Method and Discussion
Phonetic Decomposition and Python's Natural Language Toolkit:
[John]
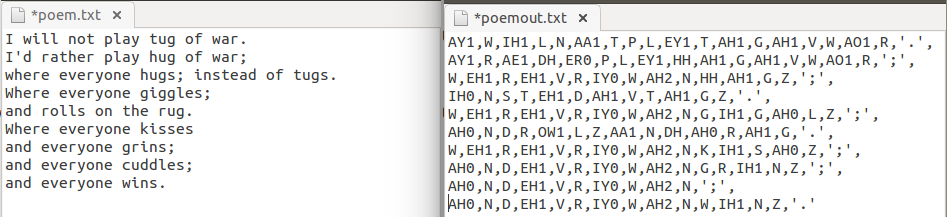
Here is an example of a children's poem being broken down into its constituent phonemes, in ARPA representation.
Representation:
The heart of the programme is the beats pumped out from punctuation, stresses and phonemes that gurgle into its inways from the stream my programme pours, without it the music stops. The stream must be unsullied, with cruft like unexpected characters, in part and structure: no mismatched quotes, bad encodings or hanging commas allowed, otherwise you will hear the dreaded siren of the syntax error. To ensure this, I carefully managed to eviscerate the leaden trappings that my tokeniser, an algorithm extracting words and punctuation from the gloop of line breaks and chapter headings, left behind for me to find. But, what if six weeks hence I had wanted to include spaces after all? What about come the summer term, keeping the dead-headed punctuation from the tokeniser might be useful? And, years forward, that poor student, up late by the light of the anglepoise, who studying an algorithmic music course finds my code, but alas needs to seperate by clauses instead, and is then driven back to the lost search for code before the lonely day-rim of the world appears outside the window. Instead everything must be abstract, and so it is. Every default is an option, every library an injection into a constricted vein of code through which the text must pass. A text is not simply a string of characters, but a type ready to be leveraged by an unseen multitude of future programmers envisaging use-cases which would make my mind wretch at the very idea of the convulsions it would have to undergo to understand them. My code is object-oriented.
Speed:
Taking the entire text of Paradise Lost and decomposing every, single, last, sentence, into its constituent parts of each and every piece of punctuation from the lowly apostrophe to the most sublime semicolon, and taking each of those lugubrious long words and exploding it into its exquisite entrappings of the sound of the tongue tapping on the palate, the back of the front teeth, between the teeth, on the teeth, roiling back against throat, curled into an o, the stress of the air passing over, beneath, in the smallest gap between two tweeth. Do it in a second.
Interface:
The user, in our case, another programme, Supercollider, could be another human too, this is the beauty of using a command line interface. As the programme accepts just two arguments, a text file to read, and a text file to write the output to; a human user does not even have to know anything about operating a command line by piping text between programmes, my programme takes care of all this for them. The result is a programme that's ready for use in a whole variety of situations where representing a text as its sounds could be useful, while allowing someone at any level of technical expertise to jump in and tinker at an appropriate level.
Formant Synthesis and Supercollider:
[Joe]
Reading the data:
A sensible way to structure the phonemes would be as a list where each element is either a word (another list) or punctuation. However, SuperCollider is not designed to deal with these data structures in the way that Python does. This leaves the option of reforming the structure within the SuperCollider environment, or keeping it more simple and using the pre-built class 'CSVFileReader' to read in the flattened list. This comes at the expense of losing information about word length. I went for the latter option for simplicity, but other developers may well see benefit in doing otherwise, or else preserving word length information by inserting a special character between words.
User input(s):
The user may choose the level of disorder of the piece; currently, there are five levels of disorder between 0 and 1. As entropy is increased, the number and complexity of available scales and key modulations increases, as does the number of available scale degrees, durations and amplitudes. As an example: a low entropy interpretation may be played in a pentatonic scale with two possible note durations in the ratio 1:2, whereas a high entropy interpretation may use a diminished scale and include triplets. There is also the option to choose the tempo and root note of the piece, as well as the scale if desired.
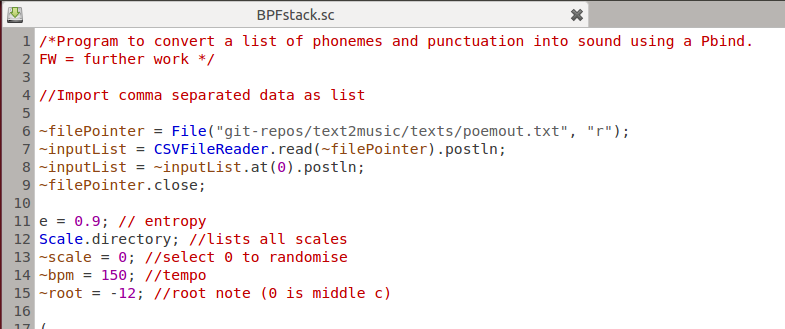
Here are the first few lines of the program, where data is imported and parameters are defined:
For comparison, here is the output created using the same text with the only difference being the entropy, which is first at its lowest value, then at its highest, then in between.
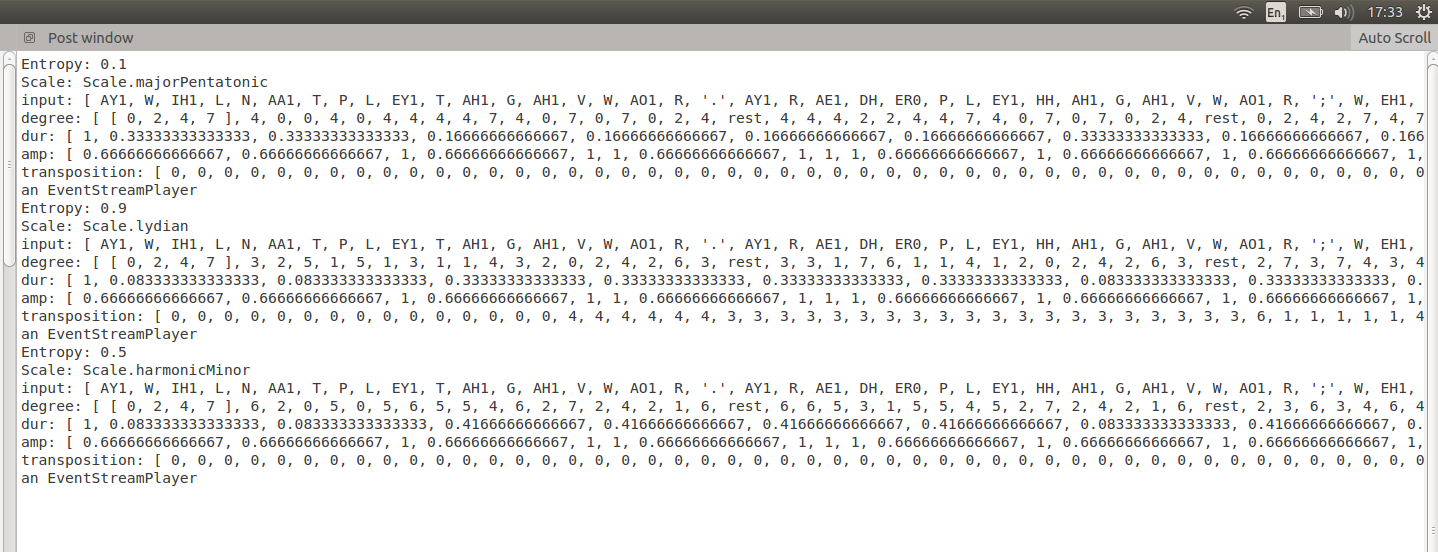
The difference between low and high entropy is quite dramatic: The major pentatonic scale is one of the simplest, whereas the higher entropy versions have more complex scales. The highest entropy run-through also contains many key transpositions, although it is unusual for the medium entropy version to have none.
Generating values for the Pattern Bind to play:
Stress levels are removed from the end of each phoneme and stored for potential use in amplitude envelopes. For each phoneme in the input, the program searches the map for the matching key, and lists are filled with the corresponding values, e.g. note durations, formant frequencies. In an exception, the key transposition list is filled out using a coin-flipping simulation with a probability of transposition related to the entropy. An observation is that the program is quite inefficient, since for each phoneme the map is searched in a linear fashion. If the input consisted of numbers instead of the phonemes themselves, a more efficient search algorithm could be employed to find the correct entry in the map.
Below you can see the map used for most of the recorded tracks (a few times I used a different map with five formant frequencies). Finding data on formant frequencies was a challenge, and the entries with [500, 1000] in represent vowel phonemes for which I could not find formant data (they involve some different mouth shapes and don't seem to be discussed much in terms of formant frequencies). An explanation for this lack of data is that it is quite difficult to pin down formant frequencies since they vary from person to person according to the size and shape of their voice-production system. I found values for the frequencies of five formants, as well as their bandwidths and weights, but only for five vowels. The results can be compared.
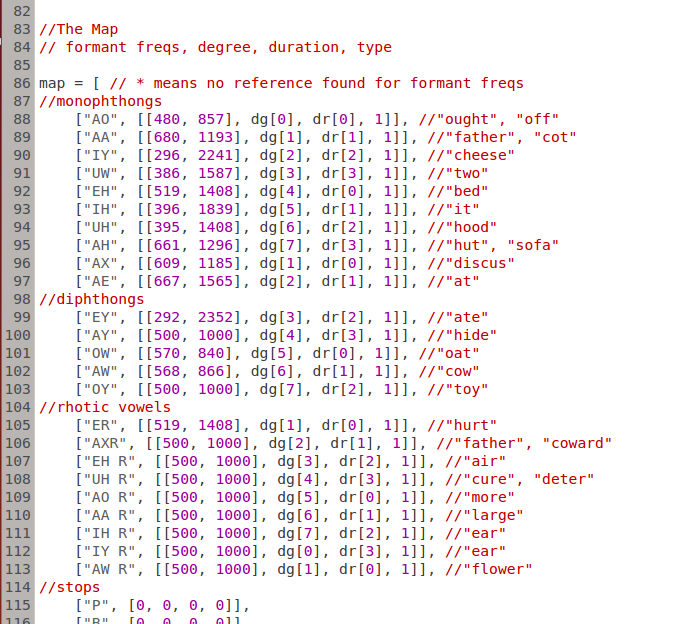
In this particular version of the map, degrees and durations are randomised in the following way: 'dg' and 'dr' are lists containing available values; they are shuffled around at random; the map selects one of the values given by its position in the new, shuffled list, e.g. 'dg[0]' pulls out the first member of the degree list.
Synths:
The default synth (piano) is used for the simple case of mapping different phonemes to different notes and durations.
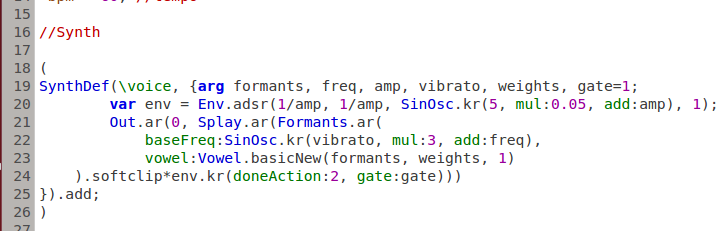
In the other examples, the aim was to devise a synth which resembled a robotic voice, with the intention of being able to hear the characteristics of the text as speech. A synth is used which uses the Formants class to emulate vowel sounds. This is an additive synth, which builds harmonics around a chosen fundamental, within a structure resembling formants. An alternative synth, written by Bruno Ruviaro, works as a kind of band-pass stack, where the formant frequencies, relative strengths and widths are taken as arguments. The subtractive synthesis sounds more convincingly like a voice due to it's closer resemblence to the real, physical method of voice production, and because it contains a greater number of frequencies since it starts with noise and subtracts, rather than adding individual frequencies together.
A vibrato is added to make the voice sound more realistic. Also included is an attack-sustain-decay-release (ADSR) amplitude envelope to give the impression of a continuous voice, but this is certainly an area where further work would into more realistic transients would yield a far more convincing vocal synth.
Below is a snippet of code containing one of the synths used to perform formant synthesis:
Playing the music:
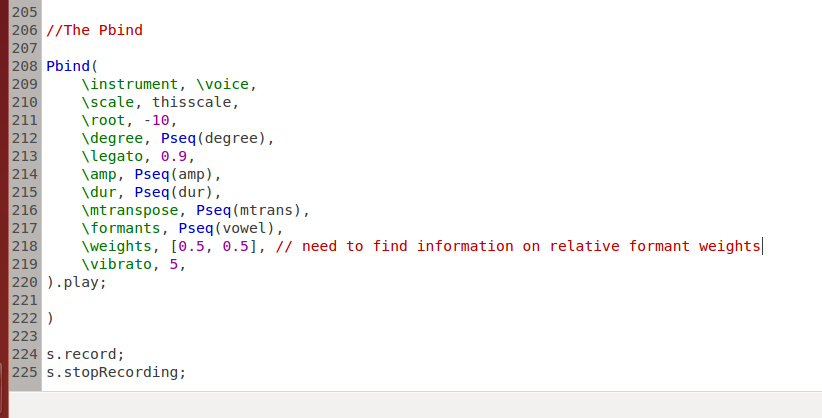
A Pbind is employed to play a sequence of events governed by the input lists. The frequency argument in the synth is related to the parameters 'scale', 'root', 'degree' and 'mtranspose'. All of the other parameters feature in the synth with the same label. The output is recorded using server.record.
Here is the essence of a Pbind, which plays a sequence of notes with parameters which may be sequences themselves. Unfortunately I did not find information on the relative weights of the first two formants, except for the five vowels for which there was information on five formant frequencies.
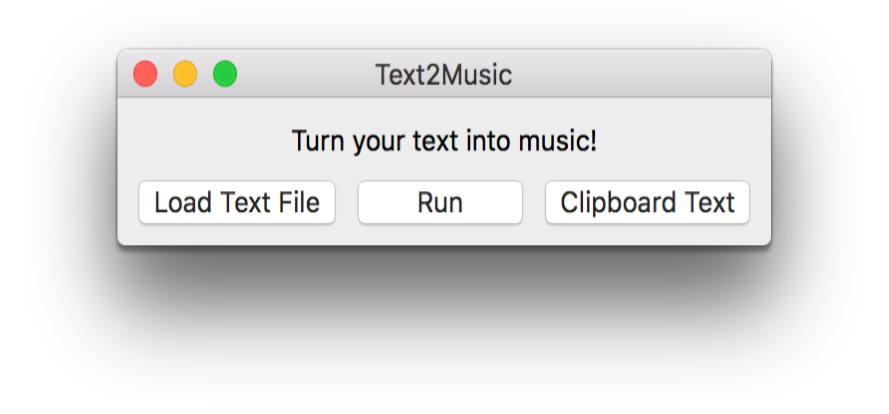
Graphical User Interface
wxPython is a GUI (Graphical User Interface) toolkit for the Python programming language, and allows Python programmers to easily create programs with a robust, highly functional graphical user interface. It is implemented as a Python extension module (native code) that wraps the popular wxWidgets cross platform GUI library written in C++. Using OOP syntax, wxPython is open source, and supports Windows, Unix-like systems (such as the various flavours of Linux), and Mac OSX. It is an important tool for ease of use; most everyday users may be unfamiliar with running programs via the command line, and a GUI solves this problem. It is a staple of modern, consumer-based, software to have a GUI.
The GUI has a simple window, and looks different depending on which operating system is in use. The user can load a text file, and run the program using this text. They can also use text copied to their clipboard.