
Biomedical Question-Answering
Summary
How to quickly boost language models for emerging topics, (e.g. COVID-19), within the biomedical domain?
Most of the existing works have been so far focused on fine-tuning language models (LM) for new domains, but what about being able to specialize LM to new rising topics (e.g. COVID-19 literature) within that particular domain?

Figure 1: An excerpt of a sentence masked via the BEM strategy, where the masked words were chosen
through a biomedical named entity recognizer. In contrast, BERT (Devlin et al., 2019) would randomly select the words to be masked, without attention to the relevant concepts characterizing a technical domain.
We propose a simple yet unexplored biomedical entity-aware masking strategy (BEM) to bootstrap domain adaptation of language models for biomedical question-answering (QA). BEM aims to enrich existing general-purpose LM models with knowledge related to key medical concepts through a biomedical entity-aware masking strategy encouraging masked language models (MLMs) to learn entity-centric knowledge. We first identify a set of entities characterizing the domain at hand using a domain-specific entity recognizer (SciSpacy), and then employ a subset of those entities to drive the masking strategy while fine-tuning (Figure 1).
Description
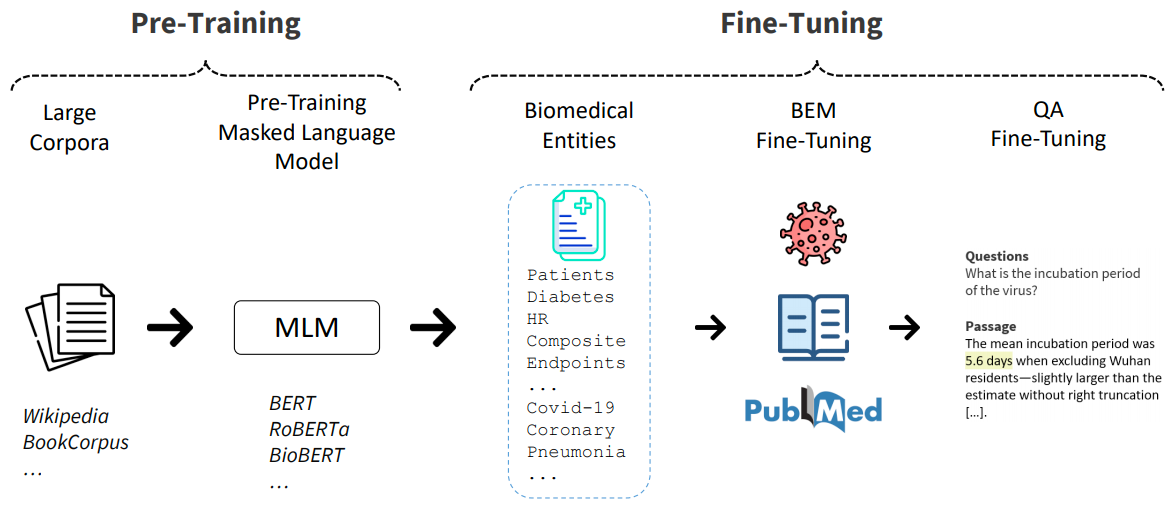
Figure 2: A schematic representation of the main steps involved in fine-tuning masked language models for the
QA task through the biomedical entity-aware masking (BEM) strategy.
BEM is an entity-aware masking strategy that only masks biomedical entities detected by a domain-specific named entity recognizer, namely SciSpacy, and rather than randomly choosing the tokens to be masked, we inform the model of the relevant tokens to pay attention to, and encourage the model to refine its representations using the new surrounding context.
We decompose the BEM strategy into two steps: (1) recognition and (2) subsampling and substitution.
During the recognition phase, a set of biomedical entities E is identified in advance over a training corpus. Then, at the sub-sampling and substitution stage, we first sample a proportion ρ of biomedical entities Et ∈ E. The resulting entity subsets Et is thus dynamically computed at batch time to introduce a diverse and flexible spectrum of masked entities during training. For consistency, we use the same tokenizer for the documents di in the batch and the entities ej ∈ E. Then, we substitute all the k entity mentions wkej in di with the special token [MASK], making sure that no consecutive entities are replaced. The substitution takes place at batch time, so that the substitution is a downstream process suitable for a wide typology of MLMs. A diagram synthesizing the involved steps is reported in Figure 2.
For more information, check out our EACL21 paper.
Publication
- G. Pergola, E. Kochkina, L. Gui, M. Liakata and Y. He. Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies, The 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), Apr. 2021.
@inproceedings{pergola21, title = "Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies", author = "Pergola, Gabriele and Kochkina, Elena and Gui, Lin and Liakata, Maria and He, Yulan", booktitle = "Proceedings of the 16th Conference of the {E}uropean Chapter of the Association for Computational Linguistics: Long Papers", month = apr, year = "2021", address = "Online", publisher = "Association for Computational Linguistics" }Biomedical question-answering (QA) has gained increased attention for its capability to provide users with high-quality information from a vast scientific literature. Although an increasing number of biomedical QA datasets has been recently made available, those resources are still rather limited and expensive to produce. Transfer learning via pre-trained language models (LMs) has been shown as a promising approach to leverage existing general-purpose knowledge. However, finetuning these large models can be costly and time consuming, often yielding limited benefits when adapting to specific themes of specialised domains, such as the COVID-19 literature. To bootstrap further their domain adaptation, we propose a simple yet unexplored approach, which we call biomedical entity-aware masking (BEM). We encourage masked language models to learn entity-centric knowledge based on the pivotal entities characterizing the domain at hand, and employ those entities to drive the LM fine-tuning. The resulting strategy is a downstream process applicable to a wide variety of masked LMs, not requiring additional memory or components in the neural architectures. Experimental results show performance on par with state-of-the-art models on several biomedical QA datasets.