ML for Systems and Systems for ML
The continued growth of available data and complexity of large-scale machine learning systems have led to a new area in the crossroads between ML/AI and systems design, where automated data-driven approaches are used for hardware design, compiler optimizations, cloud management, and more. We are developing a highly scalable, distributed key-value store capable of recasting graph solutions in terms of sparse linear algebraic operations, which paves the way for efficient graph operations.
Sample publications:
Our experts: Peter Triantafillou, Hakan Ferhatosmanoglu
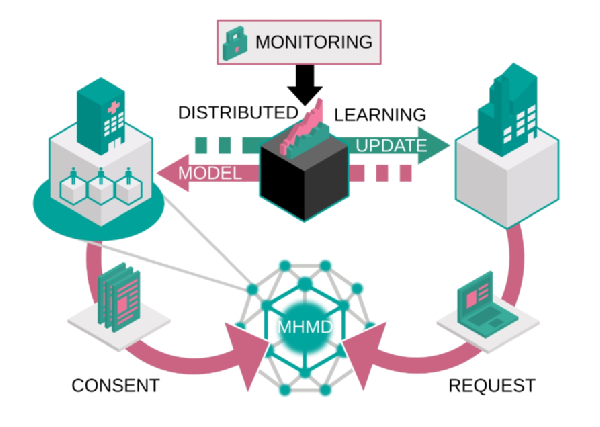
Distributed Learning
Distributed learning is an instructional model that allows instructor, students, and content to be located in different, noncentralized locations so that instruction and learning can occur independent of time and place. The distributed learning model can be used in combination with traditional...
Sample publications:
Our experts: Peter Triantafillou

Spatio Temporal Analytics
There is a variety of Spatio-temporal data available today. New methods for analyzing and modeling are necessary to identify spatial relationships and temporal patterns in such data, which can inform data management techniques and real-world decisions.
Our data-intensive approaches have a wide range of applications, including scalable and dynamic optimization of locations of bike-sharing stations, parcel lockers, and electric vehicle charging stations.
Sample publications:
Our experts: Hakan Ferhatosmanoglu, Peter Triantafillou

NLP and Text Mining
Text mining (also referred to as text analytics) is an artificial intelligence (AI) technology that uses natural language processing (NLP) to transform the free (unstructured) text in documents and databases into normalized, structured data suitable for analysis or to drive machine learning (ML) algorithms.
Our experts: Yulan He, Maria Liakata

Data Privacy
The most impactful data science often relies on analyzing data from individuals that are considered highly sensitive — medical history, location, personal interests and preferences, and opinions. In many cases, it is not feasible to gather the necessary sensitive information without providing strong guarantees of privacy to the users in question. Differential privacy is one such solution that has been adopted by several major technology organizations (including Apple, Google, and Microsoft), and the technology is used by hundreds of millions of users daily. We study different models of privacy, particularly differential privacy and its variants, and develop new techniques to allow accurate analysis while providing strong statistical guarantees of privacy.
Sample publications:
Our experts: Graham Cormode, Hakan Ferhatosmanoglu

Bio Data Science
Summary: Biology is rapidly acquiring the character of a data science. Billions of data points on genes, proteins and other molecules are compiled in large files and systematically studied. ... Biology is rapidly acquiring the character of a data science.
Sample publications:
Our experts: Paul Jenkins

Graph mining/analytics
Graph structures are ubiquitous to represent entities and relationships, with examples including social networks, road networks, resource allocation networks, and knowledge graphs [3,4]. Real-world graphs are analyzed to determine relationships and overall structural properties, while predictive models can be designed to exploit any detected patterns. We examine the incorporation of knowledge graphs into machine learning processes to create more powerful representations. To achieve efficiency goals, we develop graph and hyper-graph partitioning schemes to support distributed data stores with minimal communication operations [1,2,4].
Sample publications:
Our experts: Hakan Ferhatosmanoglu, Peter Triantafillou

Foundations of Learning
Some underlying challenges that span different data science applications include data representation. We study knowledge graphs and sequenced data for their use in various domains. For example, we recently introduced a new sequence-to-sequence cross-modal retrieval problem and solution via an encoder-decoder neural architecture [1]. We investigate properties of the representation space itself, such as geometric properties of embeddings [2]. Various indexing techniques are applied to improve efficiency when using these representations.
Sample publications:
- Vishwash Batra, Aparajita Haldar, Yulan He, Hakan Ferhatosmanoglu, George Vogiatzis, and Tanaya Guha. “Variational Recurrent Sequence-to-Sequence Retrieval for Stepwise Illustration” In European Conference on Information Retrieval (ECIR), 2020.
- Brendan Whitaker, Denis Newman-Griffis, Aparajita Haldar, Hakan Ferhatosmanoglu, and Eric Fosler-Lussier. “Characterizing the impact of geometric properties of word embeddings on task performance” In Third Workshop on Evaluating Vector Space Representations for NLP (RepEval), 2019
- Diverse Relevance Feedback for Time Series with Autoencoder Based Summarizations, IEEE Trans. on Knowledge and Data Engineering, 2018
- VISIR: Visual and Semantic Image Label Refinement, ACM WSDM (Web Search and Data Mining) 2018
- Diversity based Relevance Feedback for Time Series Search, PVLDB 2014
- λ-diverse nearest neighbors browsing for multidimensional data, IEEE TKDE 2013
Our experts: Graham Cormode, Paul Jenkins, Peter Triantafillou, Hakan Ferhatosmanoglu
