
Hidden Markov Model
The Basic Framework
The standard HMM relies on 3 main assumptions:
1. Markovianity
The current state of the unobserved node depends solely upon the previous state of the unobserved variable, i.e.
2. Output Independence
The current state of the observed node depends solely upon the current state of the unobserved variable, i.e.
3. Stationarity
The transition probabilities are independent of time, i.e.
The first two assumptions are best understood when considering a graphical representation of the HMM. Directed acyclic graphs (sometimes simply referred to as DAGs) are graphs in which nodes represent random variables whilst edges represent statistical dependencies between the nodes. As can be seen below, observed nodes depend solely upon the current state of the unobserved node, which reflects Assumption 2 above. Moreover, unobserved nodes depend on the previous state of the latent variable, reflecting the Markovian nature of the latent variable (Assumption 1 above). Indeed, if the latent variable is considered in isolation, then this forms a Markov chain.
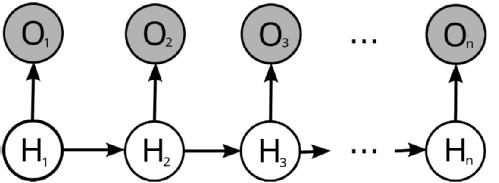
Assumptions 1 to 3 allow for an easy factorisation of the joint distribution of and
. Namely, if we consider the above figure, we note that
is the only node which doesn't depend on any other node in the diagram. Thus we can extract the term
from the joint distribution and condition the remaining nodes in the graph on
. As
depends solely upon
, we can extract the factor
and condition the remaining nodes in the graph on
. Proceeding iteratively in this manner, we observe that we get the following decomposition of the joint distribution
where we have omitted the values which and
assume to reduce on encumbrance. This decomposition is particularly useful as it allows us to describe the entire model solely via two matrices, which are easily interpreted and intuitive: the transition matrix
which gives the transition probability from state to state
for the unobserved variable, and the emission matrix
which gives the probability of the observed variable emitting symbol given the current hidden state is
.
Inference - the Baum-Welch Algorithm
Having derived the modelling framework, we now shift our focus to conducting inference on the matrices and
. To this end, we shall outline the Baum-Welch algorithm which consists of 3 main steps: the Forward pass, the Backward pass and the EM step. The Baum-Welch algorithm turns out to be a particular instance of the EM algorithm, whose major advantage is that estimates are re-calculated at each iteration, and each subsequent re-estimate is as good as, if not better than, the previous estimate. We now move on to explaining the three parts constituting the Baum-Welch algorithm, before providing a pseudocode highlighting the main steps of the algorithm.
The Forward Pass
The Forward Pass computes the likelihood of a particular sequence of observations. The challenge is naturally the fact that the observed sequence depends on the hidden sequence (which we do not observe). Thus we need to condition on the values assumed by the hidden variable and then average over all possible configurations for the hidden sequence. Using the notation we introduced above, we have that
Clearly, as the number of elements in increases and as
grows, the number of computations required to calculate the above quantity in a reasonable amount of time becomes very quickly impossible for most machines. To this end, we introduce the forward trellis
from dynamic programming, which represents the probability of being in state
after observing the first
observations, i.e.
. The reason why the forward trellis is so useful is that it satisfies a neat recursion, namely
The Backward Pass
The backward pass concerns itself with computing the probability of observing a sequence of states for the observed variable in the future, given the current hidden state. We denote this as , and as for the Forward Pass we have a neat recursion which simplifies computation:
The Expectation-Maximisation Step
As the name implies, the EM step will have two main steps: taking expectations and subsequently maximising. We start with re-estimating the transition matrix for the hidden variable T.
Re-estimating T
Define to be the expected number of transitions from state i to state j for the hidden random variable, normalised by the expected number of transitions going out of state i for the hidden variable. Computing
can be simplified by introducing an auxiliary variable
, which denotes the probability of the hidden state taking the values i and j at times t and t+1 respectively, given the observations
up to time t assume the values
. Indeed, if we have computed
, then we can compute
since
using the Markov property. So we can now consider computing the , for then we have obtained the re-estimate
. To compute this, we make use of the definition of conditional probability together with Assumptions 1 and 2 to get
Re-estimating E
We apply the same reasoning as above, namely we let be the expected number of times we observe symbol k when the hidden variable is in state j, divided by the expected number of times the hidden variable is in state j. Once again, computing this quantity can be simplified by introducing an auxiliary variable. Indeed, let
, then we observe that
and thus, as for the above, we get that
Baum-Welch Algorithm Pseudocode
Initialise
While
Compute
Compute
Return
We point out that in the above, is some metric defined on matrices,
is some pre-specified threshold,
and
denote the re-updated estimates of T and E at the
iteration, and
and
represent the final estimates for T and E.
Links:
Homepage
HMM
Prototype Model
Image Analysis
Code
H. Bharth
J. Kiedrowski
J. Sant
J. Thomas
Supervised by:
Dr Björn Stinner
Dr Stefan Adams