
WPCCS 2020 Schedule
The Warwick Postgraduate Colloquium in Computer Science (WPCCS) 2020 will be held on Monday, 14th December, online via Microsoft Teams. This is the final schedule. If there are any problems please get in touch with wpccs@warwick.ac.uk.
Guest Talk - Maria Liakata
Creating time sensitive sensors from language and heterogeneous user-generated content
The majority of work in Natural Language Processing on mental health prediction, even when using longitudinal social media data, involves distinguishing individuals with a condition from controls rather than assessing individuals’ mental health at different points in time. This talk will present the objectives addressed by my five-year Turing AI Fellowship which aims to establish a new area in natural language processing on personalised longitudinal language processing. Progress so far on developing sensors for capturing digital biomarkers from language and heterogeneous UGC to understand the evolution of an individual over time will also be discussed
Guest Talk - Patrick McCorry
Creating a cryptocurrency startup
I spent the years 2013-2020 focusing on academic research in the field of cryptocurrencies. It began with Bitcoin, a global and decentralized store of value, and moved onto Ethereum, a global and permissionless financial system. I finished a PhD, a few post-docs and then joined as a faculty member where I was ready to start my own research group. I decided in 2019 that it was not the right time to start a research group and instead I should create a startup, especially since there was (and still remains) numerous low-hanging fruit problems to solve. I'll talk about my rationale for leaving academia, the experience of putting together a team, and some of the lessons learnt of pursuing product-market fit. One potential customer loved the product so much that they decided to acquire it and re-lease it. So I can provide some insight on the overall process.
PhD Graduates Panel - Henry Crosby, Neha Gupta, and David Purser
Life after PhD
Three recent Warwick PhD Graduates will share their experience of the last stages of PhD and the first period in their new positions, and provide their views and advice on how to look for opportunities, make informed choices, and optimise one's use of time and resources. This panel is an opportunity to listen and ask questions to former students who have finished their thesis and have progressed in their career, but still have a clear and fresh recollection of the transition from PhD life to life after PhD.
Machine Learning [10:15-11:10]
Accelerating Federated Learning in Unreliable Systems
by Wentai Wu
Federated learning (FL) has attracted increasing attention as a promising approach to driving a vast number of devices at the edge with artificial intelligence. However, it is very challenging to guarantee the efficiency of FL considering the unreliable nature of end devices which may drop/opt out of the training progress frequently. In this presentation, the main factors that make FL inefficient will be summarized, followed by a number of state-of-the-art solutions to the problem including my latest research effort in adapting FL to unreliable Mobile Edge Computing (MEC) systems. As the last part of the talk, open challenges of research on FL and privacy-preserving ML techniques will be figured out as well.
Self-supervised Graph Learning
by Amir Shirian
A lot of researches have been focused on finding an optimally discriminative representation for the task based on the labeled annotated by humans. While, access to such annotated data is often time-consuming, expensive, and scarce due to variation across data such as speaker, language, and cultures. In particular, a large research effort has been done towards learning from unlabeled data. Within this effort, the field of self-supervised learning (SSL) has recently demonstrated the most promising result and in some cases surpassed the supervised learning. In this work, we propose a self-supervised learning method by introducing three different self-supervised learning strategies on the graph domain and show their performances in different benchmarks.
A Review of End-to-End Deep Learning-based Methods for Multiple Object Tracking
by Funmi Kesa
Tracking is an extension of object detection where a unique identifier is assigned to an object across frames in a video sequence. Traditional multiple object tracking methods use the tracking-by-detection paradigm where measurements from a trained object detector are linked in order to estimate object trajectories across frames. While this approach allows the use of the best object detector for the task, its inability to share image features with the data association task is a limiting factor. Besides, the computation costs for this technique is high due to the separate training of the detection and association components. With the advent of deep learning, recent methods explore other paradigms such as end-to-end learning that allow information sharing between the components of the tracker. Thus, reducing computation cost while maintaining state-of-the-art performance. This paper presents a review of end-to-end deep-learning-based methods for multiple object tracking and provides recommendations for future research.
Attention Selective Network for Face Synthesis and Pose-invariant Face Recognition
by Jiashu Liao
Face recognition algorithms have improved significantly in recent years since the introduction of deep learning and the availability of large training datasets. However, their performance is still inadequate when the face pose varies as pose variation can dramatically increase intra-person variability. This work proposes a novel generative adversarial architecture called the Attention Selective Network (ASN) to address the problem of pose-invariant face recognition. The ASN introduces an efficient attention mechanism that switches information flow between image pathway and poses pathway and a multi-part loss function to generate realistic-looking frontal face images from other face poses that can be used for recognizing faces under various poses. Thanks to the high quality of the synthesized images, the ASN achieves superior performance in terms of recognition rates (15-20% based on the different viewpoints) compared to the state-of-the-art supervised methods.
Anticipating Pedestrian Movements for Safer Self-driving Vehicles
by Olly Styles
 Reliable anticipation of pedestrian movements is imperative for autonomous vehicles' operation. While significant progress has been made in detecting pedestrians, predicting their trajectory remains a challenging problem due to pedestrians' unpredictable nature and lack of training data. We address this lack of data by introducing a scalable machine annotation framework that enables trajectory forecasting models to be trained using a large dataset without human labeling. Our automated annotation framework turns large unlabeled datasets into useful data for training trajectory forecasting models.
Reliable anticipation of pedestrian movements is imperative for autonomous vehicles' operation. While significant progress has been made in detecting pedestrians, predicting their trajectory remains a challenging problem due to pedestrians' unpredictable nature and lack of training data. We address this lack of data by introducing a scalable machine annotation framework that enables trajectory forecasting models to be trained using a large dataset without human labeling. Our automated annotation framework turns large unlabeled datasets into useful data for training trajectory forecasting models.
Advanced Piano Roll Dataset for Automatic Music Transcription
by Tom Wood
Automatic Music Transcription is the process of automatically converting a recording of a piece of music in to some form of musical representation such as a score. Musical recordings from a live performance are recorded in real time (seconds), but music on a score is notated in musical time (beats). As part of the transcription process, we want to be able to convert real time into musical time. We propose a new musical representation, the Advanced Piano roll, which is capable of capturing both musical and real time. We are developing a new dataset using an interactive note-matching tool. The dataset combines recorded performances from the Maestro dataset with a musical ground truth in our Advanced Piano Roll format.
High Performance Computing [10:15-11:20]
Uncertainty Quantification of Atmospheric Dispersion Models
by Alex Cooper
Computer simulations are becoming a vital tool for modelling and understanding disasters that occur in the real world. Emergency responders leverage these simulations to enhance their understanding of disasters with the eventual aim to run simulations in real time as the disasters are unfolding. One type of disaster simulation that warrants research is the release of particles of an unknown substance into the atmosphere. One key area of research is for simulations to leverage HPC tools and resources to quantify the uncertainty inherent within the atmospheric dispersion simulations. By combining an ensemble of atmospheric models, HPC frameworks such as Dakota and ML frameworks such as TensorFlow and Scikit-Learn, the research aims to show how to compute and communicate a probabilistic understanding of disasters within time constrained scenarios given the inherent uncertainties regarding the source terms parameters, meteorological data and model parameterisations.
StressBench: Configurable Full System Network and I/O Benchmark
by Dean Chester
Network benchmarks typically test network operations in isolation which makes it difficult to ascertain how a network architecture can perform when utilization is high. In this paper we present StressBench, a network benchmark tool written for testing MPI operations concurrently. To induce artificial network congestion from real parallel scientific application communication patterns. We demonstrate the versatility of the benchmark from microbenchmarks through to finely controlled congested runs across a cluster. We have rebuilt two proxy applications in an attempt to validate communication patterns being representative and the same as an application with the maximum difference being 20%.
Towards Automated Kernel Fusion for the Optimisation of Scientific Applications
by Andrew Lamzed-Short
Large-scale scientific applications are built in a modular fashion to facilitate development with a large team and to breakdown complex algorithms into smaller, reusable "kernel" functions. Typically, these consist of a few loops governing their logic. Modularity comes at the cost of degraded runtime performance due to the associated cost of making function calls, This leads to poor cache residency and spatial locality of data, requiring additional memory transfers. In this talk, we present a novel LLVM transformation pass that automatically performs kernel fusion. Combined with a minimal extension to the clang++ compiler with a new function attribute, this method achieves up to 4x speedup relative to unfused versions of the programs, and exact performance parity with manually fused versions. Our approach is facilitated by a new loop fusion algorithm capable of interprocedurally fusing both skewed and unskewed loops in different kernels.
Efficient Computational Offloading of Independency Tasks in an Untrusted Environment of Mobile Edge Computing
by Ali Meree
Computation offloading for Independent tasks during user mobility is still a challenging issue in the untrusted edge network environment. The mobility users in the untrusted edge nodes will impact the execution of tasks in the situation where the user makes a selection of the trusted/ malicious nodes being in the process of offloading mechanism. In addition, the dynamic workload distribution within untrusted edge nodes, which varies with time, is due to delay during the mobility of users, and different Mobile Edge Network (MEN) are connected to different MENs and mobile users with different delay times. The users will move from edge node to another node during the task execution in the edge and the task result roam with various nodes and will come back to the user in the closet edge node and there are some malicious edge nodes which can impact the process of roaming within nodes. However, current works have not considered the user mobility as assigning tasks to untrusted edge nodes and get results either from the same node or other nodes that are close to the user during the moving. We focus on minimizing execution delays in tasks offloading in an untrusted environment. As these delays in malicious nodes contribute to the delay in overall task execution as well as decision-making in offloading a task from mobile devices. Our work will present a novel approach of task offloading on an untrusted edge node to minimize the delay during user mobility.
Coupling Together proxy HPC codes using a coupling framework
by Archie Powell
As we progress further and further towards Exascale, the ability to efficiently run large scale codes becomes increasingly difficult due to load imbalance and poor use of hardware. A fundamental issue that causes load imbalance is the monolithic nature of applications when running across many-node clusters. As a result, an approach of coupling together instances of a code as part of a large simulation is growing in popularity. Trying to convert an existing code to a coupled version is difficult however, as these codebases can be millions of lines long. Furthermore, correctly allocating the right amount of resources to both the coupling framework and code instances presents an additional challenge. Thus, creating a proxy-coupler, coupling proxy-apps is a method to solve these issues. This research introduces CPX, a mini-coupler framework for an unstructured CFD mini-app, which aims to replicate the performance profile of a real world coupled CFD code.
High-Level FPGA Accelerator Design for Structured-Mesh-Based Explicit Numerical Solvers
by Kamalavasan Kamalakkannan
This work presents a workflow for synthesizing near-optimal FPGA implementations for structured-mesh based stencil applications. It leverages key characteristics of the application class, its computation-communication pattern, and the architectural capabilities of the FPGA to accelerate solvers from the high-performance computing domain. Key new features of the workflow are (1) the unification of standard state-of-the-art techniques with few high-gain optimizations (2) the development and use of a predictive analytic model for exploring the design space, resource estimates and performance. Three representative applications are implemented using the design workflow on a Xilinx Alveo U280 FPGA, demonstrating near-optimal performance and over 85% predictive model accuracy. Implementation comparison with Nvidia V100 GPU shows competitive performance while consuming 50% lower energy for the non-trivial application. Our investigation shows the considerable challenges in gaining high performance on current generation FPGAs and We discuss determinants for a given stencil code to be amenable to FPGA implementation.
Communication Avoidance in Unstructured-mesh CFD Applications
by Suneth Ekanayake
Due to the end of frequency scaling around the middle of the last decade, as a result of the unsustainable increase in energy consumption, processor architectures have moved towards massively parallel designs. In these massively parallel architectures, data movement is the dominant cost in energy consumption and runtime of the applications. Therefore, it is essential to minimise communication to gain the maximum use of these increasing levels of parallelism. Cache-blocking tiling is one of the key techniques that enables us to exploit data locality especially in modern CPU architectures which have large cache hierarchies. In this research, we are investigating the capabilities of SLOPE, a cache-blocking tiling library for unstructured mesh calculations intending to integrate it into the OP2 DSL, an open-source framework for the execution of unstructured grid applications. So that, OP2 DSL can automatically generate code to obtain optimized parallelizations with cache-blocking tiling into multi-threaded CPU applications.
Loose-Coupling of Proxy-Applications in the Cloud
by Kabir Choudry
Computer Security and Databases [10:15-11:10]
OPay: An Orientation-based Payment Solution Against Passive Relay Attack in Contactless Payment
by Mahshid Mehr Nezhad
Passive Relay Attack (PRA) in contactless payment is when an attacker uses their mobile Point-of-Sale (PoS) terminal to steal money from the victim’s payment device without their knowledge and makes a transaction by just placing the card reader close to the payment device area. This can be done without any expertise, especially in crowded places. The rising number of contactless payments (half of all debit card payments, reported by UK Finance in 2020) increases the risk of this attack as well. Existing solutions either have security/privacy or usability concerns. In this research, we try to prevent this attack by detecting the orientation of the devices by fusing accelerometer and gyroscope sensor data. The transaction is only authorized if both devices are aligned with each other. This is still a work in progress and the evaluations will be done in the future.
CallerAuth : End-to-end solution for caller ID spoofing attack
by Shin Wang
Calling Line Identity spoofing is when the caller intentionally presents a false number to hide his true identity. The technique of displaying a false caller ID protects the privacy of the caller but is always abused to deceive the callee in the scene of fraudulence. In 2019, 33% of the scam calls are answered because of their familiar caller ID. These calls are displayed as a local phone number (Neighbour spoofing) or a legitimate business's outbound calling number (Enterprise Spoofing). Over 30% of these answered scam calls are succeed. Unfortunately, neither legislation nor existing anti-scam call applications could tackle the issue. In the project, we propose a novel anti-spoofing protocol called CallerAuth. The technique combines the heuristics (add-value calling services) and the cryptography (secret exchange) techniques in providing an end-to-end solution for caller ID spoofing attack, without changing the current design of the telecommunication network.
The study of VM allocation behaviour toward obtaining a secure virtual machine allocation in cloud computing
by Mansour Aldawood
The virtualization in cloud computing systems enables the virtual machines (VMs) hosted within the same physical machine (PM) to share computing resources. The VMs allocations is a vital process toward optimizing the cloud resources, where the VMs allocated to specific PMs for computing. The desired optimal allocation motivated by various requirements such as efficient use of resources, power saving, load balancing, or for security requirements. This research focuses on security perceptive of VMs allocation in cloud systems. Former studies demonstrate that a VM that categorized as malicious VM could potentially compromise other VMs, by share the same PM with them, which result in less secure allocation. Thus, the VM allocation algorithm should reduce the possibility of obtaining malicious allocations during the allocation process. This research study different types of allocation algorithms behaviour such as, stacking algorithms, spreading algorithms or random algorithms to obtain the most secure VMs allocation behaviour.
PPQ-Trajectory: Spatio-temporal Quantization for Querying in Large Trajectory Repositories
by Shuang Wang
We present PPQ-trajectory, a spatio-temporal quantization based solution for querying large dynamic trajectory data. PPQ-trajectory includes a partition-wise predictive quantizer (PPQ) that generates an error-bounded codebook with autocorrelation and spatial proximity-based partitions. The codebook is indexed to run approximate and exact spatio-temporal queries over compressed trajectories. PPQ-trajectory includes a coordinate quad tree coding for the codebook with support for exact queries. An incremental temporalpartition-based index is utilised to avoid full reconstruction of tra-jectories during queries. An extensive set of experimental resultsfor spatio-temporal queries on real trajectory datasets is presented.PPQ-trajectory shows significant improvements over the alterna-tives with respect to several performance measures, including theaccuracy of results when the summary is used directly to provideapproximate query results, the spatial deviation with which spatio-temporal path queries can be answered when the summary is usedas an index, and the time taken to construct the summary. Superiorresults on the quality of the summary and the compression ratioare also demonstrated.
Random Join Sampling with Graphical Models
by Ali Mohammadi Shanghooshabad
Modern databases face formidable challenges when called to join (several) big tables. Said joins are very time- and resource-consuming, join results are too big to keep in memory, and performing analytics/learning tasks over them costs dearly in terms of time, resources, and money (in the cloud). Moreover, although random sampling is a promising idea to mitigate the above problems, the current state of the art method leaves lots of room for improvements and the general solution besides inefficient is also complex and difficult to follow. We will introduce a principled solution, coined PGMJoins. PGMJoins adapts Probabilistic Graphical Models to deriving random samples for (n-way) key-joins, many-to-many joins, and cyclic and acyclic joins.
Extending The Mixing Theorem of Isolation Levels Using the Client-Centric Isolation Framework
by Abdullah Al Hajri
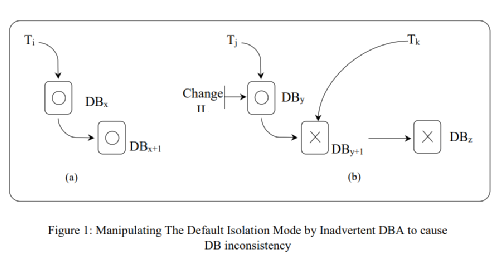 The research problem discusses the different formalisms of concurrency control modes. It, then, uses one of these modes (or isolation levels) to extend the Mixing Theorem that addresses the status of transactions, which use different modes when accessing concurrently the same data item. The study aims to analyse the test results of simulating such a system (mixed) and point out possible inconsistency on DB states. It shows that by addressing the anomaly that occur when some concurrent transactions accessing the same data item with different isolation levels and end up violating an application-specific invariant. Another issue that this study aims to address is the issue that occurs when application programmer who tend to use the default mode (isolation level) and an inadvertent DB admin changes it without acknowledging them, which consequently leads to violating DB consistency (modifying transactions) and retrieving incorrect results to queries (read only transactions).
The research problem discusses the different formalisms of concurrency control modes. It, then, uses one of these modes (or isolation levels) to extend the Mixing Theorem that addresses the status of transactions, which use different modes when accessing concurrently the same data item. The study aims to analyse the test results of simulating such a system (mixed) and point out possible inconsistency on DB states. It shows that by addressing the anomaly that occur when some concurrent transactions accessing the same data item with different isolation levels and end up violating an application-specific invariant. Another issue that this study aims to address is the issue that occurs when application programmer who tend to use the default mode (isolation level) and an inadvertent DB admin changes it without acknowledging them, which consequently leads to violating DB consistency (modifying transactions) and retrieving incorrect results to queries (read only transactions).
Urban Science [10:15-11:10]
Hierarchical Analysis of Urban Networks
by Choudhry Shuaib
Many complex systems can be represented by graphs. Trophic coherence, a measure of a network’s hierarchical organisation, has been shown to be linked to a network’s structural and dynamical aspects such as cyclicity, stability and normality; trophic levels of nodes can reveal their functional properties and rank the nodes accordingly. But trophic levels and hence trophic coherence can only be defined on directed networks with well-defined sources, known as basal nodes. Thus, trophic analysis of networks had been restricted until now. In this presentation I introduce hierarchical levels, which is a generalisation of trophic levels, that can be defined on any simple graph and I will show interpretations of these novel network and node metrics applied to urban networks.
Variational Bayesian Approach for Modelling Spatial Interactions
by Shanaka Perera
Growth in e-commerce has challenged the existence of high-street retail businesses, and the choice of the store location is prominent than ever before. Following the long-standing gravity model principals, we introduce a novel Spatial Interaction model to estimate the potential demand at retail stores. Standard practice has been limited to Huff-type models and applications constrained on aggregated level smaller datasets. First, we represent the probability of consumers choosing the stores through Gaussian densities. Second, we use the Bayesian approach in estimating the parameters in which the posterior is intractable and poses significant computational challenges. We overcome this by adopting Variational Inference often scale better than the MCMC technique. We introduce a comprehensive spatial retail store dataset of the UK and demonstrate our approach with two case studies.
Re-imagining Architectural Design: from Fragmentation to the Creation of Ambient Spaces
by Ivana Tosheva
Architecture is an integral part of our lives which underlies nearly everything we do - it profoundly affects our feelings, the ways in which we think and act as well as our health. As people spend more than 90% of their time indoors, understanding our built environment in relation to human perception is crucial. However, partially due to its intangibility and subjectiveness, designing for spatial experiences within contemporary design practices tends to be diminished in favour of the rigid prioritisation of function. Consequently, the research aims to challenge the current state of architectural design practices by exploring the relationship between ambiance perceptions and design choices. By fragmenting interior spaces into quantifiable, fundamental components and measuring them against quantitative and qualitative evaluations of ambiance, the project will propose a new design method which will allow for the systematic creation of ambient spaces.
From Limitations to Qualities in Critical Urban Data Visualisation
by Nicole Hengesbach
Data have limitations and considering these limitations is particularly relevant for urban data visualisations which are often interacted with by lay people who are not necessarily familiar with the underlying data. One way to consider limitations of a specific data set or visualisation is to think about them as the difference between our expectations and what is actually represented with the data. For instance, we like to think of data as complete, accurate or consistent when in reality data may be incomplete, relative and contextual. I explore how principles from critical data studies can be translated into data qualities. These qualities go beyond the common technical ones — uncertainty is perhaps the most common currently considered in visualisation — and enable description of the wider relationship between reality and data. This conceptualisation is part of developing a method to account for data limitations in visualisation design with the objective to enhance interpretation.
Exploring Relation Between Supermarket Distance and Childhood Obesity in England
by Elisabeth Titis
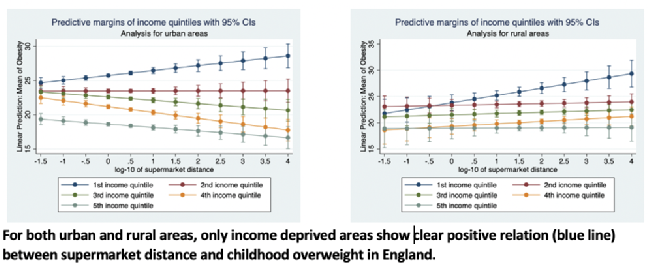
Physical access to food can affect diet quality and thus obesity rates. Here we examined relation between supermarket distance (road distance from postcode centroid to nearest outlet) and childhood overweight (incl. obesity) in England, modelling both main effects of income, density and urbanicity, and their interactions with distance using OLS. First, we analysed the relation for England as a whole, followed by comparison between rural and urban areas. Next, we converted income into categories based on quintiles by urbanicity, e.g. non-first income quintile for urban areas. Density remains important predictor for England and for urban areas but not for rural areas for which income is the only significant predictor; similarly, interaction effects are significant for England and urban areas only. Analysis with income quintiles showed that income deprived urban areas exhibit stronger positive trend than similar rural areas, meaning children in these areas tend to be more obese. Only affluent urban areas showed a clear negative trend. Our data provides a better understanding of food access disparities in obesity prevalence.
Collective Shortest Paths for Minimising Congestion on Road Networks
by Chris Conlan
Congestion is a major source of air pollution in cities, restricts economic activity and is damaging to the wellbeing of citizens who use, or reside close to, heavily congested roads. We know that road networks can be used more efficiently, and it has been shown that "altruistic" routing of vehicles, as opposed to "selfish" routing is better for everyone. Here we present a practical algorithm, CS-MAT, for collectively routing vehicles in a road network that reduces overall travel times, increases network utilization and can be parallelized for efficient implementation. The algorithm is based on smart underlying data structures which enable us to track expected future load with respect to time along each edge within the network. We adapt classic algorithms such as Dijkstra, and design an algorithm that always seeks to route the path from a query workload which has the lowest arrival time at its destination node.
Machine Learning [11:20-12:15]
Human Emotion Distribution Learning from Face Images using CNN and LBC Features
by Abeer Almowallad
Human emotion recognition from facial expressions depicted in images is an active area of research particularly for medical, security and human-computer interaction applications. Since there is no pure emotion, measuring the intensity of several possible emotions depicted in a facial expression image is a challenging task. Previous studies have dealt with this challenge by using label-distribution learning (LDL) and focusing on optimizing a conditional probability function that attempts to reduce the relative entropy of the predicted distribution with respect to the target distribution, which leads to a lack of generality of the model. In this work, we propose a deep learning framework for LDL that uses convolutional neural network (CNN) features to increase the generalization of the trained model. Our framework, which we call EDL-LBCNN, enhances the features extracted by CNNs by incorporating a local binary convolutional (LBC) layer to acquire texture information from the face images. We evaluate our EDL-LBCNN framework on the s-JAFFE dataset. Our experimental results show that the EDLLBCNN framework can effectively deal with LDL for human emotion recognition and attain a stronger performance than that of state-of-the-art methods.
CHIME: Cross-passage Hierarchical Memory Network for Generative Review Question Answering
by Junru Lu
We introduce CHIME, a cross-passage hierarchical memory network for question answering (QA) via text generation. It extends XLNet by introducing an auxiliary memory module consisting of two components: the context memory collecting cross-passage evidence, and the answer memory working as a buffer continually refining the generated answers. Empirically, we show the efficacy of the proposed architecture in the multi-passage generative QA, outperforming the state-of-the-art baselines with better syntactically well-formed answers and increased precision in addressing the questions of the AmazonQA review dataset.
CD^2CR: Co-reference resolution across documents and domains
by James Ravenscroft
 Cross-document co-reference resolution (CDCR) is the task of identifying and linking mentions to entities and concepts across many text documents. Current state-of-the-art CDCR models assume that all documents are of the same type (e.g. news articles) or fall under the same theme. However, it is also desirable to perform CDCR across different domains (type or theme). We propose a new task and dataset for cross-document cross-domain co-reference resolution CD^2CR aiming to identify links between entities across heterogeneous document types. In this work we focus on the resolution of entities mentioned across scientific work and newspaper articles that discuss. This process could allow scientists to understand how their work is being represented in mainstream media. We show that existing CDCR models do not perform well in this new setting through a series of experiments and provide our dataset, annotation tool, guidelines and model as open resources.
Cross-document co-reference resolution (CDCR) is the task of identifying and linking mentions to entities and concepts across many text documents. Current state-of-the-art CDCR models assume that all documents are of the same type (e.g. news articles) or fall under the same theme. However, it is also desirable to perform CDCR across different domains (type or theme). We propose a new task and dataset for cross-document cross-domain co-reference resolution CD^2CR aiming to identify links between entities across heterogeneous document types. In this work we focus on the resolution of entities mentioned across scientific work and newspaper articles that discuss. This process could allow scientists to understand how their work is being represented in mainstream media. We show that existing CDCR models do not perform well in this new setting through a series of experiments and provide our dataset, annotation tool, guidelines and model as open resources.
SXL: Spatially explicit learning of geographic processes with auxiliary tasks
by Konstantin Klemmer
From earth system sciences to climate modeling and ecology, many of the greatest empirical modeling challenges are geographic in nature. As these processes are characterized by spatial dynamics, we can exploit their autoregressive nature to inform learning algorithms. We introduce SXL, a method for learning with geospatial data using explicitly spatial auxiliary tasks. We embed the local Moran's I, a well-established measure of local spatial autocorrelation, into the training process, "nudging" the model to learn the direction and magnitude of local autoregressive effects in parallel with the primary task. Further, we propose an expansion of Moran's I to multiple resolutions to capture effects at different spatial granularities and over varying distance scales. We show the superiority of this method for training deep neural networks using experiments with real-world geospatial data in both generative and predictive modeling tasks. Our approach can be used with arbitrary network architectures and, in our experiments, consistently improves their performance. We also outperform appropriate, domain-specific interpolation benchmarks. Our work highlights how integrating the geographic information sciences and spatial statistics into machine learning models can address the specific challenges of spatial data.
Synthesis of High-Resolution Colorectal Cancer Histology Images
by Srijay Deshpande
The development of automated tools for the tasks useful for cancer diagnosis and treatment requires large amounts of image data. Hand annotation of a large number of huge images in the domain of digital pathology by expert pathologists is a highly laborious task. I will be presenting a computationally efficient framework that we developed based on conditional generative adversarial networks to construct large annotated synthetic tissue images. Specifically, I will explain how it generates high-resolution realistic colorectal tissue images from ground truth annotations while preserving morphological features. Such synthetic images can be used for training and evaluation of deep learning algorithms in the domain of computational histopathology. Additionally, our work can be potentially useful to significantly reduce the burden of pathologists for the collection of whole slide images of stained tissue slides. Our research paper on this method was published in the SASHIMI workshop (part of the MICCAI 2020 conference).
Concept-Specific Topic Modeling Using Simple Queries
by Zheng Fang
Topic modeling is an unsupervised method for revealing the hidden semantic structure of a corpus. However, often the requirement is to find topics describing a specific aspect of the corpus. One solution is to combine domain- specific knowledge into the topic model, but this requires experts to define it. We propose a novel, query-driven topic model that avoids this. A query is used to tell the model which concept is of interest and the model then infers relevant topics. Experimental results demonstrate the effectiveness of our model.
Data Science and Computer Networks [11:20-12:15]
Computational grounded theory to understand teachers’ experiences in the gig economy
by Lama Alqazlan
Crowdworking platforms are a marketplace where physical and digital services are performed by thousands of workers (‘the crowd’). It provides workers with benefits such as job flexibility and autonomy; however, problems may be experienced due to the fragmentation of work tasks, the precarious nature of the gig economy, and it being an unreliable source of income. Our aim is to study crowdworking teachers’ experiences in this casualised labour market as there is a little understanding of their experiences compared to those who work on other platforms such as Uber. A computational grounded theory methodology will be used to analyse data retrieved from crowdworking teachers’ discussions on the popular social media website, Reddit. This approach will combine the ability of topic modeling to scale large quantities of unstructured data with grounded theory, the latter of which will capture abstract high dimensional constructs in a language that provides a deeper understanding and explanation of texts. Different frameworks will be tested to comprehend which method is more suitable to answer the research questions.
Evaluation of Thematic Coherence in Microblogs
by Iman Bilal
Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including ones for topic model coherence and text generation metrics (TGMs). Our results show that TGMs greatly outperform topic coherence metrics and are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters being less sensitive to the effect of time windows.
KAT: Knowledge-Aware Transformer for Dialogue Emotion Detection
by Lixing Zhu
We introduce CHIME, a cross-passage hierarchical memory network for question answering (QA) via text generation. It extends XLNet by introducing an auxiliary memory module consisting of two components: the context memory collecting cross-passage evidence, and the answer memory working as a buffer continually refining the generated answers. Empirically, we show the efficacy of the proposed architecture in the multi-passage generative QA, outperforming the state-of-the-art baselines with better syntactically well-formed answers and increased precision in addressing the questions of the AmazonQA review dataset.
Privacy-Preserving Synthetic Location Data in the Real World
by Teddy Cunningham
Sharing sensitive data is vital in enabling many modern data analysis and machine learning tasks. However, current methods for data release are insufficiently accurate or granular to provide meaningful utility, and carry a high risk of deanonymization or membership inference attacks. This talk will introduce two differentially private synthetic data generation solutions with a focus on the compelling domain of location data. Both methods have high practical utility for generating synthetic location data from real locations, which both protect the existence and true location of each individual in the original dataset. Experiments using three large-scale location datasets show that the proposed solutions generate synthetic location data with high utility and strong similarity to the real datasets. Some practical applications can be highlighted by applying our synthetic data to a range of location analytics queries, and this talk will show our synthetic data produces near-identical answers to the same queries compared to when real data is used.
A Distributed Mobility-aware Computational Offloading Algorithm in Edge Computing
by Mohammed Mufareh A Maray
 Mobile edge computing (MEC) is an emergent technology that helps bridge the gap between resource-constrained IoT devices (IoTD) and the ever-increasing computational demands of the mobile applications they host. MEC enables the IoTDs to offload computationally expensive tasks to the nearby edge nodes for better quality of services such as latency. Several of the recently proposed offloading techniques focus on centralised approaches with a small number of mostly static IoTDs hosting independent tasks. To address this limitation, in this paper, we develop a fully distributed greedy offloading strategy for dependent tasks hosted on a large number of mobile devices, with the aim of reducing completion latency. We run extensive simulations using NS-3. Our results show that average completion time decreases with increasing speeds, due to the larger range of MECs available due to mobility. Surprisingly, we also found that the buffer size, i.e., the total execution time of all waiting tasks in a buffer, does not change with speed.
Mobile edge computing (MEC) is an emergent technology that helps bridge the gap between resource-constrained IoT devices (IoTD) and the ever-increasing computational demands of the mobile applications they host. MEC enables the IoTDs to offload computationally expensive tasks to the nearby edge nodes for better quality of services such as latency. Several of the recently proposed offloading techniques focus on centralised approaches with a small number of mostly static IoTDs hosting independent tasks. To address this limitation, in this paper, we develop a fully distributed greedy offloading strategy for dependent tasks hosted on a large number of mobile devices, with the aim of reducing completion latency. We run extensive simulations using NS-3. Our results show that average completion time decreases with increasing speeds, due to the larger range of MECs available due to mobility. Surprisingly, we also found that the buffer size, i.e., the total execution time of all waiting tasks in a buffer, does not change with speed.
Monitoring Challenges in Wireless Sensor Networks
by Jawaher Alharbi
There has been a consistent growth in the usage of wireless sensor networks in monitoring and tracking applications. This is because of the uncomplicated network design and the importance of its industrial and medical applications. Nevertheless, there are many challenges in wireless sensor networks deployment that are due to the resource constraints of the sensor nodes. One way of mitigating those challenges is to ensure that trust exist between the nodes. In the distributed system where nodes have no resource constraints, continuous node monitoring can be used to enforce trust between nodes. This often cannot be done in a wireless sensor network. For example, to preserve energy, a technique called duty cycling is used that puts nodes to sleep. However, monitoring cannot be performed during those times. Our initial work will investigate the impact of duty cycling on node monitoring and trust evaluation. We will study state of the art of duty cycling techniques such as low power listening (LPL) and trust model such as beta reputation model. We will implement these algorithms and perform large scale simulations to understand the impact.
Theory, Foundations, and Artificial Intelligence [11:20-12:15]
Distributed Routing Using Local and Global Communication
by Sam Coy
Hybrid networks are a relatively recent model in distributed computing. In this model, we consider nodes of a graph as computers, which communicate with each other in synchronous rounds. Local communication (where nodes share an edge) is unlimited, but global communication is heavily restricted. We consider this model in the setting of networks which are laid out in the plane: each node has a location in the plane and nodes are connected by an edge if they are within a certain distance of each other. This setting is analogous to a mobile phone network, or a sensor network. A natural problem is to find a constant-factor approximation of a shortest path between two nodes in the network using minimal communication between nodes. We will look at the history, motivation, and benefits of this interesting new model of distributed computing, and discuss current work and progress in the setting of finding shortest.
Quantum proofs of proximity
by Marcel De Sena Dall'Agnol
With the prevalence of massive datasets and small computing devices, offloading computation becomes increasingly important. One may model this problem as follows: a weak device (the “verifier”) holds an input string and communicates with an all-powerful computer (the “prover”) so as to verify the validity of this string. Since the verifier cannot perform the verification on its own, the prover provides a digest of the computational task, allowing the verifier to check that it was performed correctly. In an extreme setting, the verifier cannot even read all of its input, and must decide whether it is valid or far from any valid string; in this case, the digest is called a proof of proximity. We formalise quantum proofs of proximity, where prover and verifier are quantum computers, and begin to chart the complexity landscape of the quantum/classical as well as the interactive/non-interactive variants of these proof systems. This is joint work with Tom Gur and Subhayan Roy Moulik.
Extending the Shuffle Model of Differential Privacy to Vectors
by Mary Scott
In this talk an optimal single message protocol is introduced for the summation of vectors in the Shuffle Model, a recent alternative model of Differential Privacy. The traditional models are the Centralised Model, which prioritises the accuracy of the data over its secrecy, and the Local Model, where an improvement in trust is counteracted by a much higher noise requirement. The Shuffle Model was developed to provide a good balance between these two opposing models by adding a shuffling step, which unbinds the users from their data whilst maintaining a moderate noise requirement. It is possible to improve this bound by implementing a Discrete Fourier Transform, which minimises the initial error at the expense of the loss in accuracy caused by the transformation. The summation of vectors has many practical applications in Federated Learning, for example training a Deep Neural Network to predict the next word that a user types.
A Symmetric Attractor-Decomposition Lifting Algorithm for Parity Games
by Thejaswini Raghavan
Progress-measure lifting algorithms for solving parity games have the best worst-case asymptotic runtime, but are limited by their asymmetric nature, and known from the work of Czerwinski et al. (2018) to be subject to a matching quasi-polynomial lower bound inherited from the combinatorics of universal trees. Parys (2019) has developed an ingenious quasi-polynomial McNaughton-Zielonka-style algorithm, and Lehtinen et al. (2019) have improved its worst-case runtime. Jurdzinski and Morvan (2020) have recently brought forward a meta attractor-based algorithm, formalizing a second class of quasi-polynomial solutions to solving parity games, which have runtime quadratic in the size of universal trees. First, we adapt the framework of iterative lifting algorithms to computing attractor-based strategies. Second, we design a symmetric lifting algorithm in this setting, in which two lifting iterations, one for each player, accelerate each other in a recursive fashion. The symmetric algorithm performs at least as well as progress-measure liftings in the worst-case, whilst bypassing their inherent asymmetric limitation. We provide a novel interpretation of McNaughton-Zielonka-style algorithms as progress-measure lifting iterations (with deliberate set-backs), further strengthening the ties between many known quasi-polynomial algorithms to date.
An Algorithmic Analysis of Majority Illusion in Social Networks
by Grzegorz Lisowski
Majority illusion occurs in a social network when the majority of agents belongs to a certain type but the majority of their neighbours belongs to a different type, therefore creating the wrong perception, i.e., the illusion, that the majority type is different from the actual one. In this paper we look at the computational aspects of majority illusion: i.e., how difficult it is to compute it and, crucially, to eliminate it. We also consider a relaxation of this problem, which we call weak majority illusion, where only the majority of agents is under illusion. For both of these we study the complexity of checking whether a given unlabelled social network admits a labelling which is a (weak) plurality illusion. We also study the possibility of creating (the least amount of) new links between the agents to eliminate the illusion, and the complexity thereof.
Knowledge-enhanced search graphs and second-order embeddings
by Aparajita Haldar
For information retrieval and AI applications, the relationships between data entities must be encoded in some meaningful way. Proximity graphs are often used to make semantically-grounded, explainable comparisons via links between these entities. For example, k-nearest neighbour graphs between word representations can be used to link similar words. While such proximity graphs are obtained from embeddings trained on text corpuses, more precise information is available in the form of human-curated knowledge graphs. Such world knowledge can incorporate common-sense reasoning about entities and their relationships. We leverage this information to generate novel "knowledge-enhanced proximity graphs" for use as search graphs, and subsequently use node2vec to produce "knowledge-enhanced second-order embeddings" for ML/NLP applications. The new search graphs outperform a state-of-the-art graph-based approximate nearest neighbour search structure, and the second-order embeddings show improved results on a variety of intrinsic evaluations compared to the original embedding.
Computer Vision, Computational Biology, and Research Practice [11:20-12:15]
Improving Difficulty-Aware Super-Resolution Using Spatial Variation
by Lichuan Xiang
Super-resolution is a process that upscaling and improve visual quality of low-resolution images. The success of deep neural networks in the task of supervised single-image super-resolution (SR) has led to a wide range of architectures with various sizes and capacities. With the recent insight that some images are inherently harder to upscale than others, in this paper we further investigate how existing SR models handle images with different levels of upscaling difficulty. In particular, we observe lightweight SR models, which have to be notably small to perform in real-time on resource-constrained devices, often fail to offer image fidelity comparable to full-size SR networks. To assist those lightweight models, we propose a novel loss function that exploits the spatial variation difference between the upscaled and ground truth images when training the networks, leading to clear improvements in SR performance, especially for those hard-to-upscale images. By applying our model-agnostic method across various existing lightweight SR models, we achieve gains around 0.3 PSNR in DIV2K validation set without any additional cost during inference.
Adapting Nuclei Instance Segmentation Method for New Domain Using Domain Intrinsic Knowledge
by Dang Vu
Convolutional neural networks are effective tools for medical image processing and analysis. However, these approaches often rely heavily on the availability of large amount manually annotated data which is particularly costly in nuclei instance segmentation task. Identification of nuclei instances in multiple imaging modalities is the first step toward further analyses. Therefore, an effective way to adopt a CNN trained on one domain to another will potentially speed up the research effort. Herein, we propose a framework that utilizes hints of nuclei existence within the images of target domain as guidance signals to retrain CNNs for that new domain. For evaluation, we selected a CNN pretrained on Haematoxylin and Eosin stained images as source domain and adapted it for Haematoxylin and Ki67 stained images. We evaluated the pretrained and retrained models on 2 2000x2000 Haematoxylin and Ki67 stained images and respectively obtained F1 scores of 0.2651 and 0.6990 for detecting nuclei.
Graph-Based Transforms based on Prediction Inaccuracy Modeling for Pathology Image Coding
by Debaleena Roy
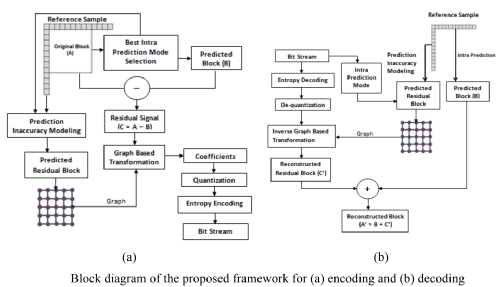
Digital pathology images are multi giga-pixel colour images that usually require large amounts of bandwidth to be transmitted and stored. Lossy compression using intra-prediction offers an attractive solution to reduce the storage and transmission requirements of these images. In this paper, we evaluate the performance of the Graph-based Transform (GBT) within the context of block based predictive transform coding. To this end, we introduce a novel framework that eliminates the need to signal graph information to the decoder to recover the coefficients. This is accomplished by computing the GBT using predicted residual blocks, which are predicted by a modelling approach that employs only the reference samples and information about the prediction mode. Evaluation results on several pathology images, in terms of the energy preserved and Mean Squared Error when a small percentage of the largest coefficients are used for reconstruction, show that the GBT can outperform the Discrete Sine Transform and Discrete Cosine Transform.
Deep Learning for Classification and Localization of Tumor Cells
by Saad Bashir
The gold standard for cancer diagnosis in pathology is by analysing morphological and statistical features of cells and tissue structure in Haematoxylin and Eosin (H&E) stained glass slides under microscope. In practice, diagnosing cancer requires a lot of time as there are thousands of cells in each WSI and there exist an inter- and intra- observer variability in grading. With the advent of whole slide images, automated analysis of these standard practices using computational pathology has been made possible. However, accuracy, objective quantification and manual labelling for these methods are still ongoing challenges because it’s very hard to accurately label all WSIs for multiple classes by a single pathologist. In this regard, we have explored new ways of grading different tissue types with the help of architectural and cytological digital biomarkers using statistical, morphometrical and spatial analysis, and moved from supervised paradigm to semi-supervised paradigm for tissue classification and localization purposes.
Applying Augmented Reality (AR) Technology in Computing Higher Education.
by Sarah Alshamrani
I am applying Augmented Reality tools to computer science classes. I am doing an exploratory study as part of design science research methodology to investigate the requirements and acceptance of students and lecturers to use the system. A pilot study has been completed, semi structured interviews have been conducted with lecturers and an online survey has been sent to students (as a replacement of a focus group due to current circumstances). Analyzing the data will be my next step, where I will be using content thematic analysis.
Application of scoping review protocol to the emerging literature on telemedicine adoption during the COVID-19 pandemic
by Daniela Valdes
Scoping reviews are a useful way of identifying gaps in the literature while focusing on qualitative elements related to the context of healthcare delivery. This presentation provides a reflection of the potential challenges for new Postgraduate Researchers in applying standard scoping review protocols in the context of emerging literature related to the COVID-19 pandemic. The presentation will briefly cover (i) the scoping review methodology from the JBI Manual for Evidence Synthesis (Aromataris and Munn, Chapter 11, 2020); (ii) the application of said methodology in the context of a review question on the adoption of telemedicine during the early stages of the COVID-19 pandemic; (iii) discussion around potential challenges for new Postgraduate Researchers.