Slight random variations are present in almost all natural sounds, whereas constancy is usually found only in artificial sounds; singers will always have a small amount of variation in their vibrato.
The main drawback of this code is that it only contains five vowel sounds (a, e, i, o, u) whereas, as we know, there are over a dozen different phonetic vowel sounds. It does strike one, when listening to the output, that the sound mostly consists of "ee's" and "aah's", 'a' and 'e' being the most common vowels.
Even so, credit must be given to the creator for making a really cool artificial voice. I would like to expand on this given the chance.
Entropy = 0.3, Scale = Melodic Minor
------------------------------------------------------------------------------------------------------------------------------------------
A Nice Poem
A nice little children's poem was converted into sound:
"Piano Roll" again simply uses the default synth.
Entropy = 0.9, Scale = Ionian
"Additive synthesis" uses only vowels, as in the previous example Additive synthesis 3 (who let the dogs out).
Entropy = 0.7, Scale = Melodic Minor (descending)
-----------------------------------------------------------------------------------------------------------------------------------------
Poo Choo Train
This delightful tune, sung by South Park's Mr Hankie and Eric Cartmen, has been reinterpreted using our program.
"Subtractive synthesis"
Apart from being a neat song, Poo Choo Train was chosen because it contains several "ooh's" and "uh's", which were scarce in previous implementations of this code (as mentioned, it mostly sounded like "ahh" and "ee"). An addition was made which changes the octave of the output when a new singer takes over. This was done manually but has an interesting effect, and I think it would be worth automating changes in the octave at approprate points in a text.
Entropy = 0.5, Scale = Melodic Minor (descending)